关闭内存缓存对效能有影响吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关闭内存缓存对效能有影响吗相关的知识,希望对你有一定的参考价值。
请注意,我问的是内存的缓存,不是系统缓存。我目前的内存是2G。
是内存缓存,不是虚拟内存。
没有。
在系统中所有的进程之间是共享CPU和主存这些内存资源的。当进程数量变多时,所需要的内存资源就会相应的增加。可能会导致部分程序没有主存空间可用。此外,由于资源是共享的,那么就有可能导致某个进程不小心写了另一个进程所使用的内存,进而导致程序运行不符合正常逻辑。
内存缓存注意事项
使用Java堆内存来存储对象。使用堆缓存的好处是没有序列化/反序列化,是最快的缓存。缺点也很明显,当缓存的数据量很大时,GC(垃圾回收)暂停时间会变长,存储容量受限于堆空间大小。一般通过软引用/弱引用来存储缓存对象。
即当堆内存不足时,可以强制回收这部分内存释放堆内存空间。一般使用堆缓存存储较热的数据。可以使用Guava Cache、Ehcache 3.x、 MapDB实现。
参考技术A 内存有什么缓存?是不是搞错了?没有这个说法的。会不会是用内存作硬盘的缓存,超级兔子有这项功能的。 参考技术B 楼主问的是虚拟内存吧?如果不运行些大的软件,是没什么问题的!
如果要玩大型游戏,或者使用其他3D软件就有必要设置了.
一般虚拟内存视物理内存大小而定,2~3倍这样,并且不能设置c盘.本回答被提问者和网友采纳 参考技术C 哦
手写实现一致性Hash算法
一致性hash详解
互联网公司的分布式高并发系统有什么特点?
高并发
海量数据
 高并发问题如何处理?
高并发问题如何处理?
应用集群
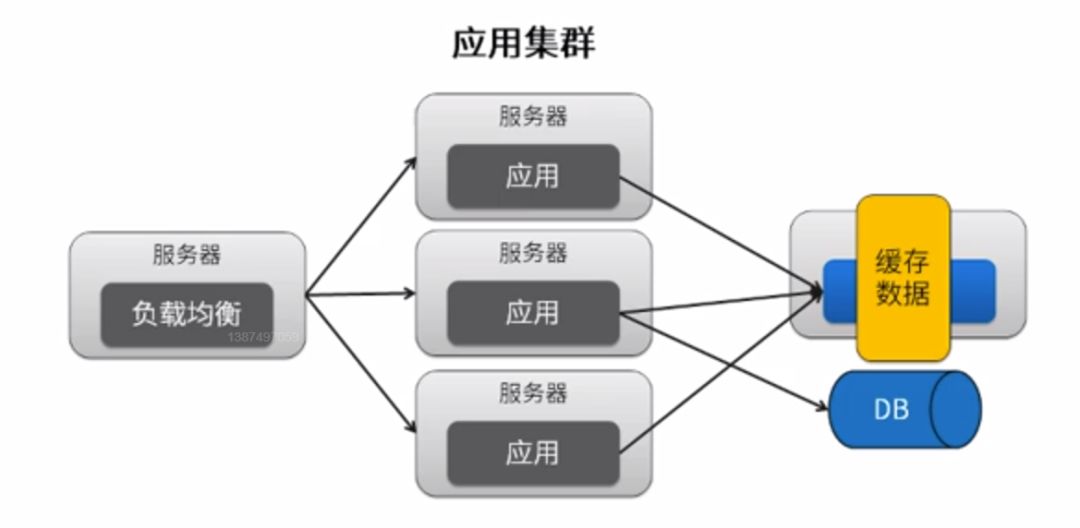
单机缓存能扛起高并发吗?Redis、Memcache的并发能力有多强?
很强,10W并发
如果并发量达30W怎么办?
缓存集群
海量数据对缓存有什么影响?海量数据,要缓存的数据量也很大,会超出单机内存容量,怎么办?
