火山引擎 DataLeap 推出全链路智能监控报警平台
Posted 字节跳动数据平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了火山引擎 DataLeap 推出全链路智能监控报警平台相关的知识,希望对你有一定的参考价值。
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
随着大数据开发场景下需要运维管理的任务越来越多,在日常运维中开发者经常会面临以下几个问题:
-
任务多,依赖关系复杂:很难查找到重要任务的所有上游任务并进行监控。如果监控所有任务,又会产生很多无用报警,导致有用报警被忽视;
-
配置运维成本高:每个任务的运行情况不一样,承诺完成时间不一样,如果单独对每个任务设置监控,分析及人工对齐任务服务级别协议(SLA)成本非常高;
-
报警形式多样性:对于小时级的任务,不同时段的报警及时性要求不同,普通监控无法满足不同时段多样的报警需求。
为了帮助企业开发者更好地解决这一问题,及时平稳完成日常运维、高效保障数据质量,字节跳动数据平台开发套件数据开发团队自研了基于依赖关系的全链路智能监控报警——基线监控,它能根据任务运行情况,智能决策是否报警、何时报警、如何报警以及向谁报警,贯穿整条任务产出链路,避免出现环节缺失,保障链路完整性。目前基线监控已在字节跳动内部得到广泛使用,覆盖抖音、电商、广告等 100+个项目,服务级别协议(SLA)任务的基线监控覆盖率超过 80%。
当前,该能力已通过火山引擎 DataLeap 向企业开放。企业可以通过火山引擎 DataLeap 的基线监控功能,有效降低监控配置成本、避免无效报警及报警泛滥。

图:火山引擎 DataLeap 监控范围
