第1章 python并发编程之多线程
1.1 死锁现象与递归锁
1.1.1 死锁概念
进程也有死锁与递归锁,在进程那里忘记说了,放到这里一切说了额
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
1.1.2 博客实例
from threading import Thread,Lock
import time
mutexA=Lock()
mutexB=Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(‘\\033[41m%s 拿到A锁\\033[0m‘ %self.name)
mutexB.acquire()
print(‘\\033[42m%s 拿到B锁\\033[0m‘ %self.name)
mutexB.release()
mutexA.release()
def func2(self):
mutexB.acquire()
print(‘\\033[43m%s 拿到B锁\\033[0m‘ %self.name)
time.sleep(2)
mutexA.acquire()
print(‘\\033[44m%s 拿到A锁\\033[0m‘ %self.name)
mutexA.release()
mutexB.release()
if __name__ == ‘__main__‘:
for i in range(10):
t=MyThread()
t.start()
‘‘‘
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁
Thread-2 拿到A锁
然后就卡住,死锁了
‘‘‘
1.1.3 课堂实例
from threading import Thread,Lock,RLock
import time
# mutexA=Lock()
# mutexB=Lock()
mutexA=mutexB=RLock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print(‘%s 拿到了A锁‘ %self.name)
mutexB.acquire()
print(‘%s 拿到了B锁‘ % self.name)
mutexB.release() #1
mutexA.release() #0
def f2(self):
mutexB.acquire()
print(‘%s 拿到了B锁‘ % self.name)
time.sleep(0.1)
mutexA.acquire()
print(‘%s 拿到了A锁‘ % self.name)
mutexA.release()
mutexB.release()
if __name__ == ‘__main__‘:
for i in range(10):
t=MyThread()
t.start()
1.1.4 死锁解决方法
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
1.2 信号量Semaphore
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
1.2.1 博客实例
from threading import Thread,Semaphore
import threading
import time
# def func():
# if sm.acquire():
# print (threading.currentThread().getName() + ‘ get semaphore‘)
# time.sleep(2)
# sm.release()
def func():
sm.acquire()
print(‘%s get sm‘ %threading.current_thread().getName())
time.sleep(3)
sm.release()
if __name__ == ‘__main__‘:
sm=Semaphore(5)
for i in range(23):
t=Thread(target=func)
t.start()
1.2.2 课堂实例
from threading import Thread,Semaphore,current_thread
import time,random
sm=Semaphore(5)
def task():
with sm:
print(‘%s is laing‘ %current_thread().getName())
time.sleep(random.randint(1,3))
if __name__ == ‘__main__‘:
for i in range(20):
t=Thread(target=task)
t.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,不会产生新的,而信号量是产生一堆线程/进程
互斥锁与信号量推荐博客:http://url.cn/5DMsS9r
1.3 Event事件
同进程的一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
1.3.1 event参数
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
1.3.2 博客实例
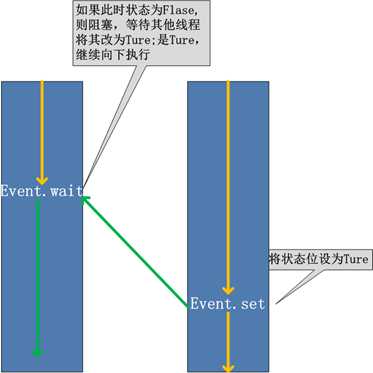
例如,有多个工作线程尝试链接MySQL,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作
from threading import Thread,Event
import threading
import time,random
def conn_mysql():
count=1
while not event.is_set():
if count > 3:
raise TimeoutError(‘链接超时‘)
print(‘<%s>第%s次尝试链接‘ % (threading.current_thread().getName(), count))
event.wait(0.5)
count+=1
print(‘<%s>链接成功‘ %threading.current_thread().getName())
def check_mysql():
print(‘\\033[45m[%s]正在检查mysql\\033[0m‘ % threading.current_thread().getName())
time.sleep(random.randint(2,4))
event.set()
if __name__ == ‘__main__‘:
event=Event()
conn1=Thread(target=conn_mysql)
conn2=Thread(target=conn_mysql)
check=Thread(target=check_mysql)
conn1.start()
conn2.start()
check.start()
1.3.3 课堂实例
from threading import Thread,Event,current_thread
import time
event=Event()
def check():
print(‘checking MySQL...‘)
time.sleep(5)
event.set()
def conn():
count=1
while not event.is_set():
if count > 3:
raise TimeoutError(‘超时‘)
print(‘%s try to connect MySQL time %s‘ %(current_thread().getName(),count))
event.wait(2)
count+=1
print(‘%s connected MySQL‘ %current_thread().getName())
if __name__ == ‘__main__‘:
t1=Thread(target=check)
t2=Thread(target=conn)
t3=Thread(target=conn)
t4=Thread(target=conn)
t1.start()
t2.start()
t3.start()
t4.start()
1.4 定时器
定时器,指定n秒后执行某操作
1.4.1 实例
from threading import Timer
def hello():
print("hello, world")
t = Timer(1, hello)
t.start() # after 1 seconds, "hello, world" will be printed
1.4.2 验证码定时器实例
from threading import Timer
import random,time
class Code:
def __init__(self):
self.make_cache()
def make_cache(self,interval=5):
self.cache=self.make_code()
print(self.cache)
self.t=Timer(interval,self.make_cache)
self.t.start()
def make_code(self,n=4):
res=‘‘
for i in range(n):
s1=str(random.randint(0,9))
s2=chr(random.randint(65,90))
res+=random.choice([s1,s2])
return res
def check(self):
while True:
inp=input(‘>>: ‘).strip()
if inp.upper() == self.cache:
print(‘验证成功‘,end=‘\\n‘)
self.t.cancel()
break
if __name__ == ‘__main__‘:
obj=Code()
obj.check()
1.5 线程queue队列
queue队列 :使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1.5.1 先进先出class queue.Queue(maxsize=0)
import queue
q=queue.Queue()
q.put(‘first‘)
q.put(‘second‘)
q.put(‘third‘)
print(q.get())
print(q.get())
print(q.get())
‘‘‘
结果(先进先出):
first
second
third
‘‘‘
1.5.2 堆栈(后进先出)class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue
q=queue.LifoQueue()
q.put(‘first‘)
q.put(‘second‘)
q.put(‘third‘)
print(q.get())
print(q.get())
print(q.get())
‘‘‘
结果(后进先出):
third
second
first
‘‘‘
1.5.3 优先级队列class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue
q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,‘a‘))
q.put((10,‘b‘))
q.put((30,‘c‘))
print(q.get())
print(q.get())
print(q.get())
‘‘‘
结果(数字越小优先级越高,优先级高的优先出队):
(10, ‘b‘)
(20, ‘a‘)
(30, ‘c‘)
‘‘‘
1.5.4 课堂讲解实例
import queue
# q=queue.Queue(3) #队列:先进先出
#
# q.put(1)
# q.put(2)
# q.put(3)
# # q.put(4)
# # q.put_nowait(4)
# # q.put(4,block=False)
# q.put(4,block=True,timeout=3)
#
#
# # print(q.get())
# # print(q.get())
# # print(q.get())
# q=queue.LifoQueue(3) #堆栈:后进先出
# q.put(1)
# q.put(2)
# q.put(3)
#
# print(q.get())
# print(q.get())
# print(q.get())
q=queue.PriorityQueue(3) #优先级队列
q.put((10,‘a‘))
q.put((-3,‘b‘))
q.put((100,‘c‘))
print(q.get())
print(q.get())
print(q.get())
1.6 Python标准模块--concurrent.futures进程池与线程池
1.6.1 提交任务的两种方式:
#同步调用:提交完任务后,就在原地等待,等待任务执行完毕,拿到任务的返回值,才能继续下一行代码,导致程序串行执行
#异步调用+回调机制:提交完任务后,不在原地等待,任务一旦执行完毕就会触发回调函数的执行, 程序是并发执行
1.6.2 进程的执行状态:
#阻塞
#非阻塞
1.6.3 concurrent.futures
#1 介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
#2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务
#map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
#shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
#result(timeout=None)
取得结果
#add_done_callback(fn)
回调函数
1.6.4 相关实例
################ProcessPoolExecutor#############
#介绍
The ProcessPoolExecutor class is an Executor subclass that uses a pool of processes to execute calls asynchronously. ProcessPoolExecutor uses the multiprocessing module, which allows it to side-step the Global Interpreter Lock but also means that only picklable objects can be executed and returned.
class concurrent.futures.ProcessPoolExecutor(max_workers=None, mp_context=None)
An Executor subclass that executes calls asynchronously using a pool of at most max_workers processes. If max_workers is None or not given, it will default to the number of processors on the machine. If max_workers is lower or equal to 0, then a ValueError will be raised.