缓存集群
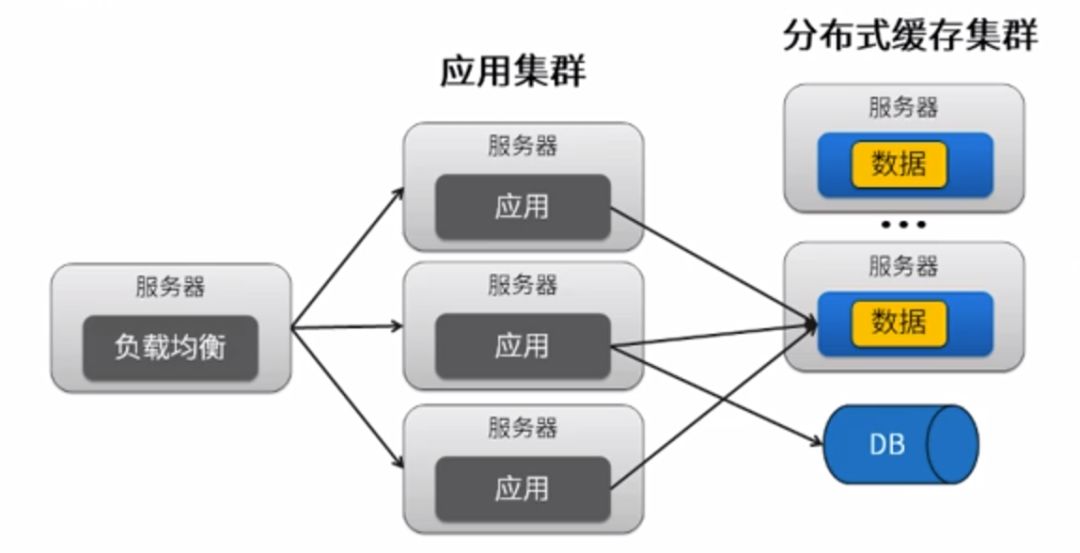
数据如何均衡分布到缓存集群的节点上?
均衡分布方式一: hash(key)%集群节点数

示例: 3个节点的集群, 数据 data:888
均衡分布式方法二:一致性Hash算法
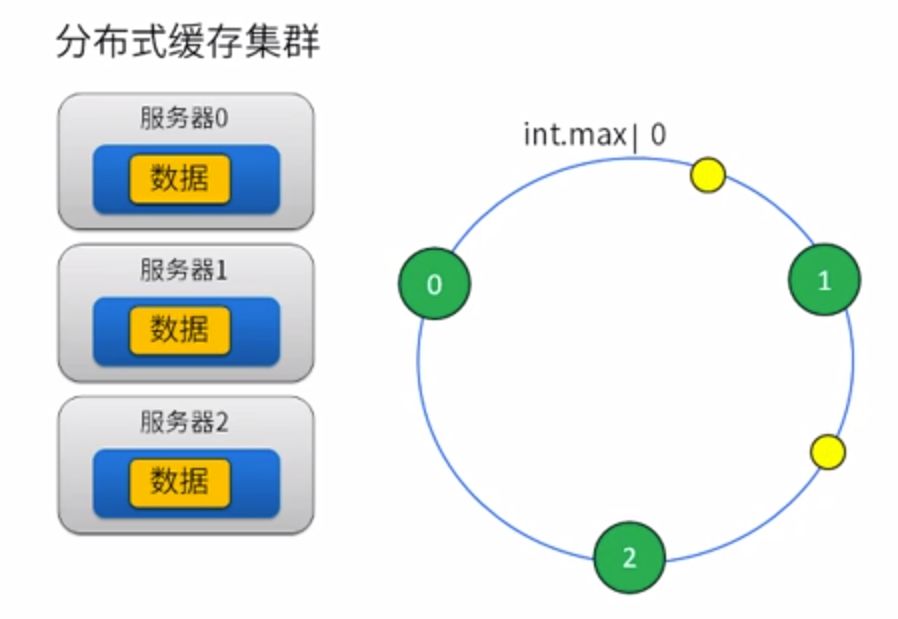
hash值一个非负整数,把非负整数的值范围做成一个圆环;
对集群的节点的某个属性求hash值(如节点名称),根据hash值把节点放到环上;
对数据的key求hash,一样的把数据也放到环上,按顺时针方向,找离它最近的节点,就存储到这个节点上。
均衡分布式方法二:一致性Hash算法 + 虚拟节点
假设:hash(data)= 200
则数据放到服务器2上 (200 % 3 = 2)
搞促销活动,临时增加一台服务器来提高集群性能,方便扩展吗?
