THMBurp Suite:Other Modules(Burp Suite-其他模块)-学习
Posted Hekeatsl Blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了THMBurp Suite:Other Modules(Burp Suite-其他模块)-学习相关的知识,希望对你有一定的参考价值。
本文相关的TryHackMe实验房间链接:https://tryhackme.com/room/burpsuiteom
本文相关内容:了解 Burp Suite 中一些可能鲜为人知的模块。

介绍
除了著名的Repeater模块和Intruder模块之外,Burp Suite 还内置了几个可能不太常用的功能模块。
具体而言,本文将介绍Burp Suite中的解码器工具(Decoder)、对比器工具(Compared)和定序器工具(Sequencer),这些工具使我们能够:对文本内容进行编码和解码、比较不同的文本集、分析所捕获的令牌(tokens)样本的随机性;直接在Burp Suite中执行这些相对简单的任务可以节省大量时间,因此学习使用以上三个功能模块是非常值得的。
事不宜迟,让我们开始研究Decoder(解码器)功能模块。
Decoder(解码器)-界面概览
Burp Suite的Decoder模块允许我们处理数据。顾名思义,我们可以使用Decoder解码我们所捕获的信息,同时我们也可以编码我们自己的数据,并可将编码后的数据发送给目标;Decoder还允许我们创建数据的哈希和,而且能够提供Smart Decode(智能解码)功能,Smart Decode会尝试递归解码所提供的数据,直到数据恢复为明文为止(这类似于Cyberchef的"Magic"功能)。
让我们从Burp Suite的顶部菜单中选择Decoder选项卡,查看可用的选项:

Decoder选项卡界面为我们提供了以下几个选项:
- 左边的方框是我们粘贴/输入要编码或者解码的文本的地方,我们可以在其他模块中单击右键并选择"Send to Decoder"——从Burp框架的其他部分发送数据到此处。
- 在右侧列表顶部,我们可以选择将输入内容作为文本处理,或者选择将输入内容作为十六进制字节值处理。
- 在右侧列表的中间部分,我们有一个下拉菜单可对输入内容进行编码、解码或Hash计算。
- 最后,在右侧列表的底部,我们可以看到有一个"Smart Decode-智能解码"功能,使用该功能将会自动解码输入内容。

当我们在上图的输入字段中添加数据并执行格式转换时,上图所示的界面将复制自身并会在新生成的输入框中包含格式转换后的输出内容,然后我们可以继续选择使用相同的选项对数据执行进一步的格式转换操作:

Decoder(解码器)-编码/解码
编码和解码选项
仔细查看手动编码和解码的选项,我们可以发现,无论我们选择编码还是解码菜单,以下选项都是一样的:
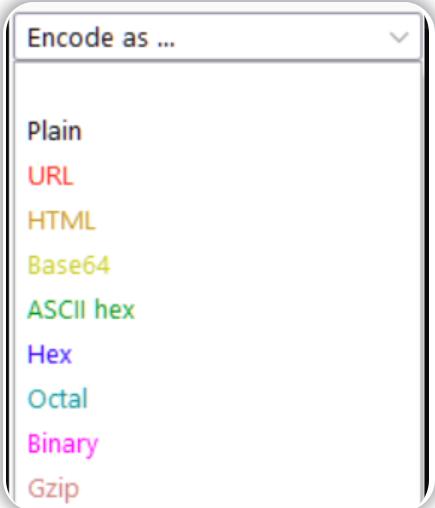
-
Plain:明文格式是我们在执行任何数据转换之前所拥有的格式。
-
URL:URL编码格式用于保证数据在web请求的URL中安全传输,它会将输入数据的ASCII字符代码以十六进制格式表示,然后在前面加上一个百分比符号(
%),URL编码对于测试任何类型的web应用程序都是非常有用的编码方法。
例如,我们可以对正斜杠字符(/)进行URL编码,正斜杠的ASCII字符代码是47,以十六进制表示是2F,所以正斜杠字符的URL编码为%2F;我们可以用解码器确认这一点,在输入框中输入正斜杠字符,然后选择Encode as -> URL即可。
-
HTML:如果要将输入文本编码为HTML实体,则需要将输入文本中的特殊字符替换——开头为
&符号,然后是一个十六进制数或者是对被转义字符的引用,最后以一个分号(;)结尾;例如,双引号的HTML编码是""",当该HTML编码变体被插入到web页面中时,它将会被双引号(")符号取代;HTML编码方法允许HTML语言中的特殊字符在HTML页面中安全地呈现,这种编码方法在一定程度上可用于防止XSS(跨站点脚本)等攻击。
在Decoder中使用HTML选项时,我们可以将任何字符编码为其HTML转义格式或者对捕获到的HTML实体进行解码;例如,如果要将一个HTML实体解码为双引号,我们可以先输入双引号的HTML编码变体,然后选择decode as -> HTML。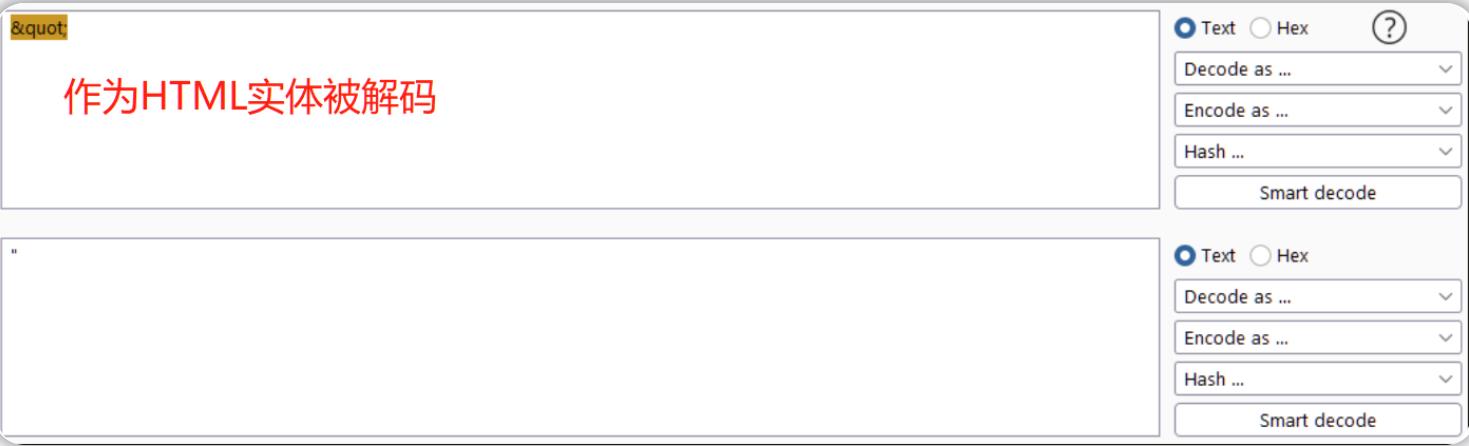
-
Base64:另一种被广泛使用的编码方法是base64,它可以对任何ASCII兼容格式的数据进行编码;bsae64编码的设计目的是先获取二进制数据(例如图像、媒体、程序),然后将其编码为适合在几乎任何介质中进行传输的格式。如果你对base64编码背后的过程感兴趣,你可以参考相关博客文章进行了解。
-
ASCII Hex:此选项可将数据在ASCII表示和十六进制表示之间进行转换,例如,"
ASCII"一词可以被转换成十六进制数"4153434949";在转换过程中,原始数据中的每个字母都会被单独提取,并将从ASCII表示转换为十六进制表示,比如,"ASCII"一词中的字母"A"在ASCII 表中对应的十六进制表示是41,类似地,字母"S"对应的十六进制为53,依此类推就能得到十六进制数"4153434949"。 -
Hex、Octal和Binary:这些编码选项都只适用于内容为数字的输入,使用这些选项之后,输入内容将在十进制、十六进制、八进制(以8为基数)和二进制之间转换。
-
Gzip:Gzip选项提供了一种压缩数据的方法,它被广泛用于在将文件和页面发送到浏览器之前压缩文件和页面的大小;发送更小的页面意味着更快的加载时间,这对于希望提高SEO得分并避免惹恼客户的开发人员来说是非常可取的。Decoder允许我们手动编码和解码gzip数据,这些数据可能很难处理,因为gzip数据通常不是有效的ASCII/Unicode格式。