#用法
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print(‘%s is runing‘ %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == ‘__main__‘:
executor=ProcessPoolExecutor(max_workers=3)
futures=[]
for i in range(11):
future=executor.submit(task,i)
futures.append(future)
executor.shutdown(True)
print(‘+++>‘)
for future in futures:
print(future.result())
#######################ThreadPoolExecutor######################
#介绍
ThreadPoolExecutor is an Executor subclass that uses a pool of threads to execute calls asynchronously.
class concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix=‘‘)
An Executor subclass that uses a pool of at most max_workers threads to execute calls asynchronously.
Changed in version 3.5: If max_workers is None or not given, it will default to the number of processors on the machine, multiplied by 5, assuming that ThreadPoolExecutor is often used to overlap I/O instead of CPU work and the number of workers should be higher than the number of workers for ProcessPoolExecutor.
New in version 3.6: The thread_name_prefix argument was added to allow users to control the threading.Thread names for worker threads created by the pool for easier debugging.
#用法
与ProcessPoolExecutor相同
###########################map的用法########################
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print(‘%s is runing‘ %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == ‘__main__‘:
executor=ThreadPoolExecutor(max_workers=3)
# for i in range(11):
# future=executor.submit(task,i)
executor.map(task,range(1,12)) #map取代了for+submit
#######################回调函数####################
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool
import requests
import json
import os
def get_page(url):
print(‘<进程%s> get %s‘ %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {‘url‘:url,‘text‘:respone.text}
def parse_page(res):
res=res.result()
print(‘<进程%s> parse %s‘ %(os.getpid(),res[‘url‘]))
parse_res=‘url:<%s> size:[%s]\\n‘ %(res[‘url‘],len(res[‘text‘]))
with open(‘db.txt‘,‘a‘) as f:
f.write(parse_res)
if __name__ == ‘__main__‘:
urls=[
‘https://www.baidu.com‘,
‘https://www.python.org‘,
‘https://www.openstack.org‘,
‘https://help.github.com/‘,
‘http://www.sina.com.cn/‘
]
# p=Pool(3)
# for url in urls:
# p.apply_async(get_page,args=(url,),callback=pasrse_page)
# p.close()
# p.join()
p=ProcessPoolExecutor(3)
for url in urls:
p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
1.6.5 进程池ThreadPoolExecutor
# #同步调用示例:
# # from multiprocessing import Pool
# from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# import time,random,os
#
# def task(n):
# print(‘%s is ruuning‘ %os.getpid())
# time.sleep(random.randint(1,3))
# return n**2
#
# def handle(res):
# print(‘handle res %s‘ %res)
#
# if __name__ == ‘__main__‘:
# #同步调用
# pool=ProcessPoolExecutor(2)
#
# for i in range(5):
# res=pool.submit(task,i).result()
# # print(res)
# handle(res)
#
# pool.shutdown(wait=True)
# # pool.submit(task,33333)
# print(‘主‘)
#异步调用示例:
# from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# import time,random,os
#
# def task(n):
# print(‘%s is ruuning‘ %os.getpid())
# time.sleep(random.randint(1,3))
# # res=n**2
# # handle(res)
# return n**2
#
# def handle(res):
# res=res.result()
# print(‘handle res %s‘ %res)
#
# if __name__ == ‘__main__‘:
# #异步调用
# pool=ProcessPoolExecutor(2)
#
# for i in range(5):
# obj=pool.submit(task,i)
# obj.add_done_callback(handle) #handle(obj)
#
# pool.shutdown(wait=True)
# print(‘主‘)
1.6.6 线程池ProcessPoolExecutor
#线程池
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import requests
import time
def get(url):
print(‘%s GET %s‘ %(current_thread().getName(),url))
response=requests.get(url)
time.sleep(2)
if response.status_code == 200:
return {‘url‘:url,‘content‘:response.text}
def parse(res):
res=res.result()
print(‘parse:[%s] res:[%s]‘ %(res[‘url‘],len(res[‘content‘])))
if __name__ == ‘__main__‘:
pool=ThreadPoolExecutor(2)
urls=[
‘https://www.baidu.com‘,
‘https://www.python.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
‘https://www.openstack.org‘,
]
for url in urls:
pool.submit(get,url).add_done_callback(parse)
pool.shutdown(wait=True)
第2章 python并发编程之协程
2.1 引子
本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它
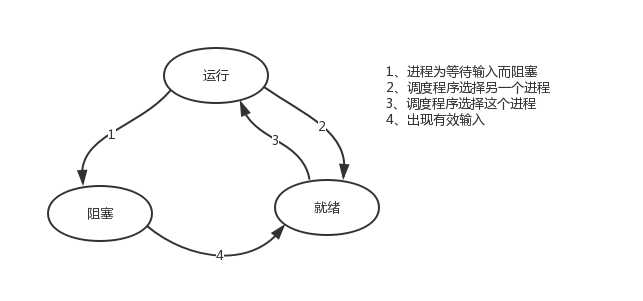
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
#1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级
#2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换
2.1.1 单纯地切换反而会降低运行效率
##############单纯地切换反而会降低运行效率######################
#串行执行
import time
def consumer(res):
‘‘‘任务1:接收数据,处理数据‘‘‘
pass
def producer():
‘‘‘任务2:生产数据‘‘‘
res=[]
for i in range(10000000):
res.append(i)
return res
start=time.time()
#串行执行
res=producer()
consumer(res) #写成consumer(producer())会降低执行效率
stop=time.time()
print(stop-start) #1.5536692142486572
#基于yield并发执行
import time
def consumer():
‘‘‘任务1:接收数据,处理数据‘‘‘
while True:
x=yield
def producer():
‘‘‘任务2:生产数据‘‘‘
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
start=time.time()
#基于yield保存状态,实现两个任务直接来回切换,即并发的效果
#PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.
producer()
stop=time.time()
print(stop-start) #2.0272178649902344
2.1.2 yield并不能实现遇到io切换
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
################yield并不能实现遇到io切换####################
import time
def consumer():
‘‘‘任务1:接收数据,处理数据‘‘‘
while True:
x=yield
def producer():
‘‘‘任务2:生产数据‘‘‘
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
time.sleep(2)
start=time.time()
producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行
stop=time.time()
print(stop-start)
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
#1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
#2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
2.1.3 课堂实例
# 单纯地切换反而会降低运行效率
#串行执行
# import time
# def consumer(res):
# ‘‘‘任务1:接收数据,处理数据‘‘‘
# pass
#
# def producer():
# ‘‘‘任务2:生产数据‘‘‘
# res=[]
# for i in range(10000000):
# res.append(i)
# return res
#
# start=time.time()
# #串行执行
# res=producer()
# consumer(res)
# stop=time.time()
# print(stop-start)
#基于yield并发执行
import time
def consumer():
‘‘‘任务1:接收数据,处理数据‘‘‘
while True:
print(‘consumer‘)
x=yield
time.sleep(100)
def producer():
‘‘‘任务2:生产数据‘‘‘
g=consumer()
next(g)
for i in range(10000000):
print(‘producer‘)
g.send(i)
start=time.time()
#基于yield保存状态,实现两个任务直接来回切换,即并发的效果
#PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.
