Python基础
Posted Richie Wen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础相关的知识,希望对你有一定的参考价值。
2.1 编程语言介绍
机器语言:
特点:用计算机能看懂的0和1去写程序
优点:程序运行速度快
缺点:开发效率非常低
汇编语言:
特点:用一些英文标签代替一串二进制来写程序
优点:比机器语言可阅读性强,操作系统大量使用汇编语言比如关于进程的调度(多道技术)代码就是汇编语言写的
缺点:没有摆脱二进制编程的本质,开发效率低
高级语言:
特点:用人能读懂的(英文)字符去写程序
优点:优点开发效率高
缺点:必须经过翻译才能让计算机识别,导致运行速度慢
总结:
运行效率从高到底
开发效率从低到高
学习难度从难到易
编译型:一次性翻译,拿编译后的结果直接给机器运行
eg:c语言,需求编译器(如gcc,glibc)
??编译只需要点一次??
解释型:一句一句解释成机器指令运行
eg:python,需求解释器(如Cpython)
2.2 执行python程序:
eg: pythpn3 C:\\test.py 1. 启动python解释器(内存中) 2. 将C:\\test.py内容从硬盘读入内存(这一步与文本编辑器是一样的) 3. 执行读入内存的代码
如果想要永久保存代码,就要用文件的方式
如果想要调试代码,就要用交互式的方式
2.3 变量
一个是“变”:核心在变化
一个是“量”:衡量,计量,表示一种状态
变量的定义
“变量名” + “赋值符号” + “变量的值”
eg: name=\'egon\'
变量定义规则:
- 变量名只能是字母、数字或下划线的任意组合
- 变量的第一个字符不能是数字
- 一下关键字不能声明为变量名[\'and\', \'as\', \'assert\', \'break\', \'class\', \'continue\', \'def\', \'del\', \'elif\', \'else\', \'except\', \'exec\', \'finally\', \'for\', \'from\', \'global\', \'if\', \'import\', \'in\', \'is\', \'lambda\', \'not\', \'or\', \'pass\', \'print\', \'raise\', \'return\', \'try\', \'while\', \'with\', \'yield\']
变量的修改
定义一个变量,存储的数据是变量值
变量名与变量值只是一种绑定关系,变量名本身没有存储值的功能
python
name=\'a\' # \'a\'这个值的引用计数+1
name=\'b\' # \'b\'这个值的引用计数+1,a这个值的引用计数-1
值的引用计数为0时,python解释器会定期回收这些值
-
变量定义的三个重要组成部分:
id(身份) 可用is/is not 判定
type
value(值) 可用\'==\'判定 -
小数池:python特性,用来存放长度较短的数字
常量:不变的量
python中没有常量的专门定义方式
通常用全部大写的变量名表示常量,仅仅只是一种提示效果
赋值
- 链式赋值
a=b=c=d=e=f=10 - 增量赋值
+=,-=.... - 交换赋值
x,y = y,x - 值的解压
```python msg = \'hello\'
a,b,c,d,e = msg
a,,,,e = msg
a,*,e = msg
```
2.4 程序交互
input
input默认接受的内容为字符串
python2中raw_input同python3的input,python2的input将输入的内容原封不动的传进来
2.5 格式化输出
%+字母
python
print(\'number:%d, string:%s\' % (123,\'str\'))
str.format()
在使用%+字母的地方换成{}, ```python
不加数字表示顺序输出
print(\'number:{}, string:{}\'.format(123,\'st\'))
将()中视作列表,使用索引输出
print(\'{2},{1},{0}\'.format(\'a\',\'b\',\'c\'))
亦可索引嵌套索引
print(\'{1[2]},{2},{0}\'.format(\'a\',(\'aa\',\'bb\',\'cc\'),[1,2,3]))
2.6 进制转换
十进制
0,1,2,3,4,5,6,7,8,9
二进制
0,1
bin()
八进制
0,1,2,3,4,5,6,7
oct()
十六进制
0,1,2,3,4,5,6,7,8,9,a,b,c,d,e
hex()
2.7 运算符
常规运算符:
+
-
*
**
/
//
%
字符串、列表是有序的可用+、*运算符
比较运算符:
is
>
\\<
>=
\\<=
\\==
!=
赋值运算符:
\\=
+=
-=
*=
\\/=
\\%=
**=
\\//=
逻辑运算:
and
or
in
not
2.8 流程控制
if
elif
elif
...
