sql 连续活跃天数
Posted 三三呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql 连续活跃天数相关的知识,希望对你有一定的参考价值。
1. 背景
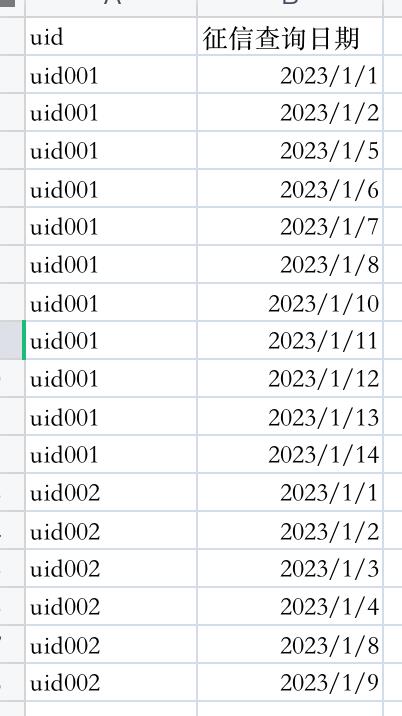
已知数据集为:
目的:
计算每个uid的连续活跃天数,并且每一段活跃期内的开始时间和结束时间
2. 步骤
第一步:处理数据集
处理数据集,使其满足每个uid每个日期只有一条数据。
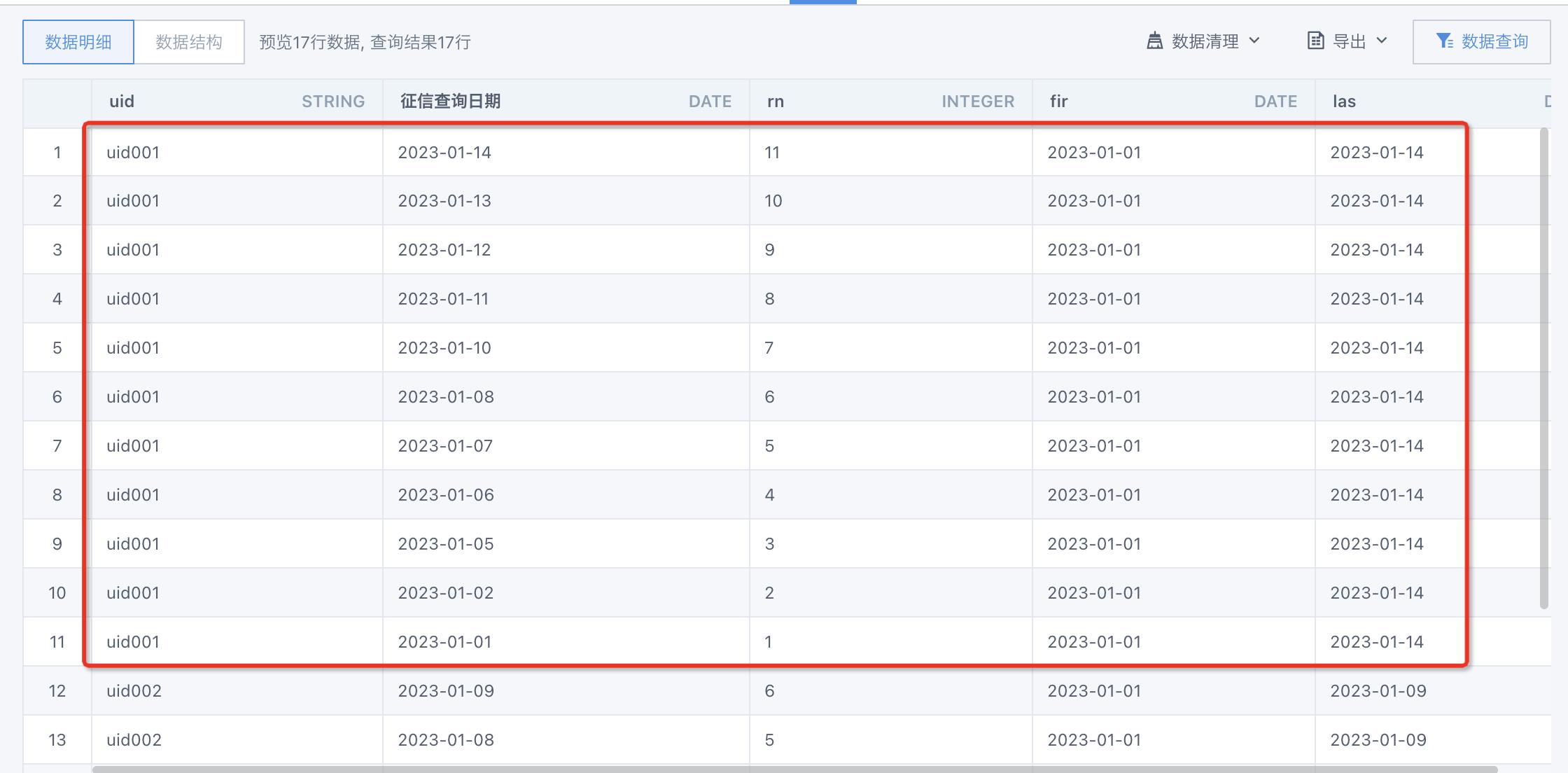
第二步:以uid为主键,按照日期进行排序,计算row_number.