producer()
stop=time.time()
print(stop-start) #
2.2 协程介绍
2.2.1 协程概念
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
2.2.2 强调
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
2.2.3 优缺点
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
2.2.4 总结
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
2.3 Greenlet
2.3.1 博客实例
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
#安装
pip3 install greenlet
from greenlet import greenlet
def eat(name):
print(‘%s eat 1‘ %name)
g2.switch(‘egon‘)
print(‘%s eat 2‘ %name)
g2.switch()
def play(name):
print(‘%s play 1‘ %name)
g1.switch()
print(‘%s play 2‘ %name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch(‘egon‘)#可以在第一次switch时传入参数,以后都不需要
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
#顺序执行
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print(‘run time is %s‘ %(stop-start)) #10.985628366470337
#切换
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print(‘run time is %s‘ %(stop-start)) # 52.763017892837524
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
2.3.2 课堂实例
#pip3 install greenlet
from greenlet import greenlet
import time
def eat(name):
print(‘%s eat 1‘ %name)
time.sleep(1000)
g2.switch(‘egon‘)
print(‘%s eat 2‘ %name)
g2.switch()
def play(name):
print(‘%s play 1‘ % name)
g1.switch()
print(‘%s play 2‘ % name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch(‘egon‘)
2.4 Gevent介绍
#安装
pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
2.4.1 用法
#用法
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
g2=gevent.spawn(func2)
g1.join() #等待g1结束
g2.join() #等待g2结束
#或者上述两步合作一步:gevent.joinall([g1,g2])
g1.value#拿到func1的返回值
2.4.2 遇到IO阻塞时会自动切换任务
import gevent
def eat(name):
print(‘%s eat 1‘ %name)
gevent.sleep(2)
print(‘%s eat 2‘ %name)
def play(name):
print(‘%s play 1‘ %name)
gevent.sleep(1)
print(‘%s play 2‘ %name)
g1=gevent.spawn(eat,‘egon‘)
g2=gevent.spawn(play,name=‘egon‘)
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print(‘主‘)
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头。
from gevent import monkey;monkey.patch_all()
import gevent
import time
def eat():
print(‘eat food 1‘)
time.sleep(2)
print(‘eat food 2‘)
def play():
print(‘play 1‘)
time.sleep(1)
print(‘play 2‘)
g1=gevent.spawn(eat)
g2=gevent.spawn(play_phone)
gevent.joinall([g1,g2])
print(‘主‘)
我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程。
2.4.3 课堂实例
from gevent import monkey;monkey.patch_all()
import gevent
import time
def eat(name):
print(‘%s eat 1‘ %name)
# gevent.sleep(3)
time.sleep(3)
print(‘%s eat 2‘ %name)
def play(name):
print(‘%s play 1‘ % name)
# gevent.sleep(2)
time.sleep(3)
print(‘%s play 2‘ % name)
g1=gevent.spawn(eat,‘egon‘)
g2=gevent.spawn(play,‘alex‘)
# gevent.sleep(1)
# g1.join()
# g2.join()
gevent.joinall([g1,g2])
2.5 Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print(‘Task %s done‘ % pid)
def synchronous():
for i in range(10):
task(i)
def asynchronous():
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
if __name__ == ‘__main__‘:
print(‘Synchronous:‘)
synchronous()
print(‘Asynchronous:‘)
asynchronous()
#上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
2.6 Gevent之应用举例一
##########################协程应用:爬虫############################3
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print(‘GET: %s‘ %url)
response=requests.get(url)
if response.status_code == 200:
print(‘%d bytes received from %s‘ %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,‘https://www.python.org/‘),
gevent.spawn(get_page,‘https://www.yahoo.com/‘),
gevent.spawn(get_page,‘https://github.com/‘),
])
stop_time=time.time()
print(‘run time is %s‘ %(stop_time-start_time))
2.7 Gevent之应用举例二
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
2.7.1 服务端
####################服务端#####################
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
#如果不想用money.patch_all()打补丁,可以用gevent自带的socket
# from gevent import socket
# s=socket.socket()
def server(server_ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((server_ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
print(‘client %s:%s msg: %s‘ %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == ‘__main__‘:
server(‘127.0.0.1‘,8080)
2.7.2 客户端
##################客户端###################
#_*_coding:utf-8_*_
__author__ = ‘Linhaifeng‘
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect((‘127.0.0.1‘,8080))
while True:
msg=input(‘>>: ‘).strip()
if not msg:continue
client.send(msg.encode(‘utf-8‘))
msg=client.recv(1024)
print(msg.decode(‘utf-8‘))
2.7.3 多线程并发多个客户端
########################多线程并发多个客户端##########################
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了
c.connect((server_ip,port))
count=0
while True:
c.send((‘%s say hello %s‘ %(threading.current_thread().getName(),count)).encode(‘utf-8‘))
msg=c.recv(1024)
print(msg.decode(‘utf-8‘))
count+=1
if __name__ == ‘__main__‘:
for i in range(500):
t=Thread(target=client,args=(‘127.0.0.1‘,8080))
t.start()
2.8 课堂讲解练习
2.8.1 服务端
from gevent import monkey,spawn;monkey.patch_all()
from threading import current_thread
from socket import *
def comunicate(conn):
print(‘子线程:%s‘ %current_thread().getName())
while True:
try:
data=conn.recv(1024)
if not data:break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
def server(ip,port):
print(‘主线程:%s‘ %current_thread().getName())
server = socket(AF_INET, SOCK_STREAM)
server.bind((ip,port))
server.listen(5)
while True:
conn, addr = server.accept()
print(addr)
# comunicate(conn)
# t=Thread(target=comunicate,args=(conn,))
# t.start()
spawn(comunicate,conn)
server.close()
if __name__ == ‘__main__‘:
g=spawn(server,‘127.0.0.1‘, 8081)
g.join()
2.8.2 客户端
from socket import *
from threading import current_thread,Thread
def client():
client=socket(AF_INET,SOCK_STREAM)
client.connect((‘127.0.0.1‘,8081))
while True:
client.send((‘%s say hello‘ %current_thread().getName()).encode(‘utf-8‘))
data=client.recv(1024)
print(data.decode(‘utf-8‘))
client.close()
if __name__ == ‘__main__‘:
for i in range(500):
t=Thread(target=client)
t.start()
第3章 mysql一:初识数据库
3.1 数据库管理软件的由来
基于我们之前所学,数据要想永久保存,都是保存于文件中,毫无疑问,一个文件仅仅只能存在于某一台机器上。
如果我们暂且忽略直接基于文件来存取数据的效率问题,并且假设程序所有的组件都运行在一台机器上,那么用文件存取数据,并没有问题。
很不幸,这些假设都是你自己意淫出来的,上述假设存在以下几个问题。。。。。。
3.1.1 程序所有的组件就不可能运行在一台机器上
#因为这台机器一旦挂掉则意味着整个软件的崩溃,并且程序的执行效率依赖于承载它的硬件,而一台机器机器的性能总归是有限的,受限于目前的硬件水平,就一台机器的性能垂直进行扩展是有极限的。
#于是我们只能通过水平扩展来增强我们系统的整体性能,这就需要我们将程序的各个组件分布于多台机器去执行。
3.1.2 数据安全问题
#根据1的描述,我们将程序的各个组件分布到各台机器,但需知各组件仍然是一个整体,言外之意,所有组件的数据还是要共享的。但每台机器上的组件都只能操作本机的文件,这就导致了数据必然不一致。
#于是我们想到了将数据与应用程序分离:把文件存放于一台机器,然后将多台机器通过网络去访问这台机器上的文件(用socket实现),即共享这台机器上的文件,共享则意味着竞争,会发生数据不安全,需要加锁处理。。。。