我们可以连续使用以上任何选项,例如,我们可以输入一个短语("Burp Suite Decoder"),先将其转换为ASCII Hex格式,然后再转换为Octal(八进制)格式:
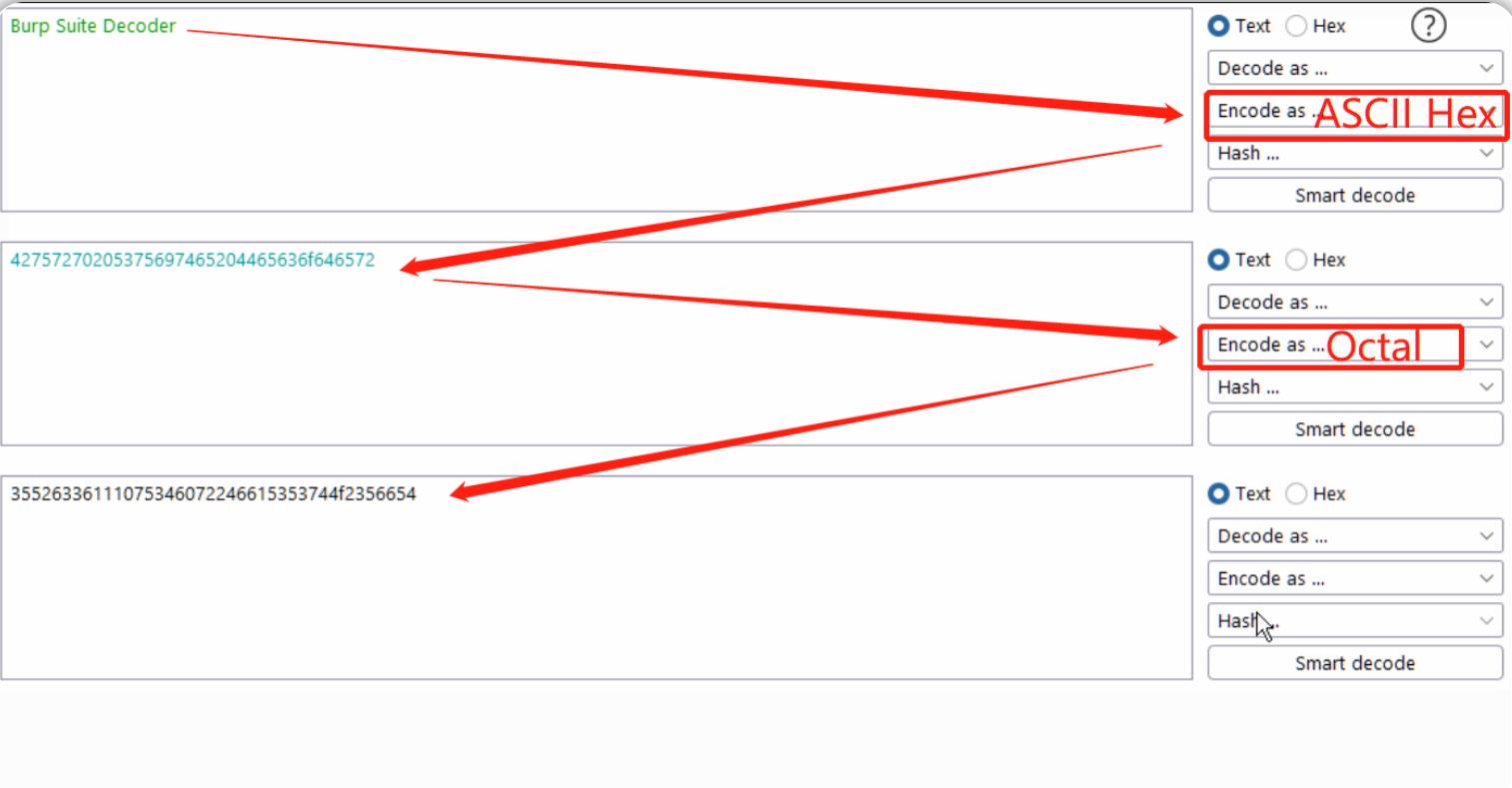
通过组合使用编码选项(或者解码选项),能够让我们对正在编码或解码的数据实现更丰富的格式转换处理。
我们可以从以上内容以及示例中注意到:每个编码/解码选项都是以不同色彩区分的,通过比对数据的显示颜色,我们就可以快速地查看某个数据应用了什么格式的转换选项。
Hex Format(十六进制格式)
以ASCII格式(文本格式)输入数据很方便,但有时我们也需要逐字节编辑输入内容,为此,我们可以通过在解码选项上方选择"Hex"来使用"Hex视图":

如上图所示,这个设置允许我们以十六进制字节格式查看和编辑文本——如果我们处理二进制文件或其他非ASCII数据,这是一个非常有用的技巧。
Smart Decode(智能解码)
最后,让我们来看看"Smart Decode-智能解码"选项,Decoder(解码器)的这个特性会试图自动解码已经编码过的文本。
例子:如果我们选择智能解码选项,Burp Suite会被自动识别为HTML编码并将自动解码。