火山引擎 DataLeap 默认监控的范围包括:基线保障任务及保障任务上游的所有任务。如上图所示,保障任务 D,E 及它们所有的上游节点都会纳入基线监控范围,而任务 C,F 不受基线监控。值得一提的是,火山引擎 DataLeap 的基线监控允许用户配置基线监控只覆盖“指定项目”下的任务,此时基线监控的范围就只包含了保障任务及这些项目下的上游任务。

图:火山引擎 DataLeap 基线监控整体架构
火山引擎 DataLeap 基线监控整体架构基线管理模块、基线实例生成、基线埋点检测等构成,各模块详细来看:
-
基线管理模块:负责基线创建、更新、删除等操作,管理基线元信息,包括保障任务,承诺时间,余量及报警配置等;
-
基线实例生成:火山引擎 DataLeap 每天定时触发生成基线实例,生成实例的同时根据保障任务,由下而上逐层遍历 (BFS)所有上游任务并生成基线监控埋点。
生成基线监控埋点的过程中,火山引擎 DataLeap 会计算每个任务节点的预测运行时长,承诺时间,预警时间,预警最晚开始时间,承诺最晚开始时间。此外,火山引擎 DataLeap 会给基线监控任务添加基线出错/变慢报警规则,当任务执行触发规则后,通过基础报警服务发送基线报警事件;
-
监控埋点校验:系统维护一个延迟队列,火山引擎 DataLeap 会根据校验时间点(预警最晚开始时间,承诺最晚开始时间以及破线加剧时间校验点),同时火山引擎 DataLeap 会定时触发监控埋点校验任务实例运行状态,如果在时间点实例未运行成功,产生基线预警/破线报警事件,发送报警。
未来,火山引擎 DataLeap 的研发人员将继续针对基线监控进行优化,如基线关键路径分析、基线实例生成效率优化等,不断提高基线监控算法性能,完善基线链路分析能力,提升用户体验,向企业级市场提供更强大的全链路监控运营服务。
点击跳转 大数据研发治理DataLeap 了解更多
火山引擎 DataLeap 一招教你避坑“数据开发”中的资源隔离问题
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