3.1.3 并发
根据2的描述,我们必须写一个socket服务端来管理这台机器(数据库服务器)上的文件,然后写一个socket客户端,完成如下功能:
#1.远程连接(支持并发)
#2.打开文件
#3.读写(加锁)
#4.关闭文件
3.1.4 总结:
#我们在编写任何程序之前,都需要事先写好基于网络操作一台主机上文件的程序(socket服务端与客户端程序),于是有人将此类程序写成一个专门的处理软件,这就是mysql等数据库管理软件的由来,但mysql解决的不仅仅是数据共享的问题,还有查询效率,安全性等一系列问题,总之,把程序员从数据管理中解脱出来,专注于自己的程序逻辑的编写。
3.2 数据库概述
3.2.1 什么是数据(Data)
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片,图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
egon,male,18,1999,山东,计算机系,2017,oldboy
单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思,相当于定义表的标题
name,sex,age,birth,born_addr,major,entrance_time,school #字段
egon,male,18,1999,山东,计算机系,2017,oldboy #记录
这样我们就可以了解egon,性别为男,年龄18岁,出生于1999年,出生地为山东,2017年考入老男孩计算机系
3.2.2 什么是数据库(DataBase,简称DB)
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用
数据库是长期存放在计算机内、有组织、可共享的数据即可。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种 用户共享
3.2.3 什么是数据库管理系统(DataBase Management System 简称DBMS)
在了解了Data与DB的概念后,如何科学地组织和存储数据,如何高效获取和维护数据成了关键
这就用到了一个系统软件---数据库管理系统
如MySQL、Oracle、SQLite、Access、MS SQL Server
mysql主要用于大型门户,例如搜狗、新浪等,它主要的优势就是开放源代码,因为开放源代码这个数据库是免费的,他现在是甲骨文公司的产品。
oracle主要用于银行、铁路、飞机场等。该数据库功能强大,软件费用高。也是甲骨文公司的产品。
sql server是微软公司的产品,主要应用于大中型企业,如联想、方正等。
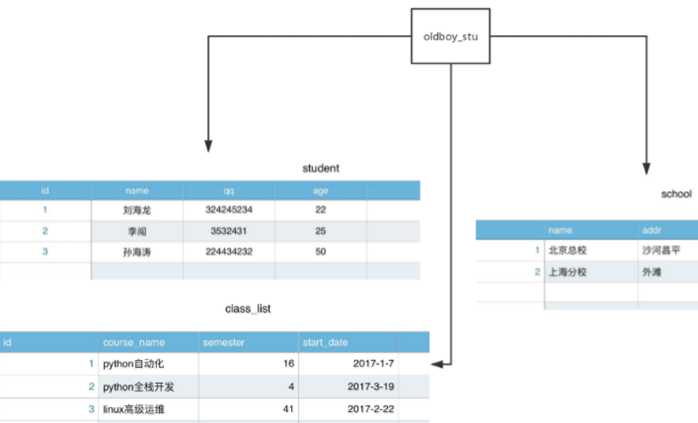
3.2.4 数据库服务器、数据管理系统、数据库、表与记录的关系(重点理解!!!)
记录:1 刘海龙 324245234 22(多个字段的信息组成一条记录,即文件中的一行内容)
表:student,scholl,class_list(即文件)
数据库:oldboy_stu(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
数据库服务器-:运行数据库管理软件
数据库管理软件:管理-数据库
数据库:即文件夹,用来组织文件/表
表:即文件,用来存放多行内容/多条记录
3.3 mysql介绍
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
3.3.1 mysql是什么
#mysql就是一个基于socket编写的C/S架构的软件
#客户端软件
mysql自带:如mysql命令,mysqldump命令等
python模块:如pymysql
3.3.2 数据库管理软件分类
#分两大类:
关系型:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用
非关系型:mongodb,redis,memcache
#可以简单的理解为:
关系型数据库需要有表结构
非关系型数据库是key-value存储的,没有表结构
3.4 下载安装
3.4.1 Linux版本
#二进制rpm包安装
yum -y install mysql-server mysql
########################源码安装mysql######################3
1.解压tar包
cd /software
tar -xzvf mysql-5.6.21-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.6.21-linux-glibc2.5-x86_64 mysql-5.6.21
2.添加用户与组
groupadd mysql
useradd -r -g mysql mysql
chown -R mysql:mysql mysql-5.6.21
3.安装数据库
su mysql
cd mysql-5.6.21/scripts
./mysql_install_db --user=mysql --basedir=/software/mysql-5.6.21 --datadir=/software/mysql-5.6.21/data
4.配置文件
cd /software/mysql-5.6.21/support-files
cp my-default.cnf /etc/my.cnf
cp mysql.server /etc/init.d/mysql
vim /etc/init.d/mysql #若mysql的安装目录是/usr/local/mysql,则可省略此步
修改文件中的两个变更值
basedir=/software/mysql-5.6.21
datadir=/software/mysql-5.6.21/data
5.配置环境变量
vim /etc/profile
export MYSQL_HOME="/software/mysql-5.6.21"
export PATH="$PATH:$MYSQL_HOME/bin"
source /etc/profile
6.添加自启动服务
chkconfig --add mysql
chkconfig mysql on
7.启动mysql
service mysql start
8.登录mysql及改密码与配置远程访问
mysqladmin -u root password ‘your_password‘ #修改root用户密码
mysql -u root -p #登录mysql,需要输入密码
mysql>GRANT ALL PRIVILEGES ON *.* TO ‘root‘@‘%‘ IDENTIFIED BY ‘your_password‘ WITH GRANT OPTION; #允许root用户远程访问
mysql>FLUSH PRIVILEGES; #刷新权限
###########################源码安装mariadb####################3
1. 解压
tar zxvf mariadb-5.5.31-linux-x86_64.tar.gz
mv mariadb-5.5.31-linux-x86_64 /usr/local/mysql //必需这样,很多脚本或可执行程序都会直接访问这个目录
2. 权限
groupadd mysql //增加 mysql 属组
useradd -g mysql mysql //增加 mysql 用户 并归于mysql 属组
chown mysql:mysql -Rf /usr/local/mysql // 设置 mysql 目录的用户及用户组归属。
chmod +x -Rf /usr/local/mysql //赐予可执行权限
3. 拷贝配置文件
cp /usr/local/mysql/support-files/my-medium.cnf /etc/my.cnf //复制默认mysql配置 文件到/etc目录
4. 初始化
/usr/local/mysql/scripts/mysql_install_db --user=mysql //初始化数据库
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql //复制mysql服务程序 到系统目录
chkconfig mysql on //添加mysql 至系统服务并设置为开机启动
service mysql start //启动mysql
5. 环境变量配置
vim /etc/profile //编辑profile,将mysql的可执行路径加入系统PATH
export PATH=/usr/local/mysql/bin:$PATH
source /etc/profile //使PATH生效。
6. 账号密码
mysqladmin -u root password ‘yourpassword‘ //设定root账号及密码
mysql -u root -p //使用root用户登录mysql
use mysql //切换至mysql数据库。
select user,host,password from user; //查看系统权限
drop user ‘‘@‘localhost‘; //删除不安全的账户
drop user [email protected]‘::1‘;
drop user [email protected];
select user,host,password from user; //再次查看系统权限,确保不安全的账户均被删除。
flush privileges; //刷新权限
7. 一些必要的初始配置
1)修改字符集为UTF8
vi /etc/my.cnf
在[client]下面添加 default-character-set = utf8
在[mysqld]下面添加 character_set_server = utf8
2)增加错误日志
vi /etc/my.cnf
在[mysqld]下面添加:
log-error = /usr/local/mysql/log/error.log
general-log-file = /usr/local/mysql/log/mysql.log
3) 设置为不区分大小写,linux下默认会区分大小写。
vi /etc/my.cnf
在[mysqld]下面添加:
lower_case_table_name=1
修改完重启:#service mysql restart
3.4.2 Window版本
#################################安装########################
#1、下载:MySQL Community Server 5.7.16
http://dev.mysql.com/downloads/mysql/
#2、解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\\mysql-5.7.16-winx64
#3、添加环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】
#4、初始化
mysqld --initialize-insecure
#5、启动MySQL服务
mysqld # 启动MySQL服务
#6、启动MySQL客户端并连接MySQL服务
mysql -u root -p # 连接MySQL服务器
######################将MySQL服务制作成windows服务#######################
上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题:
注意:--install前,必须用mysql启动命令的绝对路径
# 制作MySQL的Windows服务,在终端执行此命令:
"c:\\mysql-5.7.16-winx64\\bin\\mysqld" --install
# 移除MySQL的Windows服务,在终端执行此命令:
"c:\\mysql-5.7.16-winx64\\bin\\mysqld" --remove
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
# 启动MySQL服务
net start mysql
# 关闭MySQL服务
net stop mysql
3.5 mysql软件基本管理
3.5.1 启动查看
#################linux平台下查看###################
[[email protected] ~]# systemctl start mariadb #启动
[[email protected] ~]# systemctl enable mariadb #设置开机自启动
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
[[email protected] ~]# ps aux |grep mysqld |grep -v grep #查看进程,mysqld_safe为启动mysql的脚本文件,内部调用mysqld命令
mysql 3329 0.0 0.0 113252 1592 ? Ss 16:19 0:00 /bin/sh /usr/bin/mysqld_safe --basedir=/usr
mysql 3488 0.0 2.3 839276 90380 ? Sl 16:19 0:00 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log --pid-file=/var/run/mariadb/mariadb.pid --socket=/var/lib/mysql/mysql.sock
[[email protected] ~]# netstat -an |grep 3306 #查看端口
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
[[email protected] ~]# ll -d /var/lib/mysql #权限不对,启动不成功,注意user和group
drwxr-xr-x 5 mysql mysql 4096 Jul 20 16:28 /var/lib/mysql
#################You must reset your password using ALTER USER statement before executing this statement.################
安装完mysql 之后,登陆以后,不管运行任何命令,总是提示这个
mac mysql error You must reset your password using ALTER USER statement before executing this statement.