else
```python
score = input(\'>>: \')
score = int(score)
if score >= 90: print(\'A\') elif score >= 80: print(\'B\') elif score >= 70: print(\'C\') elif score >= 60: print(\'D\') else: print(\'E\') print(\'====>\') ```
2.9 循环控制
1.while循环
while 条件: 循环体的代码1 循环体的代码2 循环体的代码3 ```python
2.while循环打印0-9
count = 0 while count < 10: print(count) count += 1
3.while死循环打印ok
while True: #死循环 print(\'ok\')
4.while死循环打印ok2
while 1: #死循环 print(\'ok\')
5.break语句打印0-4
break:跳出本层循环 count = 0 while count < 10: if count == 5: break print(count) count += 1
6.continue语句不打印4,5,6
continue:跳出本次循环 0 1 2 3 7 8 9 count = 0 while count < 10: if count >=4 and count <=6: count += 1 continue print(count) count += 1
7.猜年龄(死循环无限猜)
OLDBOY_AGE = 56 while 1: age = input(\'猜一猜年龄>>: \') age = int(age)
if age > OLDBOY_AGE:
print(\'太大了\')
elif age < OLDBOY_AGE:
print(\'太小了\')
else:
print(\'猜对了\')
break
8.猜年龄2(猜三次)(循环条件控制)
OLDBOY_AGE = 56 count = 1 while count <= 3: age = input(\'猜一猜年龄>>: \') age = int(age)
if age > OLDBOY_AGE:
print(\'太大了\')
count += 1
elif age < OLDBOY_AGE:
print(\'太小了\')
count += 1
else:
print(\'猜对了\')
break
9.猜年龄3(猜三次)(循环体if控制)
OLDBOY_AGE = 56 count = 1 while True: if count > 3: print(\'您猜的次数超过限制\') break age = input(\'猜一猜年龄>>: \') age = int(age)
if age > OLDBOY_AGE:
print(\'太大了\')
elif age < OLDBOY_AGE:
print(\'太小了\')
else:
print(\'猜对了\')
break
count += 1
10.分数变成绩
while True: score = input(\'>>: \') score = int(score)
if score >= 90:
print(\'A\')
if score >= 80:
print(\'B\')
if score >= 70:
print(\'C\')
if score >= 60:
print(\'D\')
if score < 60:
print(\'E\')
11.猜年龄4(循环体if控制)(优化版本)
OLDBOYAGE = 56 count = 0 while True: if count > 2: break age = input(\'猜一猜年龄>>: \') age = int(age) if age > OLDBOYAGE: print(\'太大了\') if age < OLDBOYAGE: print(\'太小了\') if age == OLDBOYAGE: print(\'猜对了\') break count += 1 ```
for循环
不依赖索引
for 单项 in 序列:
循环体
python
for item in dict:
print(dicr[item])
for i in range(10,0,-2)
print(i)
2.10 基本数据类型
数据是用来表示状态的,不同的状态就应该用不同的类型的数据去表示。
编程就是为了模拟人的活动并替人工作,所以需要能够识别人类的信息,对应的就是不同数据结构表示不同的状态。
数字
整型int
eg:年级,年纪,等级,身份证号,QQ号,手机号
level=10
浮点型float
eg:身高,体重,价格,薪资,温度
height=1.73
salary=4.4
字符串str
包含在引号(单、双、三)里面,由一串字符组成
eg:姓名,性别,地址,学历,密码
name = \'chuck\'
基本使用:
- 长度len
name = \'chuck\' print(len(name)) - 索引
print(name[2]) 注:只读,不可写 - 切片
print(name[2:])
常用方法
```python
!/usr/bin/python
coding=utf-8
import string
strip
name = \'chuck\' print(name.strip(\'\')) print(name.lstrip(\'\')) print(name.rstrip(\'\'))
startwith, endwith判断开头结尾的字符是否符合
name = \'handsome_chuck\' print(name.endswith(\'ck\')) print(name.startswith(\'hand\'))
replace替换字符
name = "Egon say :i don\'t have one tesla, my name is egon" print(name.replace(\'egon\', \'SB\', 1))
format格式化
print(\'name:{}, age:{}, gender:{}\'.format(\'chuck\', 18, \'male\')) print(\'{1}, {0}, {1}\'.format(\'chuck\', 18, \'male\')) print(\'{name}, {age}, {gender}\'.format(gender=\'male\', name=\'chuck\', age=18))
