什么是持久性?
概念
持久性的基本思想很简单。假定有一个 Python 程序,它可能是一个管理日常待办事项的程序,您希望在多次执行这个程序之间可以保存应用程序对象(待办事项)。换句话说,您希望将对象存储在磁盘上,便于以后检索。这就是持久性。要达到这个目的,有几种方法,每一种方法都有其优缺点。
例如,可以将对象数据存储在某种格式的文本文件中,譬如 CSV 文件。或者可以用关系数据库,譬如 Gadfly、MySQL、PostgreSQL 或者 DB2。这些文件格式和数据库都非常优秀,对于所有这些存储机制,Python 都有健壮的接口。
特点
这些存储机制都有一个共同点:存储的数据是独立于对这些数据进行操作的对象和程序。这样做的好处是,数据可以作为共享的资源,供其它应用程序使用。缺点是,用这种方式,可以允许其它程序访问对象的数据,这违背了面向对象的封装性原则 — 即对象的数据只能通过这个对象自身的公共(public)接口来访问。
另外,对于某些应用程序,关系数据库方法可能不是很理想。尤其是,关系数据库不理解对象。相反,关系数据库会强行使用自己的类型系统和关系数据模型(表),每张表包含一组元组(行),每行包含具有固定数目的静态类型字段(列)。如果应用程序的对象模型不能够方便地转换到关系模型,那么在将对象映射到元组以及将元组映射回对象方面,会碰到一定难度。这种困难常被称为阻碍性不匹配(impedence-mismatch)问题。
对象持久性
如果希望透明地存储 Python 对象,而不丢失其身份和类型等信息,则需要某种形式的对象序列化:它是一个将任意复杂的对象转成对象的文本或二进制表示的过程。同样,必须能够将对象经过序列化后的形式恢复到原有的对象。在 Python 中,这种序列化过程称为 pickle,可以将对象 pickle 成字符串、磁盘上的文件或者任何类似于文件的对象,也可以将这些字符串、文件或任何类似于文件的对象 unpickle 成原来的对象。我们将在本文后面详细讨论 pickle。
注:
- 英 [‘p?k(?)l]
- 美 [‘p?kl]
- n. 泡菜;盐卤;腌制食品
- vt. 泡;腌制
假定您喜欢将任何事物都保存成对象,而且希望避免将对象转换成某种基于非对象存储的开销;那么 pickle 文件可以提供这些好处,但有时可能需要比这种简单的 pickle 文件更健壮以及更具有可伸缩性的事物。例如,只用 pickle 不能解决命名和查找 pickle 文件这样的问题,另外,它也不能支持并发地访问持久性对象。如果需要这些方面的功能,则要求助类似于 ZODB(针对 Python 的 Z 对象数据库)这类数据库。ZODB 是一个健壮的、多用户的和面向对象的数据库系统,它能够存储和管理任意复杂的 Python 对象,并支持事务操作和并发控制。(请参阅 参考资料,以下载 ZODB。)令人足够感兴趣的是,甚至 ZODB 也依靠 Python 的本机序列化能力,而且要有效地使用 ZODB,必须充分了解 pickle。
另一种令人感兴趣的解决持久性问题的方法是 Prevayler,它最初是用 Java 实现的(有关 Prevaylor 方面的developerWorks 文章,请参阅 参考资料)。最近,一群 Python 程序员将 Prevayler 移植到了 Python 上,另起名为 PyPerSyst,由 SourceForge 托管(有关至 PyPerSyst 项目的链接,请参阅 参考资料)。Prevayler/PyPerSyst 概念也是建立在 Java 和 Python 语言的本机序列化能力之上。PyPerSyst 将整个对象系统保存在内存中,并通过不时地将系统快照 pickle 到磁盘以及维护一个命令日志(通过此日志可以重新应用最新的快照)来提供灾难恢复。所以,尽管使用 PyPerSyst 的应用程序受到可用内存的限制,但好处是本机对象系统可以完全装入到内存中,因而速度极快,而且实现起来要比如 ZODB 这样的数据库简单,ZODB 允许对象的数目比同时在能内存中所保持的对象要多。
既然我们已经简要讨论了存储持久对象的各种方法,那么现在该详细探讨 pickle 过程了。虽然我们主要感兴趣的是探索以各种方式来保存 Python 对象,而不必将其转换成某种其它格式,但我们仍然还有一些需要关注的地方,譬如:如何有效地 pickle 和 unpickle 简单对象以及复杂对象,包括定制类的实例;如何维护对象的引用,包括循环引用和递归引用;以及如何处理类定义发生的变化,从而使用以前经过 pickle 的实例时不会发生问题。我们将在随后关于 Python 的 pickle 能力探讨中涉及所有这些问题。
pickle
作用:对象串行化。
Python版本:pickle为L4及以后版本,cPickle为1.5及以后版本
pickle模块实现了一个算法可以将一个任意的Python对象转换为一系列字节。这个过程 也称为串行化对象。表示对象的字节流可以传输或存储,然后重新构造来创建有相同性质的 新对象。
cPickle模块实现了同样的算法,不过用C实现而不是Python。它比Python实现要快数倍, 所以通常会使用这个模块而不是纯Python实现。
pickle的文档明确指出它不提供任何安全保证。实际上,对数据解除pickle可以执行 任意的代码。使用pickle完成进程间通佶或数据存倚时要当心,另外不要相信未得到安全硷 证的数据.可以参见hmac—节,其中有一个例子展示了采用一种安全方式来验证pickle数 槐泳来通。
导入
由于cPickle比pickle更快,所以通常首先会尝试导入cPickle,并给定一个别名“pickle”, 如果导入失败,则退而使用pickle中的内置Python实现。这说明,如果有更快的实现,程序总 是倾向于使用更快的实现,否则才使用可移植的实现。
try:
import cPickle as pickle
except:
import pickleC和Python版本的API完全相同,数据可以在使用C和Python版本库的程序之间交换。
编码和解码字符串数据
第一个例子使用dumps将一个数据结构编码为一个字符串,然后把这个字符串打印到控制台。它使用了一个完全由内置类型构成的数据结构。任何类的实例都可以pickle,如下例所示:
try:
import cPickle as pickle