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input
两个关键点:
- 序号rn可以看做一直活跃的情况下,活跃日期最大值和活跃日期最小值之间的天数差。那么,日期最大值与日期最小值之差如果不等于序号,就表明中间有不连续。
- 用\'征信查询日期\' - rn 可以计算一列"关键列",连续时间段内,它的关键列值是一样的
select *,DATE_SUB(`征信查询日期`,`rn`) as `关键列` from (
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input)
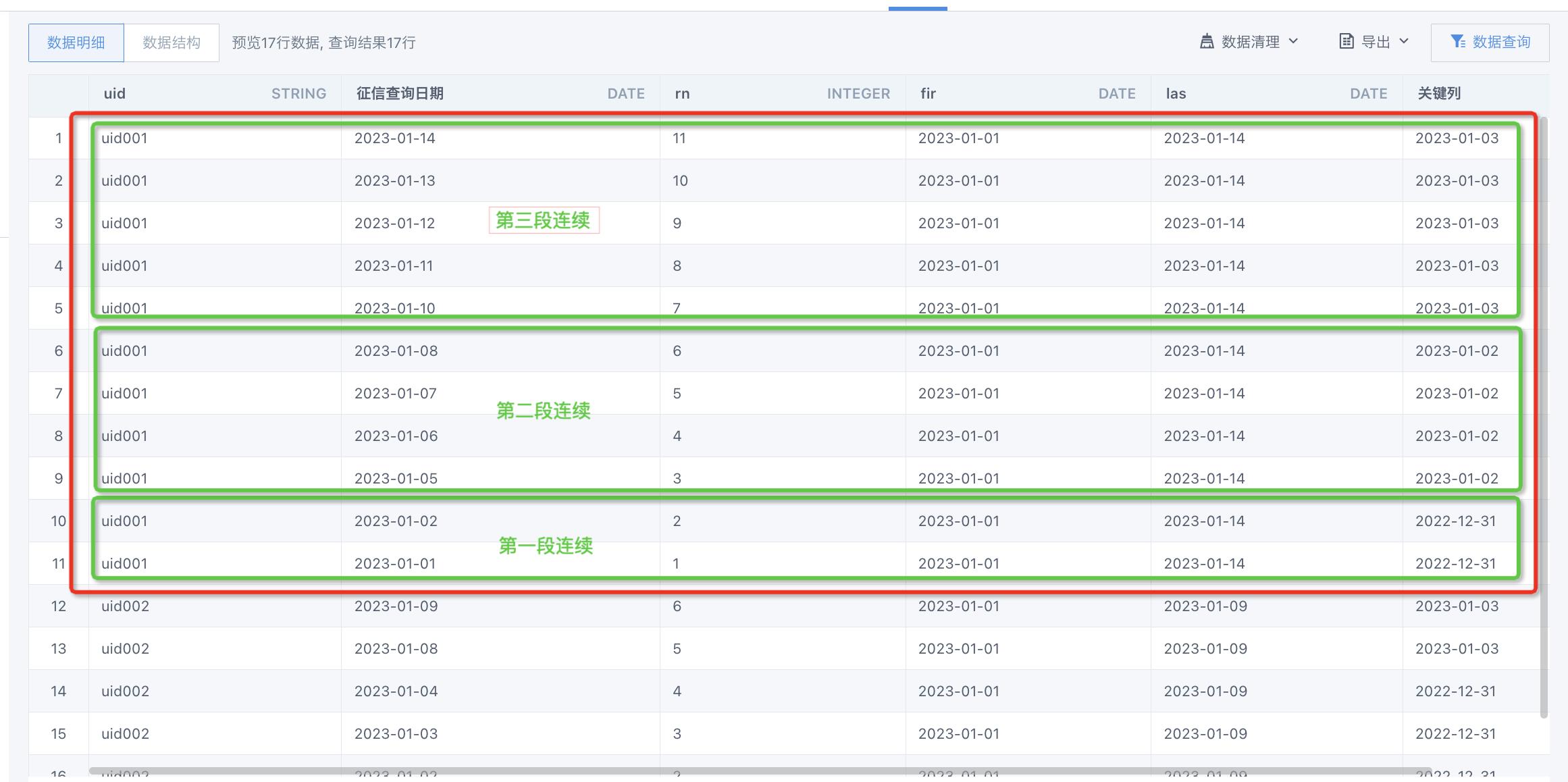
第三步:以uid和关键列作为主键。
select uid, `关键列`,count(*) as `连续活跃天数`, min(`征信查询日期`) as `活跃开始时间`, max(`征信查询日期`) as `活跃结束时间` from (
select *, DATE_SUB(`征信查询日期`,`rn`) as `关键列` from (
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input
) )group by uid, `关键列`

spark sql 连续登录最大天数
参考技术A 数据:注意:
| 3|2020-09-04|
| 3|2020-09-04|
这里是有重复的,所以
第一步是去重复:
第二步:
同一个user_id的登录时间进行排序
第三步:
用dt减去排名之后,如果时间是连续的,那么结果相同。
第四步:
对相同的时间进行求和:
第五步:
求最大连续天数:
整个sql:
以上是关于sql 连续活跃天数的主要内容,如果未能解决你的问题,请参考以下文章