find, rfind, index, rindex, count
sentence = \'chuck say hello to everyone\' print(sentence.find(\'o\')) # 从左开始寻找符合的字符串 print(sentence.rfind(\'o\')) # 从右开始寻找符合的字符串 print(sentence.index(\'o\')) # 从左开始寻找符合的字符串,找不到报异常 print(sentence.rindex(\'o\')) # 从右开始寻找符合的字符串,找不到报异常 print(sentence.count(\'o\')) # 对符合条件的字符串计数
split分割字符串为多串字符串
name = \'root:x:0:0::/root:/bin/bash\' print(name.split(\':\')) name = \'C:/a/b/c/d.txt\' print(name.split(\'/\', 1)) name = \'a|b|c\' print(name.rsplit(\'|\', 1))
join将多串字符串链接为单个字符串
tag = \' \' print(tag.join([\'chuck\', \'say\', \'hello\', \'to\', \'world\']))
is数字系列
num1 = b\'4\' num2 = u\'4\' num3 = \'四\' num4 = \'Ⅳ\'
isdigt:bytes,unicode
print(num1.isdigit()) print(num2.isdigit()) print(num3.isdigit()) print(num4.isdigit())
isdecimal:unicode
print(num2.isdecimal()) print(num3.isdecimal()) print(num4.isdecimal())
isnumberic:unicode,中文数字,罗马数字
print(num2.isnumeric()) print(num3.isnumeric()) print(num4.isnumeric()
上三者皆不可判断浮点数
num5 = \'4.5\' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric())
总结:
最常用的是isdigit,可以判断bytes和unicode类型,整型数字,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric
```
扩展方法
```python
is其他
print(\'=\' * 20) name = \'SB1234\' print(name.isalnum()) # 只能是字母数字 print(name.isalpha()) # 只能是字母 print(name.isidentifier()) # 是否包含关键字 print(name.islower()) # print(name.isupper()) print(name.isspace()) print(name.istitle())
center, ljust, rjust, zfill
name = \'the best chuck\' print(name.center(30, \'=\')) # 将目标字符串在指定长度的字符串里居中 print(name.ljust(30, \'\')) # 将目标字符串在指定长度的字符串里靠左对齐 print(name.rjust(30, \'\')) # 将目标字符串在指定长度的字符串里靠右对齐 print(name.zfill(30))
expandtabs 将制表符转换成空格
name = \'chuck\\thello\' print(name) print(name.expandtabs(1))
lower, upper
info = \'Chuck is belong to NASA.\' print(info) print(info.lower()) # 将字符串全部小写 print(info.upper()) # 将字符串全部大写
captalize, swapcasw, title
print(info.capitalize()) # 仅第一个字符大写 print(info.swapcase()) # 字符串中大写变小写,小写变大写 print(info.title()) # 字符串每个单词首字母大写
```
列表list
以上都只是一个对象可处理,列表可以存多个对象,可以对多个对象进行处理(可变类型)
eg:爱好,装备,购物车
hobby = [\'paly\', \'eat\', \'sleep\']
基本使用
- 索引
l = [1,2,3,4]
print(l[2],l[3]) -
切片
```python l = [1,2,3,4,5,6,7,8,9] print(l[1:4])
print(l[1:5:2])\'2\'为指定步长
print(l[-1]) print(l[]) ```
-
包含
l = [1,2,3,4,5] printf(2 in l) -
list.index(x)
返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。```python
print(l.index(2)) 1 ```
常用方法
- list.append(x)
把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 l.append(6) -
list.extend(L)
将一个给定列表中的所有元素都添加到另一个列表中,相当于 a[len(a):] = L。 -
list.insert(i, x)
在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x)。 -
list.remove(x)
删除列表中值为 x 的第一个元素,返回None,如果没有这样的元素,就会返回一个错误。 -
list.pop([i])
从列表的指定位置删除元素,并将其返回。如果没有指定索引,a.pop() 返回最后一个元素。元素随即从列表中被删除(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在Python 库参考手册中遇到这样的标记)。
扩展方法
-
list.clear()
从列表中删除所有元素。相当于 del a[:]。 -
list.count(x)
返回 x 在列表中出现的次数。 -
list.sort(self,key,reverse)