Burp Suite中的"Smart Decode-智能解码"功能还远远不够完美,但是此功能对于快速解码未知数据块可能非常有用。
答题
关于知识学习,最好的内化方法就是付诸实践,接下来我们将使用Burp Suite中的Decoder功能模块来回答以下问题。
使用Burp Suite的Decoder模块,以Base64格式编码短语:Let\'s Start Simple。

使用URL选项解码此数据:%4e%65%78%74%3a%20%44%65%63%6f%64%69%6e%67。

使用智能解码选项对此数据进行处理:%34%37。

先对Encoding Challenge进行base64编码,得到编码结果之后将其以"ASCII Hex"编码选项转换格式,然后再继续以"Octal"编码选项转换格式,最后将得到一个八进制值。


Decoder(解码器)-哈希计算
除了编码/解码功能外,Decoder还为我们提供了为输入的数据生成哈希和的选项。
理论
哈希计算是一个单向过程,它主要用于将数据转换为一个独特的数字签名,一个算法要成为哈希算法,那么它通过计算所产生的输出结果必须是不可逆转的。
在实际运用中,一个好的哈希算法能够确保每个输入的数据都会对应一个完全唯一的哈希值。例如,使用MD5算法为文本"MD5sum"生成一个哈希和,会返回一个结果"4ae1a02de5bd02a5515f583f4fca5e8c";而使用相同的算法处理文本"MD5SUM",则将生成一个完全不同的哈希值"13b436b09172400c9eb2f69fbd20adad"。
哈希计算经常被用于验证文件和文档的完整性,因为即使对文件进行非常小的更改 也会导致最后得到的Hash(哈希)值发生显著变化。
注意:MD5算法的安全性并不高,它在现代应用程序中可能不会被使用。
哈希计算也可用于安全地存储密码值,由于哈希计算过程是单向的,这意味着通过计算得到的哈希值是不可逆转的,因此,即使发生数据库泄露事件,哈希密码值也将会是(相对)安全的。
当用户创建密码时,应用程序可以选择对原始密码值进行哈希计算,然后以hash值的形式将密码存储在数据库中;然后,当用户尝试登录时,应用程序将对用户所提交的密码进行哈希计算,并会把得到的计算结果与存储在数据库中的哈希值进行比对,如果哈希值匹配,则用户输入的密码会被认为是正确的。
当一个应用程序选择使用哈希算法时,相关的数据库就不必存储原始(明文)密码,只需要存储密码所对应的哈希值即可。
Decoder中的Hash选项
Decoder(解码器)允许我们直接在Burp Suite内生成数据的哈希和,这与我们在前文中提到的编码/解码选项的工作方式大致相同。具体而言,我们可以在解码器界面中点击"Hash"下拉菜单,然后从列表中选择一个算法来对数据进行哈希计算:
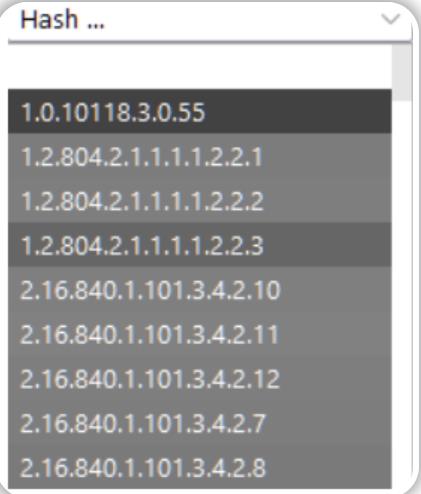
注意:这是一个比编码/解码选项长得多的列表——我们可以向下滚动列表以查看可用的哈希算法。
使用前文示例,我们先在解码器的输入框中输入"MD5sum",然后点击"Hash"下拉菜单并向下滚动算法列表,找到"MD5"算法选项并点击应用,这会自动将我们带入"Hex视图"(其中包含了我们的哈希计算结果):

如上图所示,以上哈希计算的输出并不会返回一个纯ASCII/Unicode文本,因此,我们通常可以将哈希算法的输出结果转换为十六进制字符串,这将是我们能够经常看到的"哈希值"格式。我们可以通过对"哈希和"应用"ASCII Hex"编码选项来完成这项工作,从而得到一个整洁的十六进制字符串。

答题
使用Burp Suite的Decoder模块。
使用SHA-256算法计算Let\'s get Hashing!的哈希值,然后使用ASCII Hex编码选项——将得到的hash值转换为十六进制字符串:

使用MD4算法计算Insecure Algorithms的哈希值,然后使用base64编码选项——将得到的hash值转换为base64格式:

下载由本文相关的TryHackMe实验房间所提供的任务文件,对文件中的四个密钥进行hash计算,找到hash值为3166226048d6ad776370dc105d40d9f8的密钥(此处使用的hash算法为MD5算法):
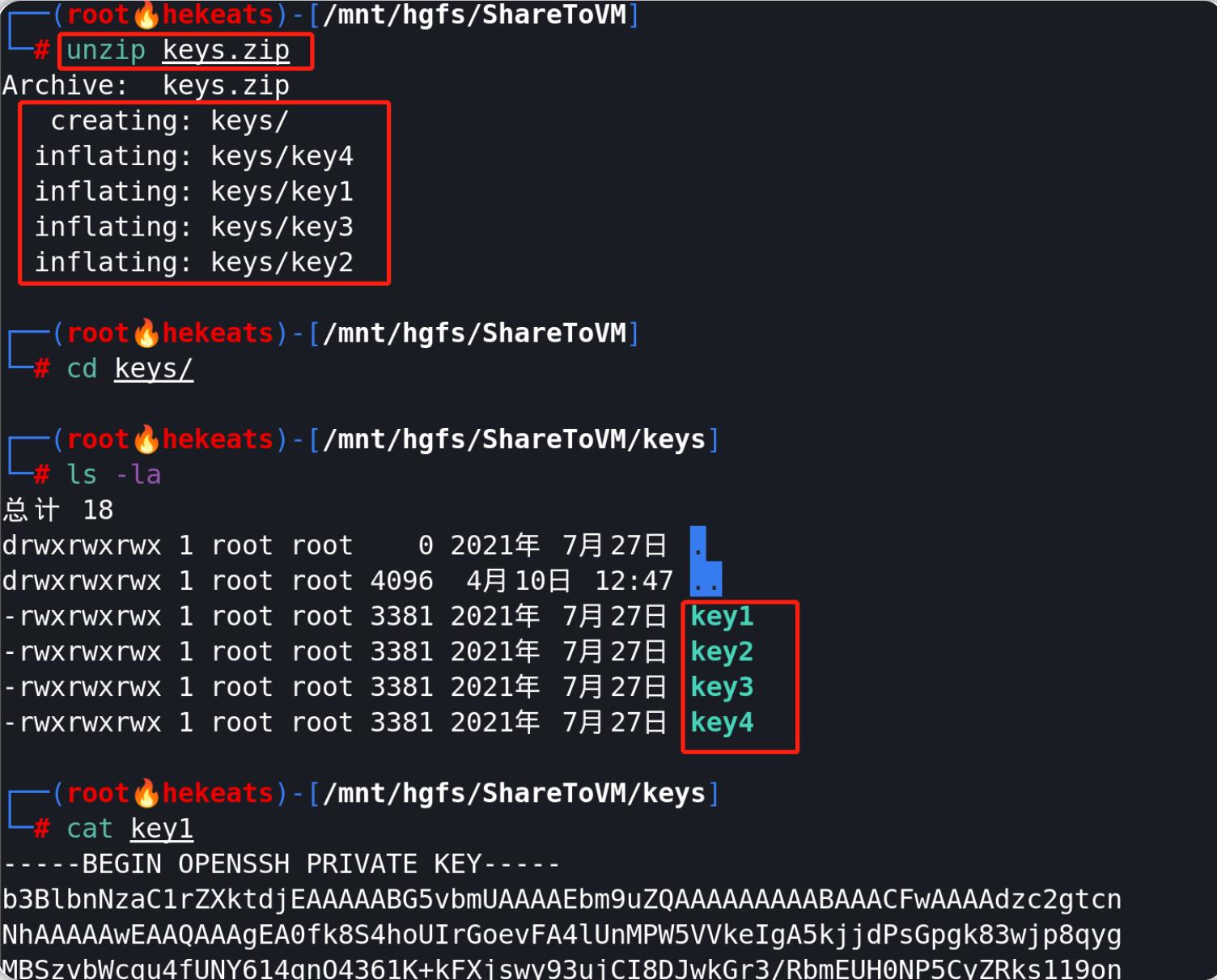
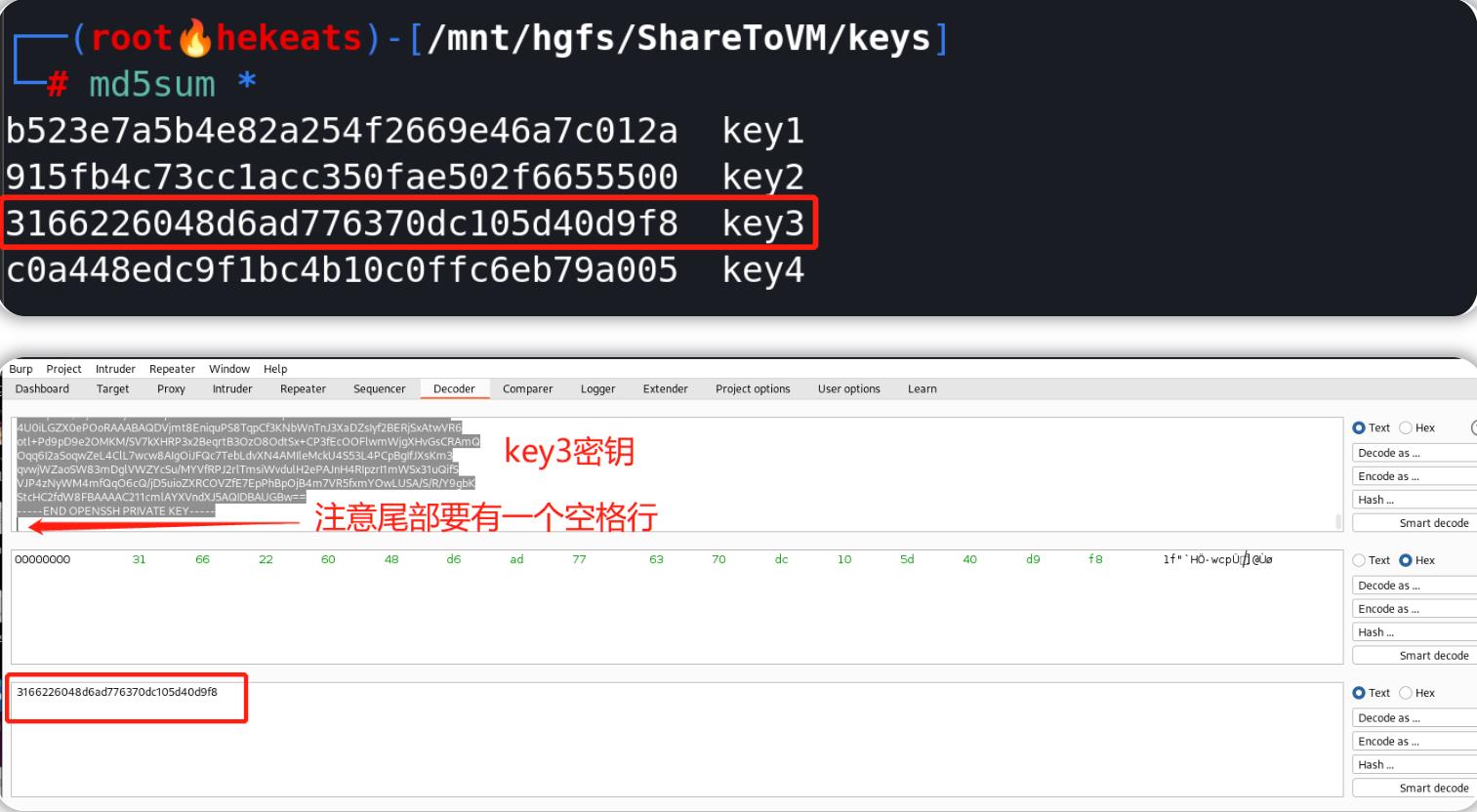