解决方法:
step 1: SET PASSWORD = PASSWORD(‘your new password‘);
step 2: ALTER USER ‘root‘@‘localhost‘ PASSWORD EXPIRE NEVER;
step 3: flush privileges;
3.5.2 登录,设置密码
初始状态下,管理员root,密码为空,默认只允许从本机登录localhost
设置密码
[[email protected] ~]# mysqladmin -uroot password "123" 设置初始密码 由于原密码为空,因此-p可以不用
[[email protected] ~]# mysqladmin -uroot -p"123" password "456" 修改mysql密码,因为已经有密码了,所以必须输入原密码才能设置新密码
命令格式:
[[email protected] ~]# mysql -h172.31.0.2 -uroot -p456
[[email protected] ~]# mysql -uroot -p
[[email protected] ~]# mysql 以root用户登录本机,密码为空
3.5.3 忘记密码
linux平台下,破解密码的两种方式
##################方法一:删除授权库mysql,重新初始化###################
[[email protected] ~]# rm -rf /var/lib/mysql/mysql #所有授权信息全部丢失!!!
[[email protected] ~]# systemctl restart mariadb
[[email protected] ~]# mysql
#############方法二:启动时,跳过授权库#############
[[email protected] ~]# vim /etc/my.cnf #mysql主配置文件
[mysqld]
skip-grant-table
[[email protected] ~]# systemctl restart mariadb
[[email protected] ~]# mysql
MariaDB [(none)]> update mysql.user set password=password("123") where user="root" and host="localhost";
MariaDB [(none)]> flush privileges;
MariaDB [(none)]> \\q
[[email protected] ~]# #打开/etc/my.cnf去掉skip-grant-table,然后重启
[[email protected] ~]# systemctl restart mariadb
[[email protected] ~]# mysql -u root -p123 #以新密码登录
windows平台下,5.7版本mysql,破解密码的两种方式:
####################方式一####################
#1 关闭mysql
#2 在cmd中执行:mysqld --skip-grant-tables
#3 在cmd中执行:mysql
#4 执行如下sql:
update mysql.user set authentication_string=password(‘‘) where user = ‘root‘;
flush privileges;
#5 tskill mysqld #或taskkill -f /PID 7832
#6 重新启动mysql
#######################方式二######################
#1. 关闭mysql,可以用tskill mysqld将其杀死
#2. 在解压目录下,新建mysql配置文件my.ini
#3. my.ini内容,指定
[mysqld]
skip-grant-tables
#4.启动mysqld
#5.在cmd里直接输入mysql登录,然后操作
update mysql.user set authentication_string=password(‘‘) where user=‘root and host=‘localhost‘;
flush privileges;
#6.注释my.ini中的skip-grant-tables,然后启动myqsld,然后就可以以新密码登录了
3.5.4 课堂讲解破解密码(windows下)
C:\\Users\\Administrator> mysqladmin -uroot -p password "123"
#重置密码
net stop MySQL
mysqld --skip-grant-tables
mysql -uroot -p
update mysql.user set password=password("") where user=‘root‘ and host="localhost";
flush privileges;
C:\\Users\\Administrator>tasklist |findstr mysql
mysqld.exe 6316 Console 1 454,544 K
C:\\Users\\Administrator>taskkill /F /PID 6316
成功: 已终止 PID 为 6316 的进程。
C:\\Users\\Administrator>net start MySQL
MySQL 服务正在启动 .
MySQL 服务已经启动成功。
3.5.5 在windows下,为mysql服务指定配置文件
强调:配置文件中的注释可以有中文,但是配置项中不能出现中文
#########################my.ini###########################
#在mysql的解压目录下,新建my.ini,然后配置
#1. 在执行mysqld命令时,下列配置会生效,即mysql服务启动时生效
[mysqld]
;skip-grant-tables
port=3306
character_set_server=utf8
default-storage-engine=innodb
innodb_file_per_table=1
#解压的目录
basedir=E:\\mysql-5.7.19-winx64
#data目录
datadir=E:\\my_data #在mysqld --initialize时,就会将初始数据存入此处指定的目录,在初始化之后,启动mysql时,就会去这个目录里找数据
#2. 针对客户端命令的全局配置,当mysql客户端命令执行时,下列配置生效
[client]
port=3306
default-character-set=utf8
user=root
password=123
#3. 只针对mysql这个客户端的配置,2中的是全局配置,而此处的则是只针对mysql这个命令的局部配置
[mysql]
;port=3306
;default-character-set=utf8
user=egon
password=4573
#!!!如果没有[mysql],则用户在执行mysql命令时的配置以[client]为准
3.5.6 统一字符编码
#1. 修改配置文件
[mysqld]
default-character-set=utf8
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#mysql5.5以上:修改方式有所改动
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#2. 重启服务
#3. 查看修改结果:
\\s
show variables like ‘%char%‘
3.6 初识sql语句
有了mysql这个数据库软件,就可以将程序员从对数据的管理中解脱出来,专注于对程序逻辑的编写
mysql服务端软件即mysqld帮我们管理好文件夹以及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用mysql软件规定的语法格式去提交自己命令,实现对文件夹或文件的管理。该语法即sql(Structured Query Language 即结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型:
#1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
#2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
#3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
#1. 操作文件夹
增:create database db1 charset utf8;
查:show databases;
改:alter database db1 charset latin1;
删除: drop database db1;
#2. 操作文件
先切换到文件夹下:use db1
增:create table t1(id int,name char);
查:show tables
改:alter table t1 modify name char(3);
alter table t1 change name name1 char(2);
删:drop table t1;
#3. 操作文件中的内容/记录
增:insert into t1 values(1,‘egon1‘),(2,‘egon2‘),(3,‘egon3‘);
查:select * from t1;
改:update t1 set name=‘sb‘ where id=2;
删:delete from t1 where id=1;
清空表:
delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。
truncate table t1;数据量大,删除速度比上一条快,且直接从零开始,
auto_increment 表示:自增
primary key 表示:约束(不能重复且不能为空);加速查找
第4章 mysql二:库操作
4.1 系统数据库
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
4.2 创建数据库
4.2.1 语法(help create database)
CREATE DATABASE 数据库名 charset utf8;
4.2.2 数据库命名规则:
可以由字母、数字、下划线、@、#、$
区分大小写
唯一性
不能使用关键字如 create select
不能单独使用数字
最长128位
4.3 数据库相关操作
1 查看数据库
show databases;
show create database db1;
select database();
2 选择数据库
USE 数据库名
3 删除数据库
DROP DATABASE 数据库名;
4 修改数据库
alter database db1 charset utf8;
第5章 mysql三:表操作
5.1 存储引擎介绍
mysql支持的存储引擎
MariaDB [(none)]> show engines\\G #查看所有支持的存储引擎
MariaDB [(none)]> show variables like ‘storage_engine%‘; #查看正在使用的存储引擎
5.2 使用存储引擎
5.2.1 方法1:建表时指定
MariaDB [db1]> create table innodb_t1(id int,name char)engine=innodb;
MariaDB [db1]> create table innodb_t2(id int)engine=innodb;
MariaDB [db1]> show create table innodb_t1;
MariaDB [db1]> show create table innodb_t2;
5.2.2 方法2:在配置文件中指定默认的存储引擎
/etc/my.cnf
[mysqld]
default-storage-engine=INNODB
innodb_file_per_table=1
5.2.3 查看
[[email protected] db1]# cd /var/lib/mysql/db1/
[[email protected] db1]# ls
db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
5.2.4 练习
创建四个表,分别使用innodb,myisam,memory,blackhole存储引擎,进行插入数据测试
MariaDB [db1]> create table t1(id int)engine=innodb;
MariaDB [db1]> create table t2(id int)engine=myisam;
MariaDB [db1]> create table t3(id int)engine=memory;
MariaDB [db1]> create table t4(id int)engine=blackhole;
MariaDB [db1]> quit
[[email protected] db1]# ls /var/lib/mysql/db1/ #发现后两种存储引擎只有表结构,无数据
db.opt t1.frm t1.ibd t2.MYD t2.MYI t2.frm t3.frm t4.frm
#memory,在重启mysql或者重启机器后,表内数据清空
#blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
5.3 表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段
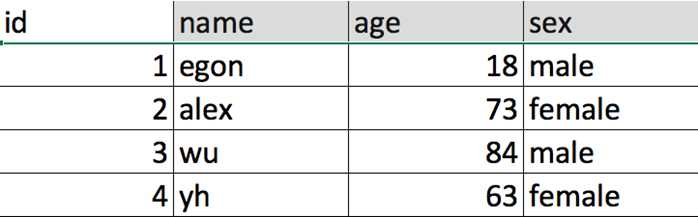
id,name,qq,age称为字段,其余的,一行内容称为一条记录
5.4 创建表
5.4.1 语法:
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
5.4.2 注意:
1. 在同一张表中,字段名是不能相同
2. 宽度和约束条件可选
3. 字段名和类型是必须的
5.4.3 实例
MariaDB [(none)]> create database db1 charset utf8;