对列表中的元素就地进行排序。key为指定关键字排序,reverse指定正序或倒序 -
list.reverse()
就地倒排列表中的元素。 -
list.copy()
返回列表的一个浅拷贝。等同于 a[:]。
模拟堆栈
列表方法使得列表可以很方便的做为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。
可用list.insert(i,x)&list.pop()
list.append(x)&list.pop()
两种方法模拟
模拟队列
你也可以把列表当做队列使用,队列作为特定的数据结构,最先进入的元素最先释放(先进先出)。不过,列表这样用效率不高。相对来说从列表末尾添加和弹出很快;在头部插入和弹出很慢(因为,为了一个元素,要移动整个列表中的所有元素)。
要实现队列,使用 collections.deque,它为在首尾两端快速插入和删除而设计。 ```python
from collections import deque queue = deque(["Eric", "John", "Michael"]) queue.append("Terry") # Terry arrives queue.append("Graham") # Graham arrives queue.popleft() # The first to arrive now leaves \'Eric\' queue.popleft() # The second to arrive now leaves \'John\' queue # Remaining queue in order of arrival deque([\'Michael\', \'Terry\', \'Graham\']) ```
列表推导式
列表推导式不局限于列表中使用
```python l1 = [x**2 for x in range(10)]
l1、l2等价
l2 = [] for x in range(10): x **= 2 l2.apeend(x)
l3 = [x2 if x%2==0 else x3 for x in range(10)]
l3、l4等价
l4 = [] for x in range(10): if x % 2 == 0: x **= 2 else: x **= 3 l4.append(x) ```
嵌套的列表推导式
```python
matrix = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] [[row[i] for row in matrix] for i in range(4)]
等价于:
transposed = [] for i in range(4): transposed.append([row[i] for row in matrix])
等价于:
transposed = []
for i in range(4): transposedrow = [] for row in matrix: transposedrow.append(row[i]) transposed.append(transposed_row)
终极简版:
list(zip(*matrix)) ```
zip():需求多个等长序列,将每个序列的同等索引位的元素组合成元组,并返回元组组合的列表
元组tuple
元组就像字符串, 不可变的。通常包含不同种类的元素并通过分拆(参阅本节后面的内容) 或索引访问(如果是 namedtuples,甚至可以通过属性)。用来做查询功能,不具有其他功能,可以节省内存。
- 元组可以作为字典的key
```python
d = {(1,2,3): \'egon\'}
print(d, type(d), d[(1,2,3)])
```
-
元组不可变,但元组内部的元素可以是可变类型
python t = (1,[\'a\',\'b\'],\'sss\',(1,2)) t[1][0] = \'A\' print(t)
字典dict
字典以 关键字 为索引,关键字可以是任意不可变类型,通常用字符串或数值。
如果元组中只包含字符串和数字,它可以做为关键字,如果它直接或间接的包含了可变对象,就不能当做关键字。不能用列表做关键字,因为列表可以用索引、切割或者 append() 和 extend() 等方法改变。
{键key:键值value}
key只能用不可变数据类型,键值value无限制
可以看做无序的键: 值对 (key:value 对)集合
取值:
python
print(dict[key])
print(dict.get(\'key\', object))
常用方法
-
存/取
- dict.get(self,k,default),返回k的value,失败返回设定的default,不报错
- dict.pop(self,k,default),返回k的value,失败返回default
- dict.popitem(self),返回key&value
python info_dict = {\'name\':\'chuck\', \'age\':18, \'sex\':\'male\'} print(info_dict[\'name\']) info_dict[\'level\'] = 10 info_dict.get[\'ann\',None] info_dict.pop[\'sex2\', None] info_dict.popitem() -
删除
python del info_dict[\'name\'] - dict.keys(self)
- dict.items(self)
- dict.values(self)
-
循环取值
```python for k in infodict: print(k, infodict[k]) for k in info_dict.keys: print(k, infodict[k]) for val in infodict.values: print(val)
for items in infodict.items: # items = (key, value) print(items) for k,v in infodict.items: # 将元组items的值解压出来给k,v
print(k, v) ``` - 长度用len()求取
- 包含in
- dict.update(kwargs) ()中接收一个字典,比对两个字典,相同的key取第二个字典的value,原字典没有的key&value补充进原字典
-
dict.setdefault(k, default)