except:
import pickle
import pprint
data = [ { 'a':'A', 'b':2, 'c':3.0 } ]
print 'DATA:',
pprint.pprint(data)
data_string = pickle.dumps(data)
print 'PICKLE: %r' % data_string默认情况下,pickle只包含ASCII字符。还有一种更髙效的二进制pickle格式,不过这里的所有例子都使用ASCII输出,因为这样在打印时更容易理解
DATA:[{'a': 'A', 'b': 2, 'c': 3.0}]
PICKLE: "(lp1\\n(dp2\\nS'a'\\nS'A'\\nsS'c'\\nF3\\nsS'b'\\nI2\\nsa."
[Finished in 0.1s]数据串行化后,可以写到一个文件、套接字或者管道等等。之后可以读取这个文件,将数据解除pickle,用同样的值构造一个新的对象。
try:
import cPickle as pickle
except:
import pickle
import pprint
data1 = [ { 'a':'A', 'b':2, 'c':3.0 } ]
print 'BEFORE: ',
pprint.pprint(data1)
data1_string = pickle.dumps(data1)
data2 = pickle.loads(data1_string)
print 'AFTER : ',
pprint.pprint(data2)
print 'SAME? :', (data1 is data2)
print 'EQUAL?:', (data1 == data2)新构造的对象等于原来的对象,但并不是同一个对象。
BEFORE: [{'a': 'A', 'b': 2, 'c': 3.0}]
AFTER : [{'a': 'A', 'b': 2, 'c': 3.0}]
SAME? : False
EQUAL?: True
[Finished in 0.1s]处理流
除了dumps和loads,pickle还提供了一些便利函数处理类文件的流。可以向一个流写多个对象,然后从流读取这些对象,而无须事先知道要写多少个对象或者这些对象有多大
try:
import cPickle as pickle
except:
import pickle
import pprint
from StringIO import StringIO
class SimpleObject(object):
def __init__(self, name):
self.name = name
self.name_backwards = name[::-1]
return
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
# Simulate a file with StringIO
out_s = StringIO()
# Write to the stream
for o in data:
print 'WRITING : %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s)
out_s.flush()
# Set up a read-able stream
in_s = StringIO(out_s.getvalue())
# Read the data
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print 'READ : %s (%s)' % (o.name, o.name_backwards)这个例子使用两个StringIO缓冲区来模拟流。第一个缓冲区接收pickle的对象.将其值传入到第二个缓冲区,load()将读取这个缓冲区。简单的数据库格式也可以使用pickle来存储对象(参见shelve)
WRITING : pickle (elkcip)
WRITING : cPickle (elkciPc)
WRITING : last (tsal)
READ : pickle (elkcip)
READ : cPickle (elkciPc)
READ : last (tsal)
[Finished in 0.1s]除了存储数据,pickle对于进程间通信也很方便。例如,os.fork和os.pipe可以用来建立工作进程,从一个管道读取作业指令,并把结果写至另一个管道。管理工作线程池以及发送 作业和接收响应的核心代码可以重用,因为作业和响应对象不必基干一个特定的类s使用管道 或套接字时,在转储各个对象之后不要忘记刷新输出,将数据通过连接推至另一端。要了解可重用的工作线程池管理器,可以参见multiprocessing模块。
重构对象的问题
处理定制类时,pickle类必须出现在读取pickle的进程所在的命名空间。只会pickle这个实例的数据,而不包括类定义。类名用于査找构造函数,以便在解除pickle时创建新对象。下面这个例子将一个类的实例写至一个文件。
try:
import cPickle as pickle
except:
import pickle
class SimpleObject(object):
def __init__(self, name):
self.name = name
l = list(name)
l.reverse()
self.name_backwards = ''.join(l)
return
if __name__ == '__main__':
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('cPickle'))
data.append(SimpleObject('last'))
filename = "test.dat"
with open(filename, 'wb') as out_s:
# Write to the stream
for o in data:
print 'WRITING: %s (%s)' % (o.name, o.name_backwards)