MariaDB [(none)]> use db1;
MariaDB [db1]> create table t1(
-> id int,
-> name varchar(50),
-> sex enum(‘male‘,‘female‘),
-> age int(3)
-> );
MariaDB [db1]> show tables; #查看db1库下所有表名
MariaDB [db1]> desc t1;
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum(‘male‘,‘female‘) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
MariaDB [db1]> select id,name,sex,age from t1;
Empty set (0.00 sec)
MariaDB [db1]> select * from t1;
Empty set (0.00 sec)
MariaDB [db1]> select id,name from t1;
Empty set (0.00 sec)
############################往表中插入数据#####################3
MariaDB [db1]> insert into t1 values
-> (1,‘egon‘,18,‘male‘),
-> (2,‘alex‘,81,‘female‘)
-> ;
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
+------+------+------+--------+
MariaDB [db1]> insert into t1(id) values
-> (3),
-> (4);
MariaDB [db1]> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | egon | 18 | male |
| 2 | alex | 81 | female |
| 3 | NULL | NULL | NULL |
| 4 | NULL | NULL | NULL |
+------+------+------+--------+
注意注意注意:表中的最后一个字段不要加逗号
5.5 查看表结构
MariaDB [db1]> describe t1; #查看表结构,可简写为desc 表名
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum(‘male‘,‘female‘) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
MariaDB [db1]> show create table t1\\G; #查看表详细结构,可加\\G
5.6 修改表ALTER TABLE
5.6.1 语法
语法:
1. 修改表名
ALTER TABLE 表名
RENAME 新表名;
2. 增加字段
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…],
ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] FIRST;
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
3. 删除字段
ALTER TABLE 表名
DROP 字段名;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
5.6.2 示例
示例:
1. 修改存储引擎
mysql> alter table service
-> engine=innodb;
2. 添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; //添加name字段之后
mysql> alter table student10
-> add sex enum(‘male‘,‘female‘) default ‘male‘ first; //添加到最前面
3. 删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4. 修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; //修改为主键
5. 增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6. 对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7. 增加主键
mysql> alter table student1
-> modify name varchar(10) not null primary key;
8. 增加主键和自动增长
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9. 删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;
5.7 复制表
复制表结构+记录 (key不会复制: 主键、外键和索引)
mysql> create table new_service select * from service;
只复制表结构
mysql> select * from service where 1=2; //条件为假,查不到任何记录
Empty set (0.00 sec)
mysql> create table new1_service select * from service where 1=2;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create table t4 like employees;
5.8 删除表
DROP TABLE 表名;
5.9 数据类型
5.9.1 介绍
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
详细参考:
http://www.runoob.com/mysql/mysql-data-types.html
http://dev.mysql.com/doc/refman/5.7/en/data-type-overview.html
mysql常用数据类型概览
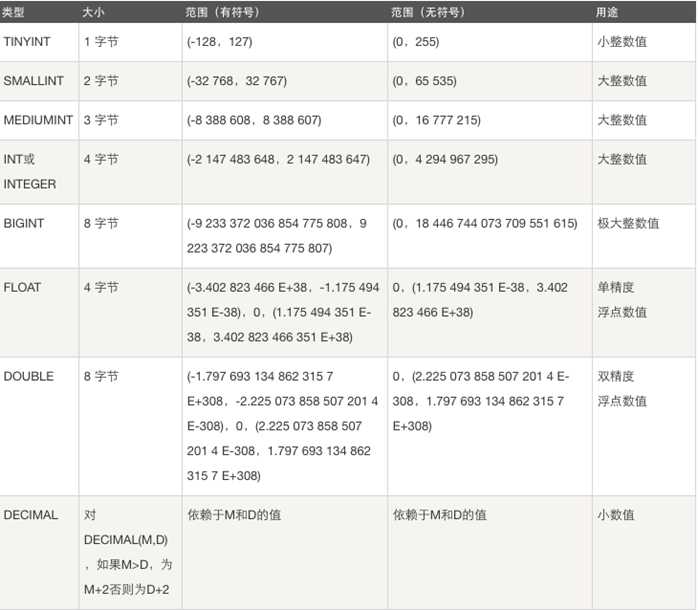
#1. 数字:
整型:tinyinit int bigint
小数:
float :在位数比较短的情况下不精准
double :在位数比较长的情况下不精准
0.000001230123123123
存成:0.000001230000
decimal:(如果用小数,则用推荐使用decimal)
精准
内部原理是以字符串形式去存
#2. 字符串:
char(10):简单粗暴,浪费空间,存取速度快
root存成root000000
varchar:精准,节省空间,存取速度慢
sql优化:创建表时,定长的类型往前放,变长的往后放
比如性别 比如地址或描述信息
>255个字符,超了就把文件路径存放到数据库中。
比如图片,视频等找一个文件服务器,数据库中只存路径或url。
#3. 时间类型:
最常用:datetime
#4. 枚举类型与集合类型
5.9.2 数值类型之整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等
========================================
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127
无符号:
~ 255
PS: MySQL中无布尔值,使用tinyint(1)构造。
========================================
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
~ 4294967295
========================================
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
~ 18446744073709551615
###########################验证###################################
=========有符号和无符号tinyint==========
#tinyint默认为有符号
MariaDB [db1]> create table t1(x tinyint); #默认为有符号,即数字前有正负号
MariaDB [db1]> desc t1;
MariaDB [db1]> insert into t1 values
-> (-129),
-> (-128),
-> (127),
-> (128);
MariaDB [db1]> select * from t1;
+------+
| x |
+------+
| -128 | #-129存成了-128
| -128 | #有符号,最小值为-128
| 127 | #有符号,最大值127
| 127 | #128存成了127
+------+
#设置无符号tinyint
MariaDB [db1]> create table t2(x tinyint unsigned);
MariaDB [db1]> insert into t2 values
-> (-1),
-> (0),
-> (255),
-> (256);
MariaDB [db1]> select * from t2;
+------+
| x |
+------+
| 0 | -1存成了0
| 0 | #无符号,最小值为0
| 255 | #无符号,最大值为255
| 255 | #256存成了255
+------+
============有符号和无符号int=============
#int默认为有符号
MariaDB [db1]> create table t3(x int); #默认为有符号整数
MariaDB [db1]> insert into t3 values
-> (-2147483649),
-> (-2147483648),
-> (2147483647),
-> (2147483648);
MariaDB [db1]> select * from t3;
+-------------+
| x |
+-------------+
| -2147483648 | #-2147483649存成了-2147483648
| -2147483648 | #有符号,最小值为-2147483648
| 2147483647 | #有符号,最大值为2147483647
| 2147483647 | #2147483648存成了2147483647
+-------------+
#设置无符号int
MariaDB [db1]> create table t4(x int unsigned);
MariaDB [db1]> insert into t4 values
-> (-1),
-> (0),
-> (4294967295),
-> (4294967296);
MariaDB [db1]> select * from t4;
+------------+
| x |
+------------+
| 0 | #-1存成了0
| 0 | #无符号,最小值为0
| 4294967295 | #无符号,最大值为4294967295
| 4294967295 | #4294967296存成了4294967295
+------------+
==============有符号和无符号bigint=============
MariaDB [db1]> create table t6(x bigint);
MariaDB [db1]> insert into t5 values
-> (-9223372036854775809),
-> (-9223372036854775808),
-> (9223372036854775807),
-> (9223372036854775808);
MariaDB [db1]> select * from t5;
+----------------------+
| x |
+----------------------+
| -9223372036854775808 |
| -9223372036854775808 |
| 9223372036854775807 |
| 9223372036854775807 |
+----------------------+
MariaDB [db1]> create table t6(x bigint unsigned);
MariaDB [db1]> insert into t6 values
-> (-1),
-> (0),
-> (18446744073709551615),
-> (18446744073709551616);
MariaDB [db1]> select * from t6;
+----------------------+
| x |
+----------------------+
| 0 |
| 0 |
| 18446744073709551615 |
| 18446744073709551615 |
+----------------------+
======用zerofill测试整数类型的显示宽度=============
MariaDB [db1]> create table t7(x int(3) zerofill);
MariaDB [db1]> insert into t7 values
-> (1),
-> (11),
-> (111),
-> (1111);
MariaDB [db1]> select * from t7;
+------+
| x |
+------+
| 001 |
| 011 |
| 111 |
| 1111 | #超过宽度限制仍然可以存
+------+
注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下
