shell及Python爬虫实例展示
Posted 魔降风云变
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell及Python爬虫实例展示相关的知识,希望对你有一定的参考价值。
1.shell爬虫实例:
[root@db01 ~]# vim pa.sh
#!/bin/bash
www_link=http://www.cnblogs.com/clsn/default.html?page=
for i in {1..8}
do
a=`curl ${www_link}${i} 2>/dev/null|grep homepage|grep -v "ImageLink"|awk -F "[><\\"]" \'{print $7"@"$9}\' >>bb.txt`#@为自己
指定的分隔符.这行是获取内容及内容网址
done
egrep -v "pager" bb.txt >ma.txt #将处理后,只剩内容和内容网址的放在一个文件里
b=`sed "s# ##g" ma.txt` #将文件里的空格去掉,因为for循环会将每行的空格前后作为两个变量,而不是一行为一个变量,这个坑花
了我好长时间。
for i in $b
do
c=`echo $i|awk -F @ \'{print $1}\'` #c=内容网址
d=`echo $i|awk -F @ \'{print $2}\'` #d=内容
echo "<a href=\'${c}\' target=\'_blank\'>${d}</a> " >>cc.txt #cc.txt为生成a标签的文本
done
爬虫结果显示:归档文件中惨绿少年的爬虫结果
注意:爬取结果放入博客应在a标签后加 的空格符或其他,博客园默认不显示字符串
的空格符或其他,博客园默认不显示字符串
2、
2.1Python爬虫学习
爬取这个网页
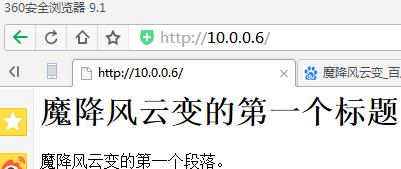
import urllib.request # 网址 url = "http://10.0.0.6/" # 请求 request = urllib.request.Request(url) # 爬取结果 response = urllib.request.urlopen(request) data = response.read() # 设置解码方式 data = data.decode(\'utf-8\') # 打印结果 print(data)
结果:
E:\\python\\python\\python.exe C:/python/day2/test.py <html> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> <body> <h1>魔降风云变的第一个标题</h1> <p>魔降风云变的第一个段落。</p> </body> </html>
print(type(response))
结果:
<class \'http.client.HTTPResponse\'>
print(response.geturl())
结果:
http://10.0.0.6/
print(response.info())
结果:
Server: nginx/1.12.2 Date: Fri, 02 Mar 2018 07:45:11 GMT Content-Type: text/html Content-Length: 184 Last-Modified: Fri, 02 Mar 2018 07:38:00 GMT Connection: close ETag: "5a98ff58-b8" Accept-Ranges: bytes
print(response.getcode())
结果:
200
2.2爬取网页代码并保存到电脑文件
import urllib.request
# 网址
url = "http://10.0.0.6/"
headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/51.0.2704.63 Safari/537.36\'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
data = data.decode(\'utf-8\')
# 打印抓取的内容
print(data)
结果:
<html> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> <body> <h1>魔降风云变的第一个标题</h1> <p>魔降风云变的第一个段落。</p> </body> </html>
import urllib.request # 定义保存函数 def saveFile(data): #------------------------------------------ path = "E:\\\\content.txt" f = open(path, \'wb\') f.write(data) f.close() #------------------------------------------ # 网址 url = "http://10.0.0.6/" headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/51.0.2704.63 Safari/537.36\'} req = urllib.request.Request(url=url, headers=headers) res = urllib.request.urlopen(req) data = res.read() # 也可以把爬取的内容保存到文件中 saveFile(data) #****************************************** data = data.decode(\'utf-8\') # 打印抓取的内容 print(data)
添加保存文件的函数并执行的结果:

# # 打印爬取网页的各类信息 print(type(res)) print(res.geturl()) print(res.info()) print(res.getcode())
结果:
<class \'http.client.HTTPResponse\'> http://10.0.0.6/ Server: nginx/1.12.2 Date: Fri, 02 Mar 2018 08:09:56 GMT Content-Type: text/html Content-Length: 184 Last-Modified: Fri, 02 Mar 2018 07:38:00 GMT Connection: close ETag: "5a98ff58-b8" Accept-Ranges: bytes 200
2.3爬取图片
import urllib.request, socket, re, sys, os
# 定义文件保存路径
targetPath = "E:\\\\"
def saveFile(path):
# 检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath)
# 设置每个图片的路径
pos = path.rindex(\'/\')
t = os.path.join(targetPath, path[pos + 1:])
return t
# 用if __name__ == \'__main__\'来判断是否是在直接运行该.py文件
# 网址
url = "http://10.0.0.6/"
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/51.0.2704.63 Safari/537.36\'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
print(data)
for link, t in set(re.findall(r\'(http:[^s]*?(jpg|png|gif))\', str(data))):
print(link)
try:
urllib.request.urlretrieve(link, saveFile(link))
except:
print(\'失败\')
2.31
import urllib.request, socket, re, sys, os
url = "http://10.0.0.6/"
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/51.0.2704.63 Safari/537.36\'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
print(req)
print(res)
print(data)
print(str(data))
结果:
<urllib.request.Request object at 0x0000000001ECD9E8> <http.client.HTTPResponse object at 0x0000000002D1B128> b\'<html>\\n<meta http-equiv="Content-Type" content="text/html;charset=utf-8">\\n<body>\\n<img src="http://10.0.0.6/ma1.png" />\\n<img src="http://10.0.0.6/ma2.jpg" />\\n<h1>\\xe9\\xad\\x94\\xe9\\x99\\x8d\\xe9\\xa3\\x8e\\xe4\\xba\\x91\\xe5\\x8f\\x98\\xe7\\x9a\\x84\\xe7\\xac\\xac\\xe4\\xb8\\x80\\xe4\\xb8\\xaa\\xe6\\xa0\\x87\\xe9\\xa2\\x98</h1>\\n<p>\\xe9\\xad\\x94\\xe9\\x99\\x8d\\xe9\\xa3\\x8e\\xe4\\xba\\x91\\xe5\\x8f\\x98\\xe7\\x9a\\x84\\xe7\\xac\\xac\\xe4\\xb8\\x80\\xe4\\xb8\\xaa\\xe6\\xae\\xb5\\xe8\\x90\\xbd\\xe3\\x80\\x82</p>\\n</body>\\n</html>\\n\' b\'<html>\\n<meta http-equiv="Content-Type" content="text/html;charset=utf-8">\\n<body>\\n<img src="http://10.0.0.6/ma1.png" />\\n<img src="http://10.0.0.6/ma2.jpg" />\\n<h1>\\xe9\\xad\\x94\\xe9\\x99\\x8d\\xe9\\xa3\\x8e\\xe4\\xba\\x91\\xe5\\x8f\\x98\\xe7\\x9a\\x84\\xe7\\xac\\xac\\xe4\\xb8\\x80\\xe4\\xb8\\xaa\\xe6\\xa0\\x87\\xe9\\xa2\\x98</h1>\\n<p>\\xe9\\xad\\x94\\xe9\\x99\\x8d\\xe9\\xa3\\x8e\\xe4\\xba\\x91\\xe5\\x8f\\x98\\xe7\\x9a\\x84\\xe7\\xac\\xac\\xe4\\xb8\\x80\\xe4\\xb8\\xaa\\xe6\\xae\\xb5\\xe8\\x90\\xbd\\xe3\\x80\\x82</p>\\n</body>\\n</html>\\n\'
2.32
import urllib.request, socket, re, sys, os
url = "http://10.0.0.6/"
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/51.0.2704.63 Safari/537.36\'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
for link in set(re.findall(r\'(http:[^s]*?(jpg|png|gif))\', str(data))):
print(link)
结果:
(\'http://10.0.0.6/ma2.jpg\', \'jpg\') (\'http://10.0.0.6/ma1.png\', \'png\')
2.33
for link,t in set(re.findall(r\'(http:[^s]*?(jpg|png|gif))\', str(data))):
print(link)
结果:
http://10.0.0.6/ma1.png http://10.0.0.6/ma2.jpg
2.34
import urllib.request, socket, re, sys, os
# 定义文件保存路径
targetPath = "E:\\\\"
def saveFile(path):
# 检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath)
# 设置每个图片的路径
pos = path.rindex(\'/\')
t = os.path.join(targetPath, path[pos + 1:])
return t
# 用if __name__ == \'__main__\'来判断是否是在直接运行该.py文件
# 网址
url = "http://10.0.0.6/"
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/51.0.2704.63 Safari/537.36\'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
for link,t in set(re.findall(r\'(http:[^s]*?(jpg|png|gif))\', str(data))):
print(link)
try:
urllib.request.urlretrieve(link, saveFile(link))
except:
print(\'失败\')
结果:
http://10.0.0.6/ma2.jpg http://10.0.0.6/ma1.png

2.4登录知乎

参考:http://blog.csdn.net/fly_yr/article/details/51535676
以上是关于shell及Python爬虫实例展示的主要内容,如果未能解决你的问题,请参考以下文章