Comparer(对比器)-界面概览
顾名思义,Comparer允许我们通过ASCII字符或字节对比两段数据。
让我们先来看看Comparer的界面:
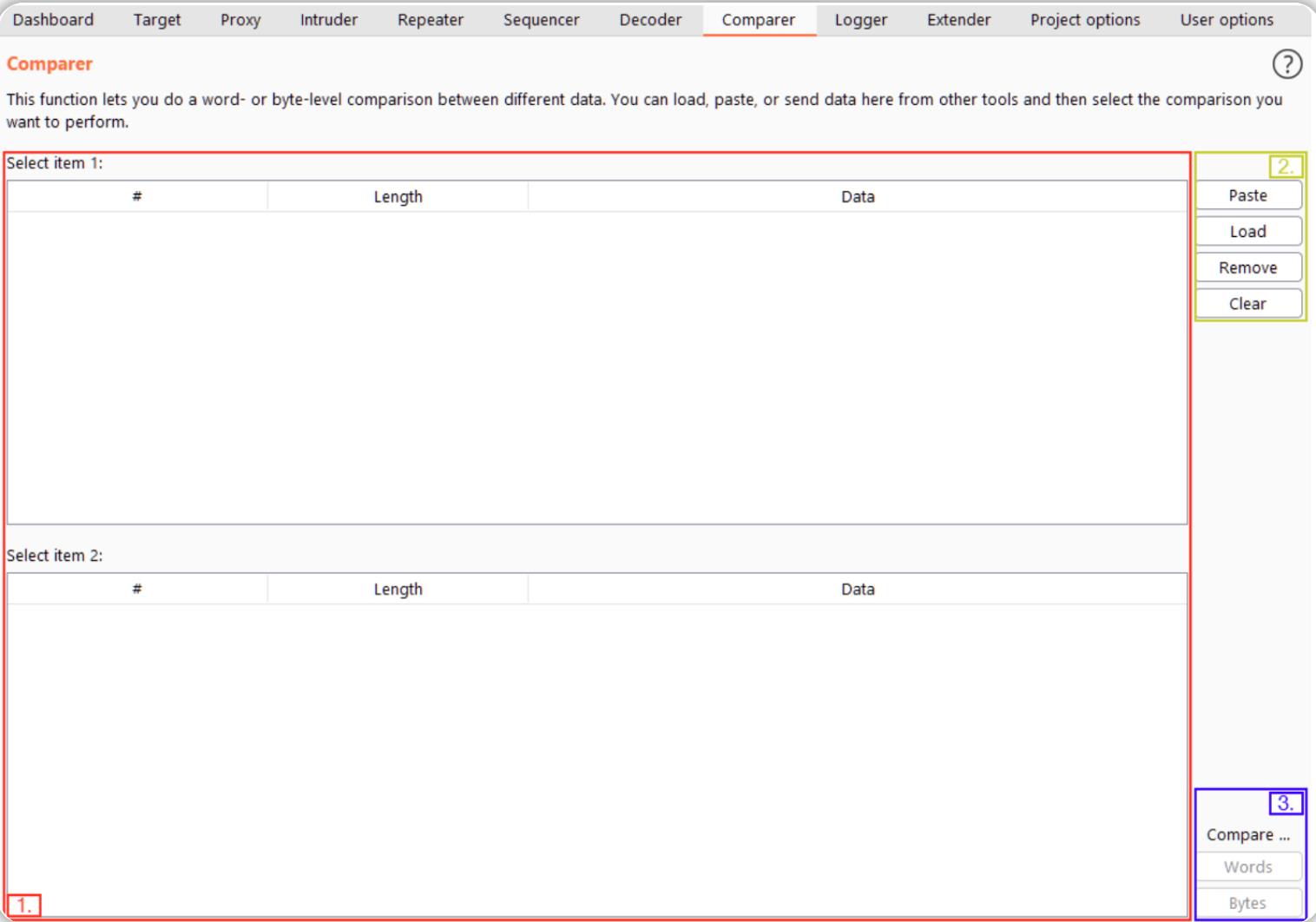
如上图所示,Comparer界面可以分为三个主要部分:
- 在界面左侧,会显示正在对比的项目,当我们将数据加载到Comparer中时,数据将显示在上下表中,然后我们就可以选择两个数据集进行对比。
- 在界面的右上角,我们可以选择从剪贴板中粘贴数据(Paste)、从文件中加载数据(Load)、删除当前行(Remove)、以及清除所有数据集(Clear)。
- 最后,在界面右下角,我们可以选择通过字符或字节来对比已经加载的数据集,每当我们准备对比所选择的数据时,就可以单击这两个按钮中的一个。
与大多数Burp Suite模块一样,我们也可以通过右键单击并选择“发送到Comparer”将数据从其他模块加载到对比器中。
当我们加载好数据并使用Comparer进行比较时,我们会得到一个弹出窗口,该窗口会显示数据对比的结果:

同样,上图这个窗口也有三个不同的部分:
-
正在对比的数据占据了上图窗口的大部分,我们可以选择以文本或十六进制格式查看这些数据。该窗口中的初始数据格式由我们在前一个窗口中选择按字符还是按字节对比来决定,但是我们也可以在当前窗口使用按钮来覆盖格式。
-
用于数据集对比的Key位于窗口左下角,此处显示了在两个数据集之间用哪些颜色来表示存在修改、删除和添加的数据。
-
在窗口的右下角是"Sync views-同步视图"复选框,选中该复选框时,意味着两组对比数据将同步格式——即,如果你将其中一组数据更改为十六进制视图,另一组数据也将发生对应的变化来形成格式同步。
Comparer(对比器)-示例
我们现在知道Comparer是做什么的了,但是它有什么用呢?
在许多情况下,Comparer能够快速比较两个(可能非常大的)数据块。
例如,在使用Burp攻击器执行登录暴力破解攻击或者凭据填充攻击时,你可能希望对比两个长度不同的响应以查看差异,而这些差异能够表明是否登录成功。
操作
启动目标机器,使用浏览器导航至: http://10.10.197.32/support/login
在浏览器中尝试使用无效的用户名和密码登录——并在Burp 代理中捕获这个请求。


