首先分析网页,找到教务处登录的验证码
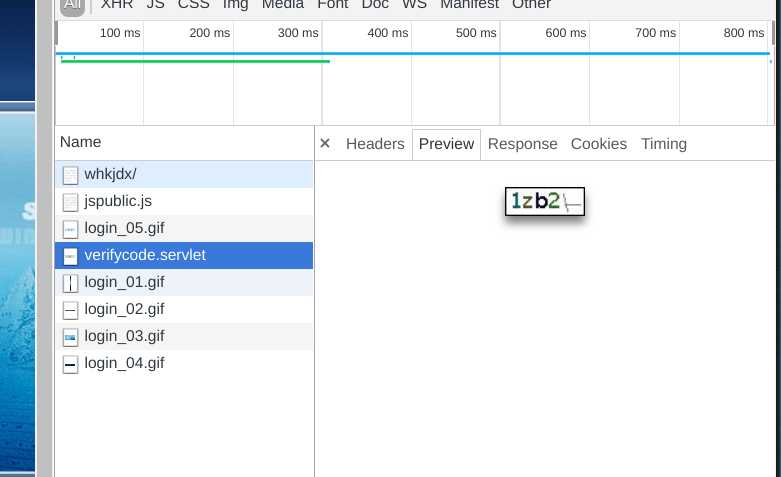
然后用 Python 直接把验证码下载到本地(整个程序通过 requests 库实现):
def GetRandCode():
url = r‘http://jwxt.wust.edu.cn/whkjdx/verifycode.servlet‘
ans = foo.get(url)
with open(‘randcode.jpg‘, ‘wb‘) as file:
file.write(ans.content)找到验证码之后继续找到登录的api,我们可以发现网页发出了一个 post 请求,还有相关参数:
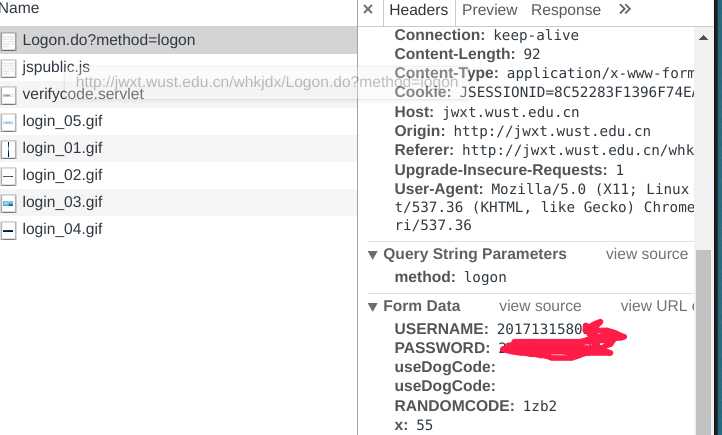
接着要实现登录就非常简单了,我先简单写了个登录的实现:
foo = foo = requests.session()
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36",
}
def Login(username, password, randcode):
url = r‘http://jwxt.wust.edu.cn/whkjdx/Logon.do?method=logon‘
information = {‘USERNAME‘: username, ‘PASSWORD‘: password, ‘RANDOMCODE‘: randcode}
ans = foo.post(url, data = information, headers = headers)
ans.raise_for_status()
ans.encoding = ans.apparent_encoding
if ans.text.find(r‘http://jwxt.wust.edu.cn/whkjdx/framework/main.jsp‘) != -1:
return True
else:
return False测试了一下发现是可以正常登录的,紧接着就要做获取选课列表了,方法同上。
我发现本学期的获取选课列表的地址是 http://jwxt.wust.edu.cn/whkjdx/xkglAction.do?method=toFindxskxkclb&xnxq01id=2017-2018-2&zzdxklbname=1&type=1&jx02kczid=null 很明显参数 xnxq01id 应该就是学期号了,规则也很容易发现。然后我就直接用Python实现了一下,然后发现网页会返回没有访问权限的消息。回过头分析登录过程,发现还有一个 SSO(点对点登录)的 API,然后试了一下新的登录函数:
def Login(username, password, randcode):
url = r‘http://jwxt.wust.edu.cn/whkjdx/Logon.do?method=logon‘
SSOurl = r‘http://jwxt.wust.edu.cn/whkjdx/Logon.do?method=logonBySSO‘
information = {‘USERNAME‘: username, ‘PASSWORD‘: password, ‘RANDOMCODE‘: randcode}
ans = foo.post(url, data = information, headers = headers)
ans.raise_for_status()
ans.encoding = ans.apparent_encoding
ans2 = foo.post(SSOurl, headers)
ans2.raise_for_status()
if ans.text.find(r‘http://jwxt.wust.edu.cn/whkjdx/framework/main.jsp‘) != -1:
return True
else:
return False通过新的登录函数可以正常获取公选课选课列表。具体实现如下:
def GetCoursesList():
url = r‘http://jwxt.wust.edu.cn/whkjdx/xkglAction.do?method=toFindxskxkclb&xnxq01id=2017-2018-2&zzdxklbname=1&type=1&jx02kczid=null‘
ans = foo.get(url, headers = headers)
ans.raise_for_status()
ans.encoding = ans.apparent_encoding
CoursesList = re.findall(r‘<td height="23" style="text-overflow:ellipsis; white-space:nowrap; overflow:hidden;" width="\\d+" title=".*"‘, ans.text)
