Selenium(Python)生成Html测试报告
Posted 此生不换Yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium(Python)生成Html测试报告相关的知识,希望对你有一定的参考价值。
由于Python3已经不支持HTMLTestRunner了,
无论是PyCharm还是pip都无法安装成功,
所以只能去
http://tungwaiyip.info/software/HTMLTestRunner_0_8_2/HTMLTestRunner.py
手动下载:
在网页空白处点击鼠标右键,
选择另存为:
为了适配Python3,
作了部分修改,
修改过后的文件我会在后面的博客中贴出来,
把HTMLTestRunner.py文件放到Python3安装目录下的Lib文件夹里面;
还有一个地方需要注意的是,
Python3已经不支持file方法了,
应该用open!
新建TestCase.py:
import unittest
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
class SearchTestCase(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.maximize_window()
self.driver.get("https://www.baidu.com/")
self.driver.implicitly_wait(15)
def test_searchChina(self):
"""百度搜索中国的测试用例"""
self.driver.find_element_by_xpath(".//*[@id=\'kw\']").send_keys("中国")
self.driver.find_element_by_xpath(".//*[@id=\'su\']").click()
WebDriverWait(self.driver, 15).until(lambda x: x.find_element_by_xpath(".//*[@id=\'1\']/h3/a"))
result = self.driver.find_element_by_xpath(".//*[@id=\'1\']/h3/a").text
self.assertEqual(result, "中国_百度百科")
def tearDown(self):
self.driver.close()
self.driver.quit()
if __name__ == \'__main__\':
unittest.main()
然后再新建HtmlReport.py:
import HTMLTestRunner
import unittest
from time import strftime, localtime, time
from TestCase import SearchTestCase
suite = unittest.TestSuite()
# 获取TestSuite的实例对象
suite.addTest(SearchTestCase("test_searchChina"))
# 把测试用例添加到测试容器中
now = strftime("%Y-%m-%M-%H_%M_%S", localtime(time()))
# 获取当前时间
filename = now + "test.html"
# 文件名
fp = open(filename, "wb")
# 以二进制的方式打开文件并写入结果
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,
verbosity=2,
title="测试报告的标题",
description="测试报告的详情")
runner.run(suite)
fp.close()
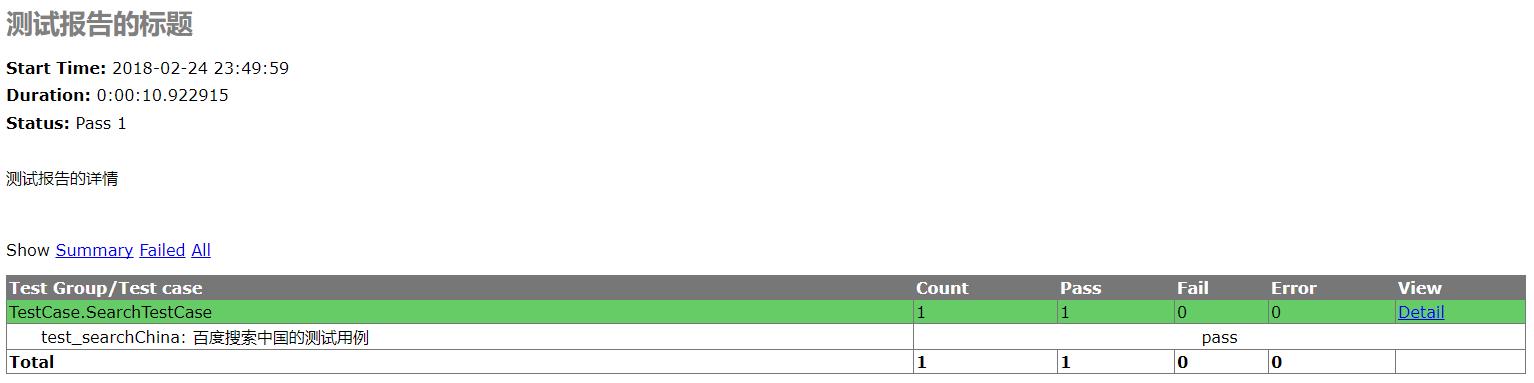
运行一把,
会在当前工程的目录下生成html文件,
打开之:
以上是关于Selenium(Python)生成Html测试报告的主要内容,如果未能解决你的问题,请参考以下文章