其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了
默认的显示宽度,都是在最大值的基础上加1
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
5.9.3 数值类型之浮点型
定点数类型 DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等
======================================
#FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
有符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38
精确度:
**** 随着小数的增多,精度变得不准确 ****
======================================
#DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
有符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
无符号:
2.2250738585072014E-308 to 1.7976931348623157E+308
精确度:
****随着小数的增多,精度比float要高,但也会变得不准确 ****
======================================
decimal[(m[,d])] [unsigned] [zerofill]
定义:
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
精确度:
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。
#####################验证########################
mysql> create table t1(x float(256,31));
ERROR 1425 (42000): Too big scale 31 specified for column ‘x‘. Maximum is 30.
mysql> create table t1(x float(256,30));
ERROR 1439 (42000): Display width out of range for column ‘x‘ (max = 255)
mysql> create table t1(x float(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t2(x double(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t3(x decimal(66,31));
ERROR 1425 (42000): Too big scale 31 specified for column ‘x‘. Maximum is 30.
mysql> create table t3(x decimal(66,30));
ERROR 1426 (42000): Too-big precision 66 specified for ‘x‘. Maximum is 65.
mysql> create table t3(x decimal(65,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| t1 |
| t2 |
| t3 |
+---------------+
rows in set (0.00 sec)
mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1
Query OK, 1 row affected (0.01 sec)
mysql> insert into t2 values(1.1111111111111111111111111111111);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(1.1111111111111111111111111111111);
Query OK, 1 row affected, 1 warning (0.01 sec)
mysql> select * from t1; #随着小数的增多,精度开始不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111164093017600000000000000 |
+----------------------------------+
row in set (0.00 sec)
mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111200000000000000 |
+----------------------------------+
row in set (0.00 sec)
mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111111111111111111 |
+----------------------------------+
row in set (0.00 sec)
5.9.4 课堂讲解实例
#1、整型(默认有符号)
create table t8(n tinyint);
insert into t8 values(-1);
insert into t8 values(128);
insert into t8 values(-129);
create table t9(n tinyint unsigned);
insert into t9 values(-1),(256);
#整型的宽度代表显示宽度
create table t11(n int(3) unsigned zerofill);
create table t12(n int unsigned zerofill);
create table t13(
id int
);
#2、浮点型
create table t13(x float(255,30));
create table t14(x double(255,30));
create table t15(x decimal(65,30));
insert into t13 values(1.111111111111111111111111111111);
insert into t14 values(1.111111111111111111111111111111);
insert into t15 values(1.111111111111111111111111111111);
5.10 日期类型
DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
5.10.1 示例
YEAR
YYYY(1901/2155)
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS(‘-838:59:59‘/‘838:59:59‘)
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
################################验证################################
============year===========
MariaDB [db1]> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4)
MariaDB [db1]> insert into t10 values
-> (1900),
-> (1901),
-> (2155),
-> (2156);
MariaDB [db1]> select * from t10;
+-----------+
| born_year |
+-----------+
| 0000 |
| 1901 |
| 2155 |
| 0000 |
+-----------+
============date,time,datetime===========
MariaDB [db1]> create table t11(d date,t time,dt datetime);
MariaDB [db1]> desc t11;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| d | date | YES | | NULL | |
| t | time | YES | | NULL | |
| dt | datetime | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
MariaDB [db1]> insert into t11 values(now(),now(),now());
MariaDB [db1]> select * from t11;
+------------+----------+---------------------+
| d | t | dt |
+------------+----------+---------------------+
| 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 |
+------------+----------+---------------------+
============timestamp===========
MariaDB [db1]> create table t12(time timestamp);
MariaDB [db1]> insert into t12 values();
MariaDB [db1]> insert into t12 values(null);
MariaDB [db1]> select * from t12;
+---------------------+
| time |
+---------------------+
| 2017-07-25 16:29:17 |
| 2017-07-25 16:30:01 |
+---------------------+
============注意啦,注意啦,注意啦===========
1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
2. 插入年份时,尽量使用4位值
3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
>=70,以19开头,比如71,结果1971
MariaDB [db1]> create table t12(y year);
MariaDB [db1]> insert into t12 values
-> (50),
-> (71);
MariaDB [db1]> select * from t12;
+------+
| y |
+------+
| 2050 |
| 1971 |
+------+
============综合练习===========
MariaDB [db1]> create table student(
-> id int,
-> name varchar(20),
-> born_year year,
-> birth date,
-> class_time time,
-> reg_time datetime);
MariaDB [db1]> insert into student values
-> (1,‘alex‘,"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"),
-> (2,‘egon‘,"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"),
-> (3,‘wsb‘,"1998","1998-01-01","13:13:13","2017-01-01 13:13:13");
MariaDB [db1]> select * from student;
+------+------+-----------+------------+------------+---------------------+
| id | name | born_year | birth | class_time | reg_time |
+------+------+-----------+------------+------------+---------------------+
| 1 | alex | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 |
| 2 | egon | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 |
| 3 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 |
+------+------+-----------+------------+------------+---------------------+
5.10.2 datetime与timestamp的区别
####################datetime与timestamp的区别###################
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。下面就来总结一下两种日期类型的区别。
1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。
2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
5.10.3 课堂讲解示例
create table student(
id int,
name char(16),
born_year year,
birth_date date,
class_time time,
reg_time datetime
);
insert into student values