hash(data)= 200; 200 % 4 = 0
增加一个节点后,有多大比例的数据缓存命不中
3 ---> 4 3/4 命不中
99 ---> 100 99% 命不中
大量缓存命不中,就会访问数据库,瞬时失去了缓存的分压,数据库不堪重负,崩溃!这就是缓存雪崩。
这种情况怎么办?
加班! 凌晨3-4点来扩容,并预热数据!
增加一个节点,影响多大?
0 ~ 1/3, 取均值,也就是 1/6
新增节点能均衡缓解原有节点的压力吗?
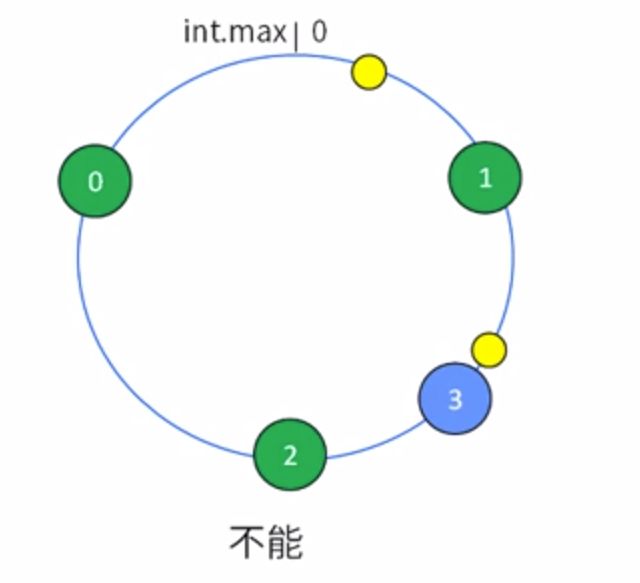
集群的节点一定会均衡分布在环上吗?
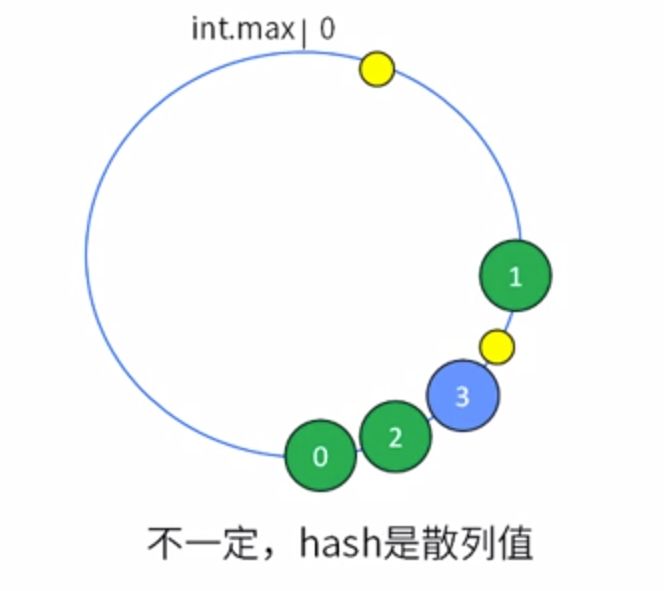
如何做到均衡分布,均衡缓解?
