一.python 文件访问
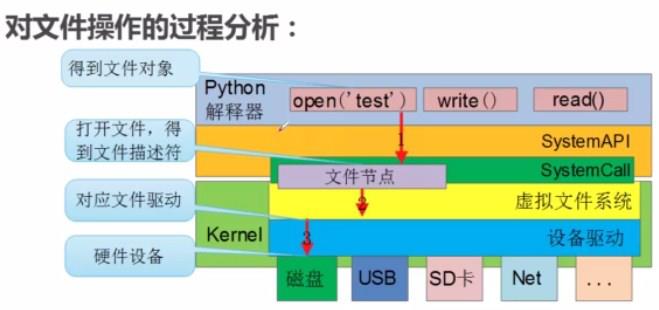
1.在python中要访问文件,首先要打开文件,也就是open
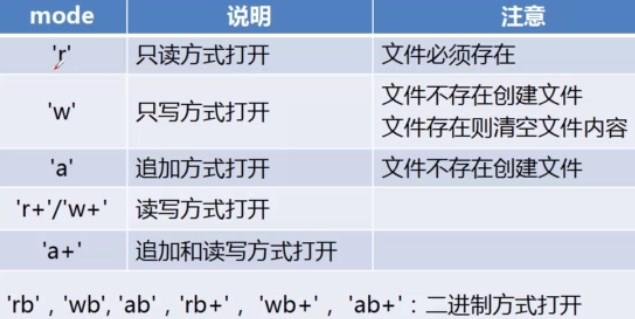
r: 只读
w: 只写 ,文件已存在则清空,不存在则创建
a:追加 ,写到文件末尾。如果文件存在,则在文件最后去追
加。文件不存在就去创建
+-:更新(可读可写)
r+ :以读写模式打开
w+ :以读写模式打开(参见w)
a+:以读写模式打开(参见a)
rb:以二进制读模式打开
wb:以二进制写模式打开
ab:以二进制追加模式打开(参见a)
rb+:以二进制读写模式打开(参见r+)
wb+:以二进制读写模式打开(参见w+)
ab+: 以二进制读写模式打开(参见a+)
2.打开文件。open打开文件 read读文件,close关闭文件
import codecs
fd = codecs.open(\'2.txt\')
print fd.read()
fd.close()
>>> 11111
2222
33333
aaaaa
bbbbb
cccccc
3.查看文件有哪些方法
import codecs
fd = codecs.open(\'b.txt\')
print fd.read()
print dir(fd)
fd.close()
>>> 11111
2222
333333
[\'close\', \'closed\', \'encoding\', \'errors\', \'fileno\', \'flush\', \'isatty\', \'mode\', \'name\', \'newlines\', \'next\', \'read\', \'readinto\', \'readline\', \'readlines\', \'seek\', \'softspace\', \'tell\', \'truncate\', \'write\', \'writelines\', \'xreadlines\']
1>fd.read() 方法,read()方法读取的是整篇文档。
fd = codecs.open(\'2.txt\')
text = fd.read()
print type(text)
>>><type \'str\'>
2>replace()函数替换文件中的某个元素。打开文件,读取后,对整个字符串进行操作.把2.txt 文件中的1替换成z
fd = codecs.open(\'2.txt\')
a1 = fd.read()
print a1
a2 = a1.replace(\'1\',\'z\')
print a2
>>> 11111
2222
33333
aaaaa
bbbbb
cccccc
zzzzz
2222
33333
aaaaa
bbbbb
cccccc
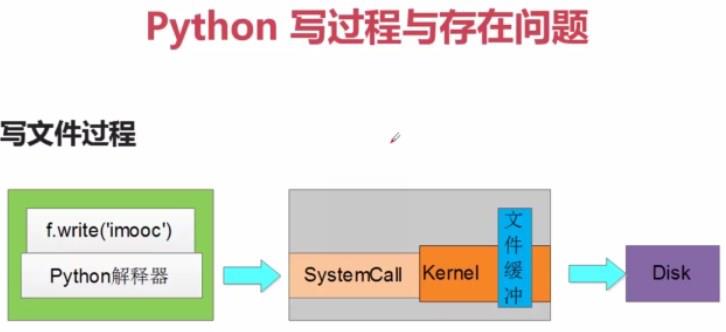
3> 写文件,codecs.open()函数,避免文件乱码
fd = codecs.open(\'3.txt\',\'w\')
fd.write(\'liuzhenchuan\\n\')
fd.write(\'hello world\\n\')
fd.write(\'xiaban\\n\')
fd.close()
>>> liuzhenchuan
hello world
xiaban
4>fd.readlines()方法,读取文件,最后把文件每行内容作为一个字符串放在一个list中
fd = open(\'3.txt\')
print fd.readlines()
fd.close()
>>> [\'liuzhenchuan\\n\', \'hello world\\n\', \'xiaban\\n\']
5>fd.readline()方法,读取文件,读取文件一行,类型为字符串
>>> l
6>#fd.readline()方法,读取文件一行内容,返回一个字符串. # fd.next()方法,读取文件下一行内容,返回一个字符串
fd = codecs.open(\'3.txt\',\'r\')
print fd.readline()
print fd.next()
fd.close()
>>> liuzhenchuan
hello world
7>#write()方法,必须传入一个字符串.
fd = codecs.open(\'5.txt\',\'w+\')
fd.write(\'a\\nb\\nc\\n\')
fd.close()
>>> a
b
c
#writelines()方法,必须传入一个列表/序列
fd = codecs.open(\'6.txt\',\'w\')
fd.writelines([\'123\\n\',\'234\\n\',\'345\\n\'])
fd.close()
>>> 123
234
345
8>with用法,不需要用fd.close()关闭文件
with codecs.open(\'3.txt\',\'rb\') as fd:
print fd.read()
fd.close()
>>> liuzhenchuan
hello world
xiaban
9>打印文件行号和文件内容
with codecs.open(\'2.txt\') as fd:
for line,value in enumerate(fd):
print line,value,
>>> 0 liuzhenchuan
1 hello world
2 xiaban
10>过滤文件某行的内容
with codecs.open(\'3.txt\') as fd:
for line,value in enumerate(fd):
if line == 3-2:
print value
>>> hello world
11>导入linecache模块,使用linecache.getline()方法,获取文件固定行的内容
import linecache
count = linecache.getline(\'3.txt\',1)
print count
>>> liuzhenchuan
当然,这种方法是普通的写入和读取,我们通常还有这样的问题,那就是字典啊,元祖啊,集合啊等对象,需要写入,但是读取的时候还是要按照原来的形式读取,并非上述方法中的字符串方式读取。那我们就可以使用pickle这个工具了:
首先要导入包
|
1
|
import pickle |
然后要进行代码的编写,这里要记住,写入文件模式是wb,读取时rb(b一般都是二进制,想必大家应该知道了,它的存储方式):
|
1
|
pick_file = open("pick.pick",\'wb\') |
如果此时,我们有一个集合:
|
1
|
list1 = [1,2,3,4,5,\'abd\',[\'a\',4,\'g\',\'d\']] |
则,我么可以这样存储:
|
1
2
|
pickle.dump(list1,pick_file)pickle.close() |
如果读取时候,我们可以这样做:
|
1
2
3
|
pick_file = open("pick.pick",\'wb\')list2 = pickle.load(pick_file)pickle.close() |