(1,‘egon‘,now(),now(),now(),now())
;
insert into student values
(2,‘alex‘,‘1999‘,‘1999-11-11‘,‘11:11:11‘,"1999-11-11 11:11:11")
;
5.11 字符串类型
5.11.1 定长char与变长varchar的介绍
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
#注意:char和varchar括号内的参数指的都是字符的长度
#char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = ‘PAD_CHAR_TO_FULL_LENGTH‘;)
#varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果‘ab ‘,尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
检索:
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
|
Value |
CHAR(4) |
Storage Required |
VARCHAR(4) |
Storage Required |
|
‘‘ |
‘ ‘ |
4 bytes |
‘‘ |
1 byte |
|
‘ab‘ |
‘ab ‘ |
4 bytes |
‘ab‘ |
3 bytes |
|
‘abcd‘ |
‘abcd‘ |
4 bytes |
‘abcd‘ |
5 bytes |
|
‘abcdefgh‘ |
‘abcd‘ |
4 bytes |
‘abcd‘ |
5 bytes |
测试前了解两个函数
length:查看字节数
char_length:查看字符数
5.11.2 定长char与变长varchar的示例
1. char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形
mysql> create table t1(x char(5),y varchar(5));
Query OK, 0 rows affected (0.26 sec)
#char存5个字符,而varchar存4个字符
mysql> insert into t1 values(‘你瞅啥 ‘,‘你瞅啥 ‘);
Query OK, 1 row affected (0.05 sec)
mysql> SET sql_mode=‘‘;
Query OK, 0 rows affected, 1 warning (0.00 sec)
#在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少
mysql> select x,char_length(x),y,char_length(y) from t1;
+-----------+----------------+------------+----------------+
| x | char_length(x) | y | char_length(y) |
+-----------+----------------+------------+----------------+
| 你瞅啥 | 3 | 你瞅啥 | 4 |
+-----------+----------------+------------+----------------+
row in set (0.00 sec)
#略施小计,让char现出原形
mysql> SET sql_mode = ‘PAD_CHAR_TO_FULL_LENGTH‘;
Query OK, 0 rows affected (0.00 sec)
#这下子char原形毕露了......
mysql> select x,char_length(x),y,char_length(y) from t1;
+-------------+----------------+------------+----------------+
| x | char_length(x) | y | char_length(y) |
+-------------+----------------+------------+----------------+
| 你瞅啥 | 5 | 你瞅啥 | 4 |
+-------------+----------------+------------+----------------+
row in set (0.00 sec)
#char类型:3个中文字符+2个空格=11Bytes
#varchar类型:3个中文字符+1个空格=10Bytes
mysql> select x,length(x),y,length(y) from t1;
+-------------+-----------+------------+-----------+
| x | length(x) | y | length(y) |
+-------------+-----------+------------+-----------+
| 你瞅啥 | 11 | 你瞅啥 | 10 |
+-------------+-----------+------------+-----------+
row in set (0.00 sec)
############################了解concat#########################
mysql> select concat(‘数据: ‘,x,‘长度: ‘,char_length(x)),concat(y,char_length(y)
) from t1;
+------------------------------------------------+--------------------------+
| concat(‘数据: ‘,x,‘长度: ‘,char_length(x)) | concat(y,char_length(y)) |
+------------------------------------------------+--------------------------+
| 数据: 你瞅啥 长度: 5 | 你瞅啥 4 |
+------------------------------------------------+--------------------------+
row in set (0.00 sec)
2. 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样,,但这不适用于like
Values in CHAR and VARCHAR columns are sorted and compared according to the character set collation assigned to the column.
All MySQL collations are of type PAD SPACE. This means that all CHAR, VARCHAR, and TEXT values are compared without regard to any trailing spaces. “Comparison” in this context does not include the LIKE pattern-matching operator, for which trailing spaces are significant. For example:
mysql> CREATE TABLE names (myname CHAR(10));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO names VALUES (‘Monty‘);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT myname = ‘Monty‘, myname = ‘Monty ‘ FROM names;
+------------------+--------------------+
| myname = ‘Monty‘ | myname = ‘Monty ‘ |
+------------------+--------------------+
| 1 | 1 |
+------------------+--------------------+
row in set (0.00 sec)
mysql> SELECT myname LIKE ‘Monty‘, myname LIKE ‘Monty ‘ FROM names;
+---------------------+-----------------------+
| myname LIKE ‘Monty‘ | myname LIKE ‘Monty ‘ |
+---------------------+-----------------------+
| 1 | 0 |
+---------------------+-----------------------+
row in set (0.00 sec)
5.11.3 课堂讲解示例
char:定长
varchar:变长
#宽度代表的是字符的个数
create table t16(name char(5));
create table t17(name varchar(5));
insert into t16 values(‘李杰 ‘); #‘李杰 ‘
insert into t17 values(‘李杰 ‘); #‘李杰 ‘
select char_length(name) from t16; #5
select char_length(name) from t17; #3
mysql> set sql_mode=‘PAD_CHAR_TO_FULL_LENGTH‘;
select * from t16 where name=‘李杰‘;
select * from t17 where name=‘李杰‘;
select * from t16 where name like ‘李杰‘;
name char(5)
egon |alex |wxx |
name varchar(5)
1bytes+egon|1bytes+alex|1bytes+wxx|
5.11.4 总结
#常用字符串系列:char与varchar
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
#其他字符串系列(效率:char>varchar>text)
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY
text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 ? 1)个字符。
mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 ? 1) characters.
longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 ? 1) characters.
5.12 枚举类型与集合类型
字段的值只能在给定范围中选择,如单选框,多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
5.12.1 示例
枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM(‘x-small‘, ‘small‘, ‘medium‘, ‘large‘, ‘x-large‘)
);
INSERT INTO shirts (name, size) VALUES (‘dress shirt‘,‘large‘), (‘t-shirt‘,‘medium‘),(‘polo shirt‘,‘small‘);
集合类型(set)
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET(‘a‘, ‘b‘, ‘c‘, ‘d‘));
INSERT INTO myset (col) VALUES (‘a,d‘), (‘d,a‘), (‘a,d,a‘), (‘a,d,d‘), (‘d,a,d‘);
#########################验证####################
MariaDB [db1]> create table consumer(
-> name varchar(50),
-> sex enum(‘male‘,‘female‘),
-> level enum(‘vip1‘,‘vip2‘,‘vip3‘,‘vip4‘,‘vip5‘), #在指定范围内,多选一
-> hobby set(‘play‘,‘music‘,‘read‘,‘study‘) #在指定范围内,多选多
-> );
MariaDB [db1]> insert into consumer values
-> (‘egon‘,‘male‘,‘vip5‘,‘read,study‘),
-> (‘alex‘,‘female‘,‘vip1‘,‘girl‘);
MariaDB [db1]> select * from consumer;
+------+--------+-------+------------+
| name | sex | level | hobby |
+------+--------+-------+------------+
| egon | male | vip5 | read,study |
| alex | female | vip1 | |
+------+--------+-------+------------+
5.12.2 课堂讲解示例
create table employee(
id int,
name char(10),
sex enum(‘male‘,‘female‘,‘other‘),
hobbies set(‘play‘,‘eat‘,‘music‘,‘read‘)
);
insert into employee values
(1,‘egon‘,‘male‘,‘music,read‘);
insert into employee values
(2,‘alex‘,‘xxxx‘,‘music,read‘);