python全栈开发第十篇Python常用模块二(时间randomossys和序列化)
Posted 呆萌小河马的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python全栈开发第十篇Python常用模块二(时间randomossys和序列化)相关的知识,希望对你有一定的参考价值。
一、time模块
表示时间的三种方式:
时间戳:数字(计算机能认识的)
时间字符串:t=\'2012-12-12\'
结构化时间:time.struct_time(tm_year=2017, tm_mon=8, tm_mday=8, tm_hour=8, tm_min=4, tm_sec=32, tm_wday=1, tm_yday=220, tm_isdst=0)像这样的就是结构化时间
#time模块的常用方法及三种时间之间的转换
import time
# 对象:对象.方法
# ----------------------------------
# 1.时间戳(数字):给计算机的看的
print(time.time())#当前时间的时间戳
print(time.localtime())#结构化时间对象
s=time.localtime() #当前的结构化时间对象(utc时间)
print(s.tm_year)
s2=time.gmtime() #这个和localtime只是小时不一样
print(s2)
#-----------------------------------
# 2.时间的转换
print(time.localtime(15648461))#把时间戳转换成结构化时间
t=\'2012-12-12\' #这是一个字符串时间
print(time.mktime(time.localtime()))#将结构化时间转换成时间戳
print(time.strftime("%Y-%m-%d",time.localtime()))#将结构化时间转换成字符串时间
print(time.strftime(\'%y/%m/%d %H:%M:%S\'))#小写的y是取得年的后两位
print(time.strptime(\'2008-03-12\',"%Y-%m-%d"))#将字符串时间转换成结构化时间
#python中时间日期格式化符号: %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
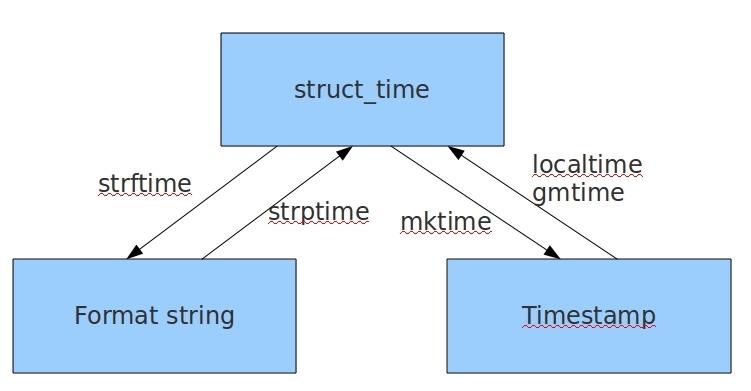
time.strftime(\'格式定义\',‘结构化时间’) 结构化时间参数若不传,则显示当前时间
print(time.strptime(\'2008-03-12\',"%Y-%m-%d"))
print(time.strftime(\'%Y-%m-%d\'))
print(time.strftime("%Y-%m-%d",time.localtime(15444)))
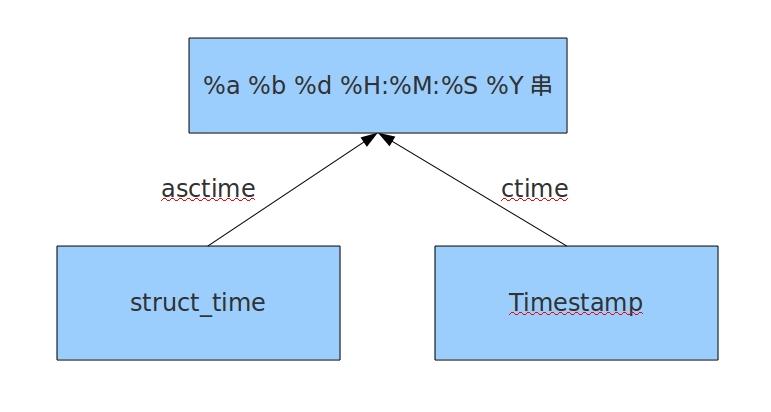
asctime和ctime方法
print(time.asctime(time.localtime(150000))) print(time.asctime(time.localtime())) # time.ctime(时间戳)如果不传参数,直接返回当前时间的格式化字符串 print(time.ctime()) print(time.ctime(150000))
二、random模块
# random的方法 import random # ---------------------------- # 1.随机小数 print(random.random()) #大于0且小于1之间的随机小数 print(random.uniform(1,3)) #大于1且小于3的随机小数 # ---------------------------- # 2.随机整数 print(random.randint(1,5)) #大于1且小于等于5之间的整数 print(random.randrange(1,10,2)) #大于等于1且小于3之间的整数(且是所有的奇数) # ---------------------------- # 3.随机选择一个返回 print(random.choice([1,\'23\',[4,5]])) # ---------------------------- # 4.随机选择返回多个 print(random.sample([1,\'23\',[4,5]],2)) #列表元素任意两个组合 # ---------------------------- # ---------------------------- # 5.打乱列表顺序 item=[1,5,2,3,4] random.shuffle(item) #打乱次序 print(item)
# 验证码小例子(这个只是产生随机的四位数字) # 方法一、 # l=[] # for i in range(4): # l.append(str(random.randint(0,9))) # print(\'\'.join(l)) # print(l) # 方法二 # print(random.randint(1000,9999)) # 验证码升级版 # 要求:首次要有数字,其次要有字母,一共四位,可以重复 # chr(65-90)#a-z # chr(97-122)#A-Z 方法一 # num_list = list(range(10)) # new_num_l=list(map(str,num_list))#[\'0\',\'1\'...\'9\'] # l=[] #用来存字母 # for i in range(65,91): # zifu=chr(i) # l.append(zifu) #[\'A\'-\'Z\'] # new_num_l.extend(l) #要把上面的数字和下面的字母拼在一块 # print(new_num_l) # ret_l=[] #存生成的随机数字或字母 # for i in range(4): #从new_num_l里面选数字选择四次就放到了ret_l里面) # ret_l.append(random.choice(new_num_l)) # # print(ret_l) # print(\'\'.join(ret_l)) #拼成字符串 方法二 # import random # def myrandom(): # new_num_l=list(map(str,range(10))) # l=[chr(i) for i in range(65,91)] # new_num_l.extend(l) # ret_l=[random.choice(new_num_l) for i in range(4)] # return \'\'.join(ret_l) # print(myrandom()) 方法三 import random l=list(str(range(10)))+[chr(i) for i in range(65,91)]+[chr(j) for j in range(97,122)] print(\'\'.join(random.sample(l,4)))
三、os模块
os模块常用方法
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (\'.\')
os.pardir 获取当前目录的父目录字符串名:(\'..\')
os.makedirs(\'dirname1/dirname2\') 可生成多层递归目录
os.removedirs(\'dirname1\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname
os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(\'path/filename\') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\'
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command) 运行shell命令,获取执行结果
os.environ 获取系统环境变量
os.path
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
注意:os.stat(\'path\\filename\') 获取文件\\目录信息的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,<br>在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
四、sys模块
sys模块是与python解释器交互的一个接口
# sys模块
import sys
print(sys.argv) #实现从程序外部向程序传递参数。(在命令行里面输打开路径执行)
name=sys.argv[1] #命令行参数List,第一个元素是程序的本身路径
password = sys.argv[2]
if name==\'egon\' and password == \'123\':
print(\'继续执行程序\')
else:
exit()
sys.exit()#退出程序,正常退出时exit(0)
print(sys.version)#获取python解释的版本信息
print(sys.maxsize)#最大能表示的数,与系统多少位有关
print(sys.path)#返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.platform)#返回操作系统平台名称
五、序列化模块
1.什么是序列化-------将原本的字典,列表等内容转换成一个字符串的过程就叫做序列化
2.序列化的目的
1.以某种存储形式使自定义对象持久化
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
json
Json模块提供了四个功能:dumps、loads、dump、load
# dumps和loads
import json
dic={\'k1\':\'v1\',\'k2\':\'v2\',\'k3\':\'v3\'}
print(type(dic))
str_dic = json.dumps(dic) #将字典转换成字符串,转换后的字典中的元素是由双引号表示的
print(str_dic,type(str_dic))#{"k1": "v1", "k2": "v2", "k3": "v3"} <class \'str\'>
dic2 = json.loads(str_dic)#将一个字符串转换成字典类型
print(dic2,type(dic2))#{\'k1\': \'v1\', \'k2\': \'v2\', \'k3\': \'v3\'} <class \'dict\'>
list_dic = [1,[\'a\',\'b\',\'c\'],3,{\'k1\':\'v1\',\'k2\':\'v2\'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class \'str\'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class \'list\'> [1, [\'a\', \'b\', \'c\'], 3, {\'k1\': \'v1\', \'k2\': \'v2\'}]
# dump和load
import json
f=open(\'json_file\',\'w\')
dic = {\'k1\':\'v1\',\'k2\':\'v2\',\'k3\':\'v3\'}
json.dump(dic,f)# #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open(\'json_file\')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
pickle
json 和 pickle 模块
json:用于字符串和python数据类型之间进行转换
pickle:用于python特有的类型和python的数据类型进行转换
# pickle的dumps,sump和loads,load方法
# --------------------------
import pickle
# dic= {\'k1\':\'v1\',\'k2\':\'v2\',\'k3\':\'v3\'}
# str_dic=pickle.dumps(dic)
# print(str_dic) #打印的是bytes类型的二进制内容
#
# dic2 = pickle.loads(str_dic)
# print(dic2) #有吧字典给转换回来了
import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open(\'pickle_file\',\'wb\')
pickle.dump(struct_time,f)
f.close()
f = open(\'pickle_file\',\'rb\')
struct_time2 = pickle.load(f)
print(struct_time.tm_year)
shelve
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
# shelve模块
import shelve
f = shelve.open(\'shelve_file\')
f[\'key\'] = {\'int\':10, \'float\':9.5, \'string\':\'Sample data\'} #直接对文件句柄操作,就可以存入数据
f.close()
import shelve
f1 = shelve.open(\'shelve_file\')
existing = f1[\'key\'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing)
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
mport shelve f = shelve.open(\'shelve_file\', flag=\'r\') existing = f[\'key\'] f.close() print(existing)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
# 设置writeback import shelve f1 = shelve.open(\'shelve_file\') print(f1[\'key\']) f1[\'key\'][\'new_value\'] = \'this was not here before\' f1.close() f2 = shelve.open(\'shelve_file\', writeback=True) print(f2[\'key\']) f2[\'key\'][\'new_value\'] = \'this was not here before\' f2.close()
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
以上是关于python全栈开发第十篇Python常用模块二(时间randomossys和序列化)的主要内容,如果未能解决你的问题,请参考以下文章