- key不存在则添加key,其值为default,若存在,不新建key,default不起任何作用
python info_dict.setdefault(\'hobbyies\',[]).append(\'study\') -
dict.copy(self)
python d = info_dict.copy() - dict.clear() 清空字典
- dict.fromkeys(seq, value)
seq接收一个序列,将序列的每一个值作为key,对应相同的一个value,组合成一个字典。dict不对应任何一个具体的字典。 - dict.get(k, default)
取key为k的value,无则返回default
循环使用
-
while()
python while True: pass while 1: pass - for
不依赖索引的取值
```python
for item in dict:
print(dicr[item])
for i in range(10,0,-2)
print(i)
```
-
items()
- 循环字典时关键字和对应的值可以同时解读出来:
python knights = {\'gallahad\': \'the pure\', \'robin\': \'the brave\'} for k, v in knights.items(): print(k, v) -
enumerate()
- 在序列中循环时,索引位置和对应值可以同时得到:
python for i, v in enumerate([\'tic\', \'tac\', \'toe\']): print(i, v) -
同时循环两个或更多的序列,可以使用 zip() 整体打包:
python questions = [\'name\', \'quest\', \'favorite color\'] answers = [\'lancelot\', \'the holy grail\', \'blue\'] for q, a in zip(questions, answers): print(\'What is your {0}? It is {1}.\'.format(q, a)) -
逆向循环序列
- 先正向定位序列,然后调用 reversed() 函数:
python for i in reversed(range(1, 10, 2)):
布尔bool
True:1
False:0
集合set
作用:去重,关系运算
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。集合对象还支持 union(联合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等数学运算。
大括号或 set() 函数可以用来创建集合。注意:想要创建空集合,你必须使用 set() 而不是 {}。
集合元素的原则:
1. 每个元素必须是不可变类型
2. 没有重复的元素
3. 无序
关系运算
- in ¬ in
-
并集 |
- set.union([set])
python l1 = {1,2,3,4,5,7,8,90,0} l2 = {1,3,56,8,0,6,4,8,5} s = l1 | l2 -
交集 &
- set.intersection([set])
python s2 = l1 & l2 -
差集 -
- set.difference([set])
python s3 = l1 - l2 s4 = l2 - l1 -
对称差集 ^
- set.symmetric_difference([set])
python s5 = l1 ^ l2 -
for
python for item in l1: print l1 -
解压
python a, *_ = l1 -
==
python set1={1,2,3} set2={1,2,3} print(set1 == set2) -
>,>= ,<,<= 父集,子集
python set1={1,2,3,4,5} set2={1,2,3,4} print(set1 >= set2) print(set1.issuperset(set2)) print(set2 <= set1) print(set2.issubset(set1))
主要方法
-
set.add(val)
- set类型为可变类型,但是只能添加不可变类型
-
set.pop()
- 随机删除某个元素并返回删除删除元素
-
set.remove(val)
- 指定删除某个元素,若无该元素则报错
-
set.discard(val)
- 指定删除某个元素,元素不存在不会报错
扩展
- set.update([set])
- set.cpoy()
- set.clear()
-
set.difference_update([set2])
- set 与set2的差集替换set,但不改变set的id
可变数据类型与不可变数据类型
-
可变数据类型:不可哈希类型,列表,字典,deque,
- id不变的时候,数据类型内部元素的value可变
- 这些元素可以存多个对象,并且修改这些对象
-
不可变数据类型:可哈希类型,数值,字符串,bool,元组
- value改变,id也跟着改变
```python
num = 10 id(num) 1793701216 type(num) <class \'int\'> num 10 num=\'abc\' id(num) 37460331576 type(num) <class \'str\'> num \'abc\' x=1.3 id(x) 37457305864 type(x) <class \'float\'> x=2.3 id(x) 37457305888 type(x) <class \'float\'> x = \'hello\' id(x) 37464353344 type(x) <class \'str\'> x[0] \'h\' ```
字符编码
前言
- 文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失。
因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。
在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。 -
python解释器执行py文件的原理 ,例如python test.py
- 第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
- 第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