在离线数仓开发过程中,研发人员需要根据业务变化,在开发/生产环境中不断切换、解析、调试。以往,企业一般通过人工方式核验,但由于数据量大且类型不同,导致研发人员资源、精力投入大。
如何使同构代码在不同环境正确运行,避免因调试过程中的误操作,对生产环境直接造成数据负面风险,成为很多企业数仓研发团队的痛点之一。
近期,火山引擎 DataLeap 推出“项目参数管理”能力,即通过自定义项目参数分别设置开发、生产环境参数值,参数支持配置多种类型,包括 Region、DB、shecma、table、date 以及自定义等,且支持任务级别引用,快速帮助研发团队实现资源隔离。
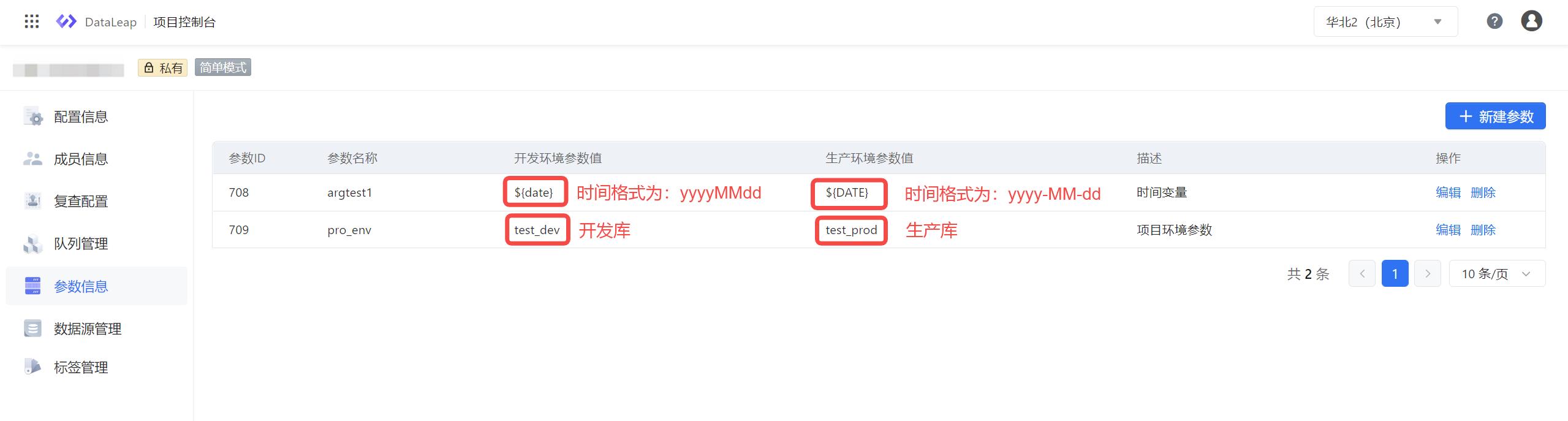
火山引擎 DataLeap“项目参数管理”能力
以湖仓一体分析服务(LAS)引擎为例,介绍如何利用“项目参数管理”区分不同环境库和时间格式的查询。
在使用之前,由于 1 个业务需求常常涉及 10+任务、30+参数,且不同环境 DB 中、table 基本一致,需要管理 2 套代码。数仓研发人员难以避免出现测试代码在生产环境执行、表误删、数据误删等问题。
在使用之后,只需要 3 个步骤即可解决生产、测试环境数据隔离问题:
-
步骤一: LAS 有 2 套环境,包括测试环境库 test_dev、生产环境库 test_prod 。2 套环境都有相同表名 LAS_table01、分区字段名 datetimes。开发环境分区字段为 yyyymmdd,生产环境分区格式为 YYYY-MM-DD。在 DataLeap 中设置日期参数 arg,开发环境参数值=$date、生产环境参数值=$DATE。设置库参数 env,开发环境=test_dev、生产环境=test_prod。
-
步骤二:对于离线数据开发任务,研发人员可以直接在代码中使用项目参数,点击“解析”“调试”,系统会自动替换为相应的开发环境参数值,并进行语法解析、权限检查等。