XKLJList = re.findall("javascript:vJsMod\\(\\‘.*\\‘", ans.text)
keyname = [‘kcmc‘, ‘kkdw‘, ‘zyfx‘, ‘xf‘, ‘yxrs‘, ‘yl‘, ‘skjs‘, ‘skzc‘, ‘sksj‘, ‘skdd‘, ‘kcsx‘, ‘kcxz‘, ‘fzm‘, ‘xbyq‘]
result = []
item = {}
bar = 0
index = 0
for i in CoursesList:
Left = i.find(r‘title="‘)
Right = i[Left + 7:].find(r‘"‘)
text = i[Left + 7:Left + Right + 7]
#print(i)
#print(text)
item[keyname[bar]] = text
bar = bar + 1
if (bar == 14):
Left = XKLJList[index].find("‘")
Right = XKLJList[index][Left + 1:].find("‘")
text = XKLJList[index][Left + 1:Left + Right + 1]
item[‘xklj‘] = text
index = index + 1
result.append(item)
item = {}
bar = 0
return result其中正则表达式匹配所有网页列表中的信息,每 14 项是一个课程的全部信息,具体信息对应哪些,可以看列表的表头,我用字典来保存这些课程的信息,然后存到一个列表里,每个信息的拼音简写就是字典中对应的键的名称,然后又有一个 xklj 用来保存选课时需要通过 get 访问的链接,这样实现选课就非常简单了,只需要对这个链接发送 get 请求即可:
def ChoseCourseByLink(link):
url = ‘http://jwxt.wust.edu.cn‘ + link
ans = foo.get(url, headers = headers)
ans.raise_for_status()
ans.encoding = ans.apparent_encoding
return ans.text然后用同样的办法构造学分制选课的列表:
def GetCoursesList2():
url = r‘http://jwxt.wust.edu.cn/whkjdx/xkglAction.do?method=toFindxskxkclb&xnxq01id=2017-2018-2&zzdxklbname=6&type=1&jx02kczid=null‘
ans = foo.get(url, headers = headers)
ans.raise_for_status()
ans.encoding = ans.apparent_encoding
CoursesList = re.findall(r‘<td height="23" style="text-overflow:ellipsis; white-space:nowrap; overflow:hidden;" width="\\d+" title=".*"‘, ans.text)
XKLJList = re.findall("javascript:vJsMod\\(\\‘.*\\‘", ans.text)
keyname = [‘kcmc‘, ‘kkdw‘, ‘zyfx‘, ‘xf‘, ‘yxrs‘, ‘yl‘, ‘skjs‘, ‘skzc‘, ‘sksj‘, ‘skdd‘, ‘kcsx‘, ‘kcxz‘, ‘fzm‘, ‘xbyq‘]
result = []
item = {}
bar = 0
index = 0
for i in CoursesList:
Left = i.find(r‘title="‘)
Right = i[Left + 7:].find(r‘"‘)
text = i[Left + 7:Left + Right + 7]
#print(i)
#print(text)
item[keyname[bar]] = text
bar = bar + 1
if (bar == 14):
Left = XKLJList[index].find("‘")
Right = XKLJList[index][Left + 1:].find("‘")
text = XKLJList[index][Left + 1:Left + Right + 1]
item[‘xklj‘] = text
index = index + 1
result.append(item)
item = {}
bar = 0
return result这样一个简单的抢课库就实现了,抢课的时候只需要调用相关的接口就行了,最终全部代码在我的 Github 上:https://github.com/Rugel/wustjwxt