- 第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
-
总结:
python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样。
与文本编辑器不一样的地方在于,python解释器不仅可以读文件内容,还可以执行文件内容。
什么是字符编码
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字,编程的目的是让计算机干活,而编程的结果说白了只是一堆字符,也就是说我们编程最终要实现的是:一堆字符驱动计算机干活。
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
以下两个场景下涉及到字符编码的问题:
1. 一个python文件中的内容是由一堆字符组成的
2. python中的数据类型字符串是由一串字符串组成的
字符编码的发展史
ASCII
- 计算机起源阶段,仅有将英文进行编码
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-(2^8-1)种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
GBK和其他编码
- 使用其他语言的国家,自行定制编码
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
unicode&UTF-8
- 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言。
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)。
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes。 -
unicode VS UTF-8
-
unicode:简单粗暴,所有字符都是2Bytes,
- 优点是字符->数字的转换速度快,
- 缺点是占用空间大
-
utf-8:精准,对不同的字符用不同的长度表示,
- 优点是节省空间,
- 缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
-
unicode:简单粗暴,所有字符都是2Bytes,
所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
字符编码分类--字符编码的使用
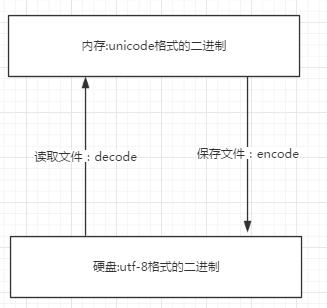 - 文件执行的过程:
- 文件执行的过程:
某个能打开文件的程序启动--->将需要打开的文件从硬盘加载进内存--->程序按照自己的规则操作文件
-
字符编码会在两个阶段使用:
- 文件从硬盘加载进内存 & 文件从内存存入硬盘
- 程序按照自己的规则操作文件
- 内存默认编码格式为Unicode
- 硬盘通常使用UTF-8格式
结论: 1. 文件以什么编码encode的,就以什么编码decode 2. python3默认的解码格式是UTF-8,可以在文件头更改 3. python2默认解码格式是ASCII,可以在文件头更改 4. python2默认字符串格式为默认文件解码格式encode之后的bytes,可以手动加上u改为Unicode 5. python3默认字符串格式为Unicode,可以使用encode方法改成其他编码格式的bytes
文件从硬盘加载进内存 & 文件从内存存入硬盘
notepad++
分析过程?什么是乱码
文件从内存刷到硬盘的操作简称存文件
文件从硬盘读到内存的操作简称读文件
- 乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败,用open函数的write可以测试,f=open(\'a.txt\',\'w\',encodig=\'shift_jis\')
f.write(\'你瞅啥\\n何を見て\\n\') #\'你瞅啥\'因为在shiftjis中没有找到对应关系而无法保存成功,只存\'何を見て\\n\'可以成功
但当我们用文件编辑器去存的时候,编辑器会帮我们做转换,保证中文也能用shiftjis存储(硬存,必然乱码),这就导致了,存文件阶段就已经发生乱码
此时当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
- 乱码二:存文件时不乱码而读文件时乱码
存文件时用utf-8编码,保证兼容万国,不会乱码,而读文件时选择了错误的解码方式,比如gbk,则在读阶段发生乱码,读阶段发生乱码是可以解决的,选对正确的解码方式就ok了,而存文件时乱码,则是一种数据的损坏。
pycharm
reload与convert的区别:
pycharm非常强大,提供了自动帮我们convert转换的功能,即将字符按照正确的格式转换
要自己探究字符编码的本质,还是不要用这个
我们选择reload,即按照某种编码重新加载文件
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
- 以GBK编码写入一段汉字保存,以UTF-8打开,显示乱码
- 以utf编码写入一段汉字保存,以GBK打开正常显示
- 以GBK编码写入一段汉字保存,在文件开头指定解码格式(coding:utf-8),正常显示
程序按照自己的规则操作文件-----探究python3和python2的字符串的编码
python3:
name = "林" # 整行字符都是以Unicode格式的二进制存在内存中,python解释器解释到赋值符"="时,新开辟一个内存空间的时候,以Unicode格式的二进制将”林“存进这个新开辟的内存空间
python2:
name = "林" # 整行字符都是以Unicode格式的二进制存在内存中,python解释器解释到赋值符"="时,新开辟一个内存空间的时候,都是已经encode后的格式存进去,即bytes,bytes是unicode格式encode之后的结果,encode的编码格式取决于文件开头指定的编码格式,若没有指定则为ANSCII编码
python2中字符串有两种形式:
1. str=bytes
2. u""
python3中字符串也有两种形式:
1. u""
2. bytes
数据传输必须用bytes
bytes来自于Unicode格式的二进制按照默认的编码格式encode之后的结果,默认的编码格式来自于文件开头指定的编码格式
以上是关于Python基础的主要内容,如果未能解决你的问题,请参考以下文章