基于一致性Hash算法做优化,添加虚拟节点
新增节点后,对数据的影响比例有多大?
3 ---> 4 1/4命不中 ...... 1/N 命不中
那么接下来我们就来实现 一致性hash算法+虚拟节点。
一致性hash算法实现
hashCode(),不够散列,会有负值(取绝对值可以解决)
其他hash算法:比如 CRC32_HASH、FNV1_32_HASH、KETAMA_HASH等,其中KETAMA_HASH是默认的MemCache推荐的一致性Hash算法。
这里我们介绍 FNV1_32_HASH算法的实现:
public class FNV1_32_HASH {public static int getHash(String str) {final int p = 16777619;int hash = (int)2166136261L;for(int i = 0; i < str.length(); i++)hash = (hash ^ str.charAt(i)) * p;hash += hash << 13;hash ^= hash >> 7;hash += hash << 3;hash ^= hash >> 17;hash += hash << 5;// 如果算出来的值为负数则取其绝对值if (hash < 0)hash = Math.abs(hash);return hash;}}
虚拟节点放到环上,具体是要做什么?
根据Hash值排序存储
排序存储要被快速查找
这个排序存储还要能方便变更(增加或删减节点)
要满足上面三个条件,有哪些存储结构能实现呢?
数组: 排好序存储,方便查找,但不方便变更;
链表: 变更方便,但查找效率低;
二叉树: 有一个缺点,平衡度不够(可能一直往一边增加节点);
红黑树: 优化后的二叉树,当二叉树不平衡时,会自动更换根节点,实现动态平衡。
TreeMap 就是红黑树的一种实现
public class ConsistenceHash {//物理节点集合private List<String> realNodes = new ArrayList<>();//物理节点与虚拟节点的对应关系, 存储的是虚拟节点的hash值private Map<String, List<Integer>> real2VirtualMap = new HashMap<>();private int virtualNums = 100;//排序存储结构 红黑树, key是虚拟节点的hash值,value是物理节点private SortedMap<Integer, String> sortedMap = new TreeMap<>();public ConsistenceHash() {}public ConsistenceHash(int virtualNums) {super();this.virtualNums = virtualNums;}//加入服务器的方法public void addServer(String node) {this.readNodes.add(node);String vnode = null;int i = 0, count = 0;List<Integer> virtualNodes = new ArrayList<>();//创建虚拟节点,并放到环上(排序存储)while(count < this.virtualNums) {i++;vnode = node + "&&" + i;int hashValue = FNV1_32_HASH.getHash(vnode);//防止hash碰撞if(!this.sortedMap.containsKey(hashValue)) {virtualNodes.add(hashValue);this.sortedMap.put(hashValue, node);count++;}}this.real2VirtualMap.put(node, virtualNodes);}//移除一个物理节点public void removeServer(String node) {List<Integer> virtualNodes = this.real2VirtualMap.get(node);if(virtualNodes != null) {for(Integer hash : virtualNodes) {this.sortedMap.remove(hash);}}this.real2VirtualMap.remove(node);this.realNodes.remove(node);}//找到数据的存放节点public String getServer(String key) {int hash = FNV1_32_HASH.getHash(key);//得到大于该hash值的所有虚拟节点mapSortedMap<Integer, String> subMap = sortedMap.tailMap(hash);//if(subMap == null) {return sortedMap.get(sortedMap.firstKey());}//取第一个keyInteger vhash = subMap.firstKey();//返回对应的服务器return subMap.get(vhash);}publc static void main(String[] args) {ConsistenceHash ch = new ConsistenceHash();ch.addServer("192.168.1.10");ch.addServer("192.168.1.11");ch.addServer("192.168.1.12");for(int i = 0; i < 10; i++)System.out.println("a" + i + " 对应的服务器," + ch.getServer("a" + i));}}
以上是关于关闭内存缓存对效能有影响吗的主要内容,如果未能解决你的问题,请参考以下文章