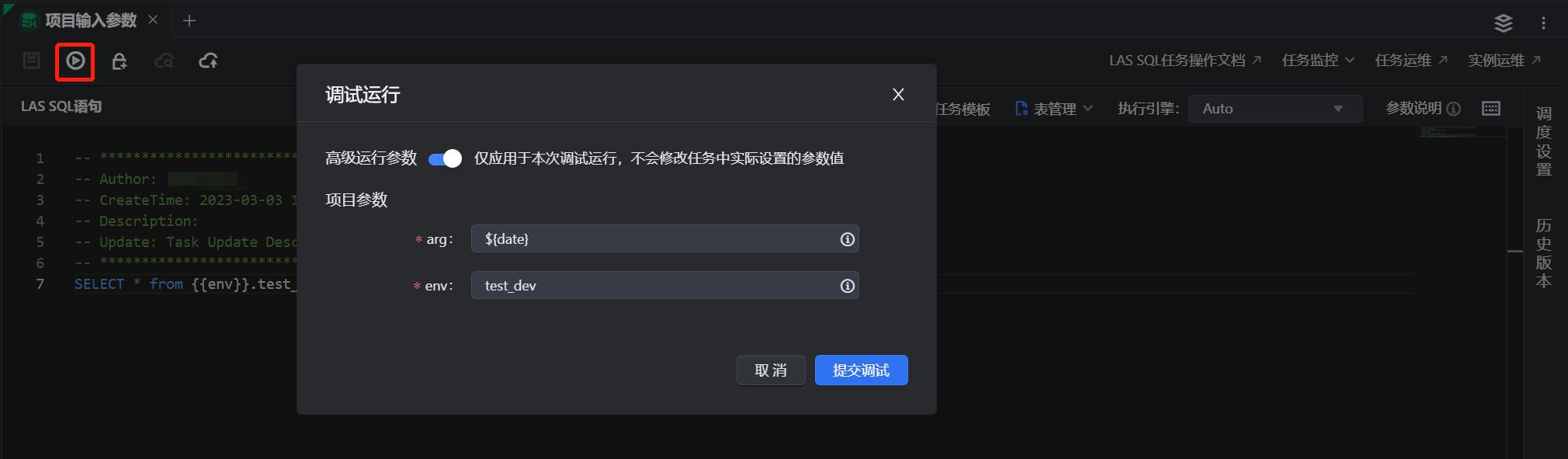
-
步骤三:点击“提交上线”、“任务例行执行”时,对于项目参数,系统会自动替换为相应的生产环境参数值,然后进行相应的语法解析以及权限检查。从而有效提升环境代码管理效率。
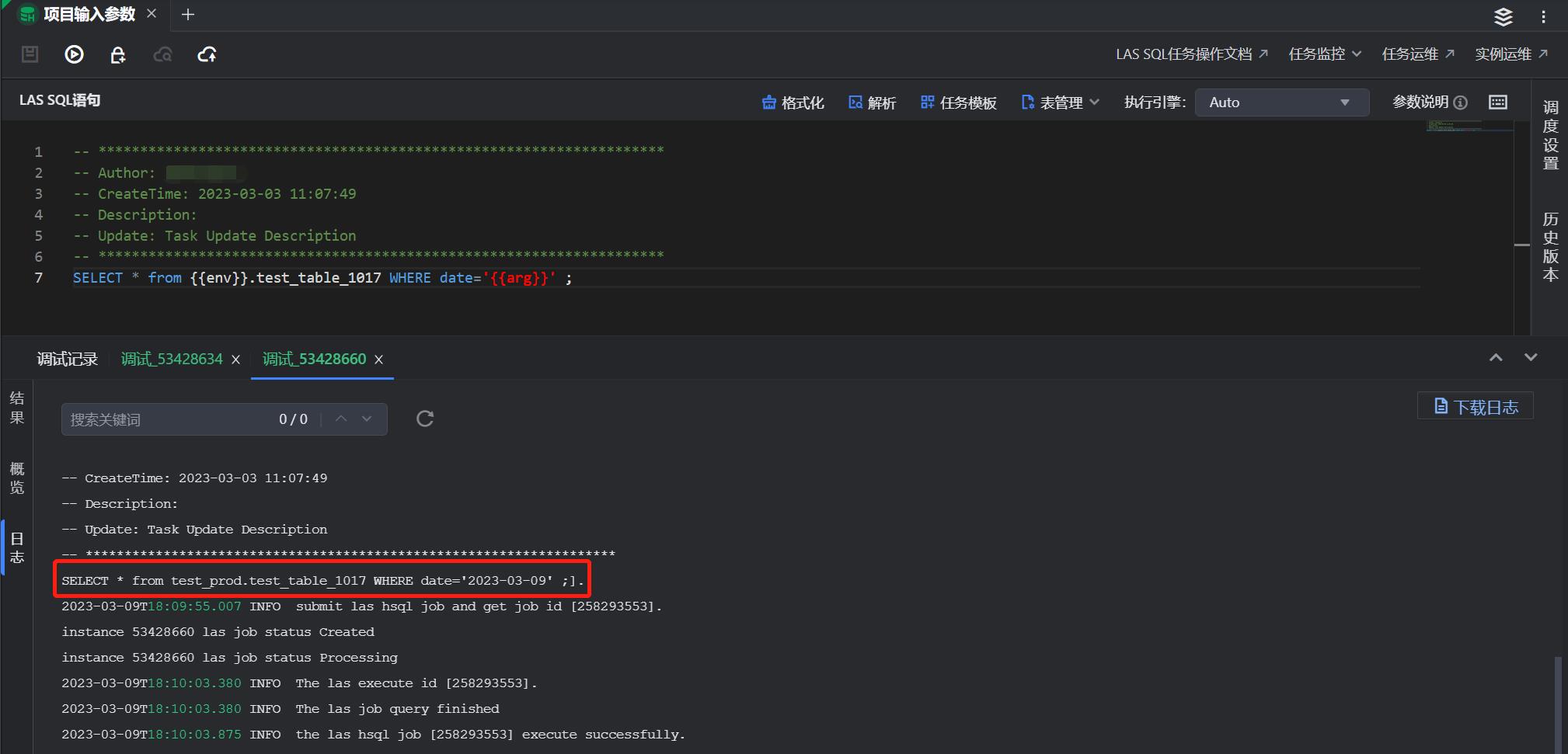
据介绍,企业可以在以下场景使用火山引擎 DataLeap“项目参数管理”能力:
【场景 1】开发生产环境隔离
-
以 HSQL 任务为例,为避免在开发测试阶段,因误操作影响生产库表的数据,研发人员可以在 HSQL 代码中使用项目参数。调试时,系统会自动替换为开发环境参数值;上线后的任务例行执行,系统将自动替换为生产环境参数值。同时,DataLeap 也支持代码一致,无需在上线前批量将开发环境的库表名称替换为生产环境的库表名称。
【场景 2】跨区域/项目代码同构
-
一般来说,不同 Region 下的库、表名不同。为了实现不同 Region、项目下代码同构,研发人员可以在 HSQL 代码中使用项目参数,来实现不同环境下,同一个任务的代码同构,有效提升环境代码管理效率。
火山引擎 DataLeap 让研发人员不再需要通过”调度设置-任务输入参数”的方式添加项目参数,只需定义一次参数即可轻松构建,并且实现生产、测试环境下的数据自动隔离,代码同构。除此之外,DataLeap 还具备数据集成、开发、运维、治理、资产、安全等数据中台建设能力,助力企业提升数据研发效率、降低管理成本,为数字化转型提供支撑。
点击跳转 大数据研发治理DataLeap 了解更多
以上是关于火山引擎 DataLeap 推出全链路智能监控报警平台的主要内容,如果未能解决你的问题,请参考以下文章
火山引擎DataLeap:3个关键步骤,复制字节跳动一站式数据治理经验
火山引擎DataLeap联合DataFun发布《数据治理知识地图》
火山引擎DataLeap数据调度实例的 DAG 优化方案 :功能设计