pickle.dump(o, out_s)运行结果:
WRITING: pickle (elkcip)
WRITING: cPickle (elkciPc)
WRITING: last (tsal)
[Finished in 0.1s]如果简单地试图加载得到的pickle对象,将会失败。
try:
import cPickle as pickle
except:
import pickle
import pprint
from StringIO import StringIO
import sys
filename = "test.dat"
with open(filename, 'rb') as in_s:
# Read the data
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print 'READ: %s (%s)' % (o.name, o.name_backwards)失败的原因在于并没有SimpleObject类。
Traceback (most recent call last):
。。。。。。
o = pickle.load(in_s)
AttributeError: 'module' object has no attribute 'SimpleObject'修正后的版本从原脚本导入SimpleObject,这一次运行会成功。在导入列表的最后添加以下import语句,从而允许脚本査找类并构造对象。
from pickle_dump_to_file_1 import SimpleObject现在运行修改后的脚本会生成期望的结果。
READ: pickle (elkcip)
READ: cPickle (elkciPc)
READ: last (tsal)
[Finished in 0.1s]不可pickle的对象
并不是所有对象都是可pickle的。套接字、文件句柄、数据库连按以及其他运行时状态依赖于操作系统或其他进程的对象可能无法用一种有意义的方式保存。如果对象包含不可pickle的属性,可以定义_getstate_()和_setstate_()来返回可pickle实例状态的一个子集。新式 的类还可以定这会返回要传至类内存分配器(C._new_())的参数。这些特性的使用在标准库文档中有更详细的介绍。
循环引用
pickle协议会自动处理对象之间的循环引用,所以复杂数据结构不需要任何特殊的处理。考虑图中的有向图。图中包含几个循环,不过仍然可以pickle正确的结构然后重新加栽。
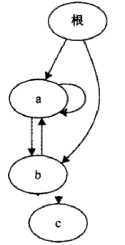
import pickle
class Node(object):
"""A simple digraph
"""
def __init__(self, name):
self.name = name
self.connections = []
def add_edge(self, node):
"Create an edge between this node and the other."
self.connections.append(node)
def __iter__(self):
return iter(self.connections)
def preorder_traversal(root, seen=None, parent=None):
"""Generator function to yield the edges in a graph.
"""
if seen is None:
seen = set()
yield (parent, root)
if root in seen:
return
seen.add(root)
for node in root:
for parent, subnode in preorder_traversal(node, seen, root):
yield (parent, subnode)
def show_edges(root):
"Print all the edges in the graph."
for parent, child in preorder_traversal(root):
if not parent:
continue
print '%5s -> %2s (%s)' % \\
(parent.name, child.name, id(child))
# Set up the nodes.
root = Node('root')
a = Node('a')
b = Node('b')
c = Node('c')
# Add edges between them.
root.add_edge(a)
root.add_edge(b)
a.add_edge(b)
b.add_edge(a)
b.add_edge(c)
a.add_edge(a)
print 'ORIGINAL GRAPH:'
show_edges(root)
# Pickle and unpickle the graph to create
# a new set of nodes.
dumped = pickle.dumps(root)
reloaded = pickle.loads(dumped)
print '\\nRELOADED GRAPH:'
show_edges(reloaded)重新加栽的节点并不是同一个对象,不过节点之间的关系得到了维护,而且如果对象有多个引用,那么只会重新加栽它的一个副本。要验证这两点,可以对通过pickle传递之前和传递 之后的节点的id值进行检査。
ORIGINAL GRAPH:
root -> a (83389632)
a -> b (83714736)
b -> a (83389632)
b -> c (83714792)
a -> a (83389632)
root -> b (83714736)
RELOADED GRAPH:
root -> a (83714904)
a -> b (83714960)
b -> a (83714904)
b -> c (83715296)
a -> a (83714904)
root -> b (83714960)
[Finished in 0.1s]