使用Ctrl + R将请求发送到Repeater,或者通过右键单击 Proxy 中的请求并选择“发送到 Repeater”。

在Repeater中点击"Sent"发送请求,然后右键单击得到的响应消息并选择“发送到Comparer”。
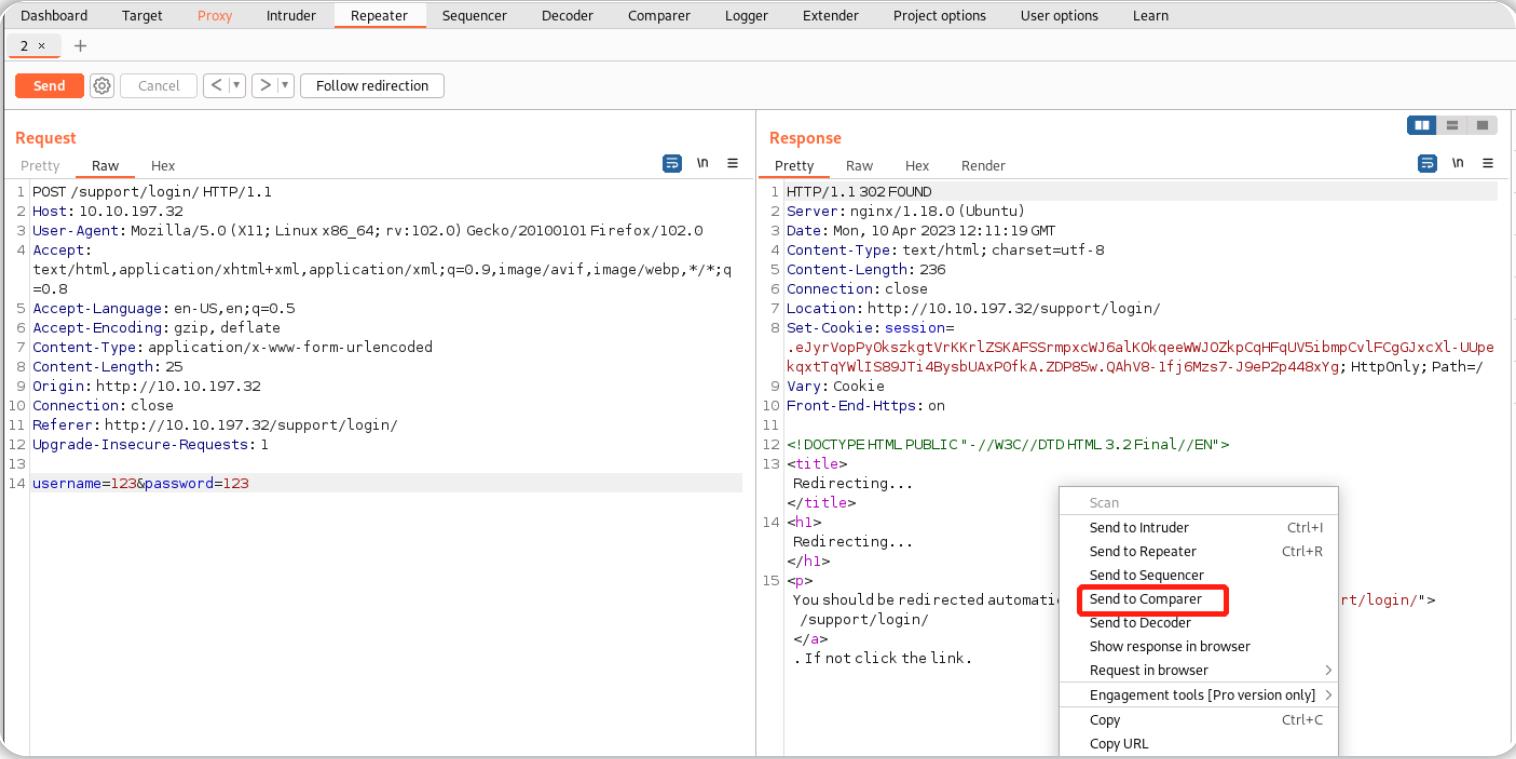

在Repeater选项卡中,将登录凭据更改为:
- 用户名:
support_admin - 密码:
w58ySK4W

再次通过Repeater发送请求,然后将得到的新响应消息转发给Comparer,最后进行数据对比(按字符对比两个响应消息,查看数据集之间的区别)。



Sequencer(定序器)-界面概览
Sequencer能够对token(令牌)进行熵分析,Sequencer是很少在CTFs和其他实验室环境中使用的Burp工具之一,但却是现实世界中web应用渗透测试的重要组成部分。
简而言之,Sequencer允许我们测量“令牌”的熵(即随机性程度)——“令牌”是用于识别某些东西的字符串,理论上应该以加密安全的方式生成;例如,我们可能希望分析会话cookie的随机性或者保护表单提交的跨站请求伪造(CSRF)令牌的随机性。如果事实证明这些令牌不是安全生成的,那么我们可以(理论上)预测之后生成的令牌的值,想象一下,如果这个令牌是用于密码重置的,这意味着什么……
让我们先查看Sequencer的界面:

我们可以使用Sequencer来执行令牌分析,主要有以下两种方法:
- Live capture(实时捕获):实时捕获是分析令牌的两种方法中更常见的一种——这也是Sequencer的默认子选项卡。实时捕获允许我们将一个特殊的请求(这个请求可以创建令牌)传递给Sequencer以供我们分析。例如,我们可能希望将一个传递到登录端点的POST请求转发到Sequencer,因为我们知道服务器将通过一个cookie来响应这个POST请求。传入请求到Sequencer后,我们可以告诉Sequencer开始实时捕获:这将自动发出数千次相同的请求,从而存储大量生成的令牌样本以供分析。一旦我们积累了足够的令牌样本,我们就可以停止Sequencer的捕获操作,并开始分析我们所捕获的令牌。
- Manual load(手动加载): 手动加载允许我们将预先生成的令牌样本列表直接加载到Sequencer中进行分析,使用Manual Load意味着我们不需要向目标发出数千个请求(这既吵闹又耗费资源),但这意味着我们必须需要获得大量预先生成的令牌列表。
在本文中,我们将专注于使用Live capture(实时捕获)来分析令牌。
Sequencer(定序器)-实时捕获
最好的学习方法就是实践,让我们通过对admin登录表单中使用的反暴力令牌执行熵分析(随机性程度分析)来学习如何使用Sequencer实时捕获。
我们使用Burp代理捕获一个针对 http://10.10.197.32/admin/login/ 的请求,然后右键单击请求并选择“发送到Sequencer”:

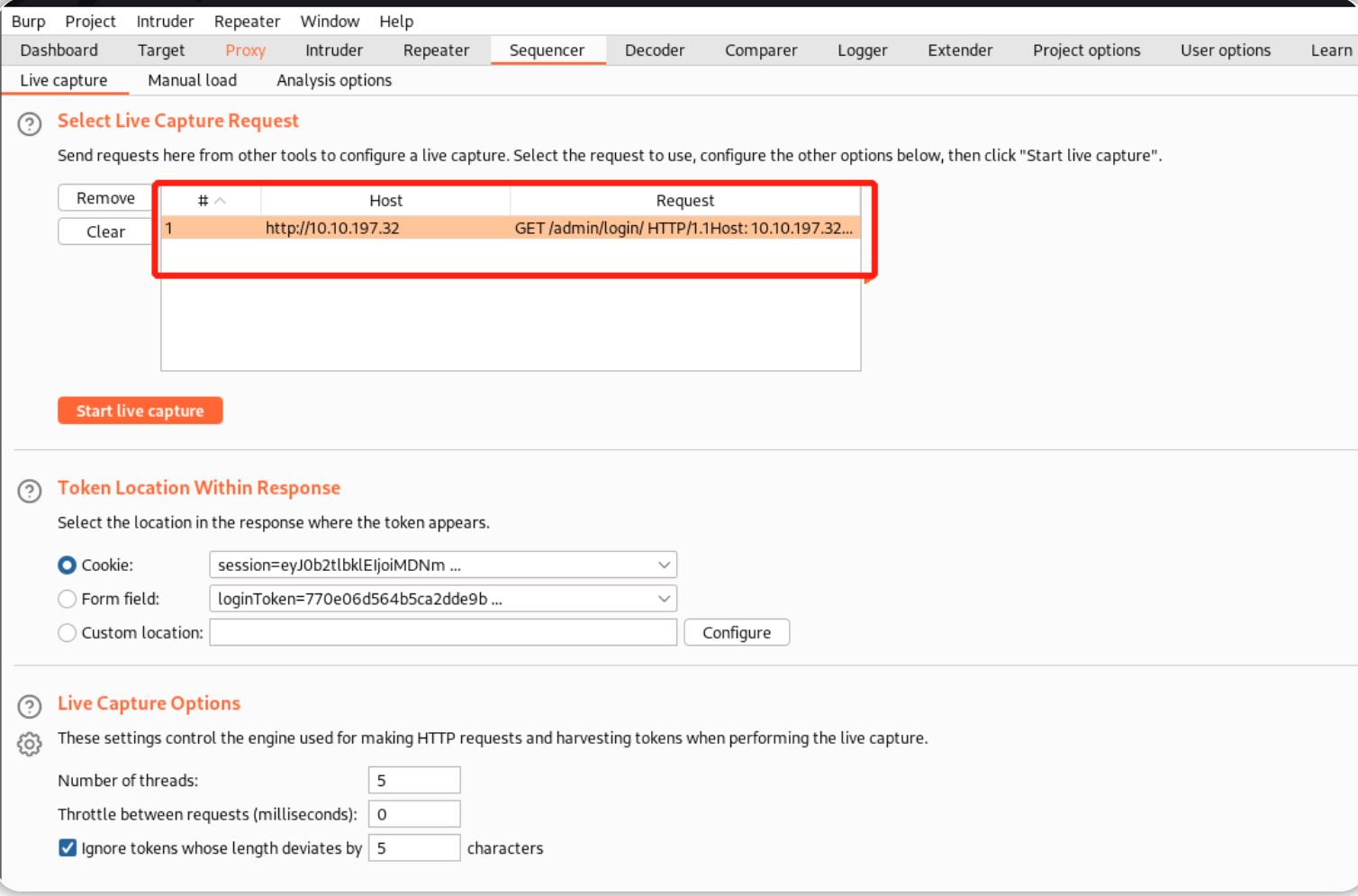
注意,在“Token Location Within Response”部分,我们可以选择Cookie、Form field(表单字段)和Custom location(自定义位置);在这个例子中,我们需要测试loginToken,所以选择“Form field”:
在本例情况下,我们可以安全地将所有其他选项设置为默认值,所以让我们直接单击“Start live capture”按钮即可:

现在会弹出一个新窗口,告诉我们正在执行实时捕获,并显示到目前为止我们已经捕获了多少令牌;我们需要保持等待,直到我们捕获到了合理数量的令牌(大约10,000个就可以了),一般而言,我们的令牌样本越多,我们的熵分析(随机性程度分析)就越准确。
一旦我们捕获到了大约10,000个令牌,就可以点击“Pause-暂停”,然后选择“Analyze now-立即分析”按钮进行令牌分析:

注意:我们也可以选择“Stop-停止”捕获,但是,最好的选择还是使用“Pause-暂停”按钮,这样即使Sequencer报告"没有足够的样本来准确计算令牌的熵",我们也可以立即恢复捕获状态。
如果我们想要接收令牌分析的定期结果更新,我们还可以选中“Auto analyze”复选框,这样做会告诉Burp每2000个请求左右就执行一次熵分析,然后Burp将频繁更新令牌的分析结果,随着更多的样本加载到Sequencer中,我们得到的令牌分析结果会越来越准确。
值得注意的是,我们还可以选择复制或保存捕获到的令牌,以供以后进一步分析。
在点击“Analyze now-立即分析”按钮后,Burp将开始分析令牌样本的熵并生成一个报告,我们将在下一个小节中仔细研究这个问题。
Sequencer(定序器)-分析
承接上一小节的操作,现在我们有了一个关于"令牌-token"熵分析(随机性程度分析)的报告。
Burp会对捕获的令牌样本执行数十个测试,但是我们在此不考虑这些测试背后的过程,相反,我们将主要关注最终生成的报告摘要。
Sequencer所生成的"令牌-token"熵分析报告分为四个主要部分——第一部分是对分析结果的总结:
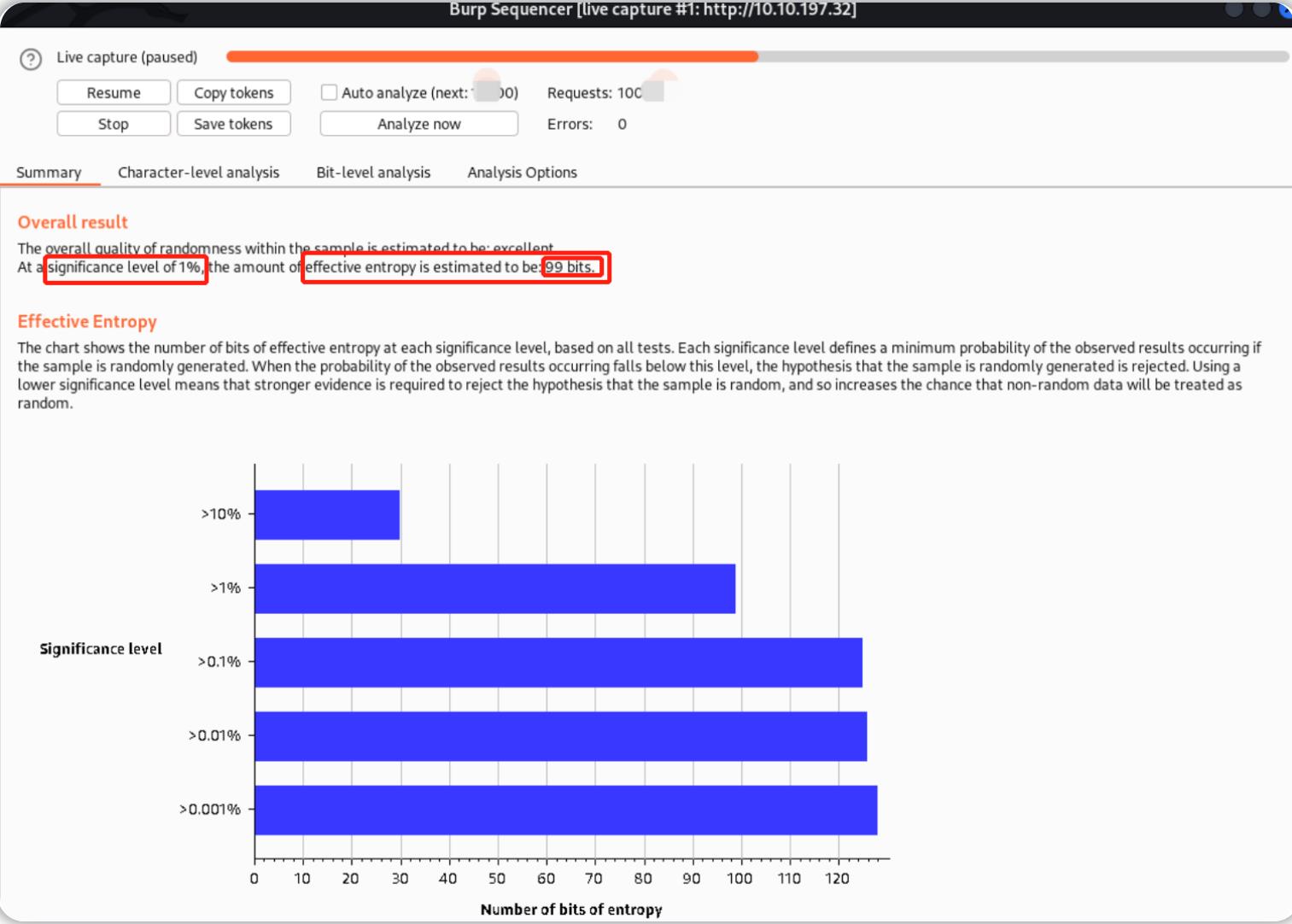
上图中的摘要会给我们一个整体的分析结果,包括:有效的熵(entropy),结果的可靠性分析,对采集样本的总结。
总的来说,上述这些分析摘要通常足以确定令牌是否是安全生成的,然而,在某些情况下,我们也可能需要直接查看测试结果——这可以在“字符级分析”和“位级分析”选项卡中完成(本文对此不做赘述)。
由上图的摘要结果可知:显著性水平为1%(估计有 1% 的错误几率),同时Burp还计算出令牌的有效熵应该在99位左右,对于一个安全令牌来说,这可能是一个很好的熵水平,但是我们不能保证这个计算结果是完全准确的。
如何解决纱线构建错误 - 错误:ENOTEMPTY: directory not empty, rmdir '/frontend/out/node_modules/cacache/node_modul
【中文标题】如何解决纱线构建错误 - 错误:ENOTEMPTY: directory not empty, rmdir \'/frontend/out/node_modules/cacache/node_modules/.bin\'【英文标题】:How to solve yarn build error - Error: ENOTEMPTY: directory not empty, rmdir '/frontend/out/node_modules/cacache/node_modules/.bin'如何解决纱线构建错误 - 错误:ENOTEMPTY: directory not empty, rmdir '/frontend/out/node_modules/cacache/node_modules/.bin' 【发布时间】:2021-02-14 02:13:34 【问题描述】:我在 Docker Compose 中使用 NextJS、Django、Postgres、Nginx 部署项目,它在本地 (ubunutu 18.04) 中运行良好。但在服务器(ubuntu 20.04)中,它会引发Error: ENOTEMPTY: directory not empty, rmdir '/frontend/out/node_modules/cacache/node_modules/.bin' 错误。如何解决这个问题。
附言我正在使用wait-for.sh作为前端等待api服务准备好(否则我也会得到构建错误),我的本地docker版本是Docker version 19.03.12, build 48a66213fe,我的服务器docker版本是Docker version 19.03.11, build dd360c7可能是错误的原因?
我的前端服务 Dockerfile:
USER root
WORKDIR /frontend
COPY . /frontend
# Add wait-for-it
COPY wait-for.sh wait-for.sh
RUN chmod +x wait-for.sh
RUN yarn
我的 docker-compose.yml:
services:
db:
image: postgres:12.0-alpine
volumes:
- postgres_data:/var/lib/postgresql/data/
environment:
- POSTGRES_USER=purple_postgres_user
- POSTGRES_PASSWORD=purple_p@ssW0rd
- POSTGRES_DB=purple_db
web:
build: .
command: python manage.py runserver 0.0.0.0:8000
# command: ./manage.py purple.wsgi:application --bind 0.0.0.0:8000
volumes:
- ./backend/:/home/purple_user/purple/
- static_volume:/home/purple_user/purple/static/
- media_volume:/home/purple_user/purple/media/
expose:
- 8000
ports:
- 8000:8000
env_file:
- ./.env.dev
depends_on:
- db
nginx:
build: ./nginx
ports:
- 80:80
volumes:
- static_volume:/var/www/staticfiles/
- media_volume:/var/www/mediafiles/
- build_folder:/var/www/frontend/
depends_on:
- web
frontend:
container_name: frontend
build:
context: ./frontend
volumes:
- build_folder:/frontend/out
depends_on:
- web
command: ./wait-for.sh web:8000 -- yarn build
volumes:
postgres_data:
static_volume:
media_volume:
build_folder:```
【问题讨论】:
是什么产生了错误(Dockerfile 中的RUN yarn)?您是否有一个 .dockerignore 文件导致该文件夹从图像中排除?该图像应该运行的CMD 是什么?
就我而言,这是因为我在尝试删除的目录中打开了一个资源管理器窗口
是否安装了实时服务器扩展?
@DavidMaze 在最后一步中引发的错误,在 docker-compose 文件中指定,前端服务命令规范。图像 CMD 在 docker-compose 文件中指定,该文件为 ./wait-for.sh web:8000 -- yarn build。 wait-for.sh 是我用于服务等待另一个服务的脚本。之后yarn build 命令被执行,这就是引发错误的地方。
@Ashok 不,没有任何窗口打开,实时服务器扩展也不是这样。因为我在服务器中运行docker-compose up 命令。错误是在服务器中引发的,而不是在本地引发的。
【参考方案1】:
对我来说,解决方案是删除名为build_folder 的前端服务卷。要获得构建文件夹的正确名称,您可以运行 docker volume ls - 对我来说是 Purple_build_folder - 并通过运行 docker volume rm [volume name] 命令删除文件夹。
【讨论】:
【参考方案2】:Docker 中的命名卷是持久的。当你的docker-compose.yml 文件有
volumes:
- build_folder:/frontend/out
它会将先前构建的结果存储在build_folder 中,并且下次运行此容器时它们仍然存在。这就是导致您看到的错误消息的原因。
我会避免设置 Compose 服务只是为其他服务构建文件。相反,使用multi-stage build 在图像构建时构建工件。相反,在您的 Nginx 映像 Dockerfile 中,构建前端应用程序:
FROM node:12 AS frontend
WORKDIR /frontend
COPY frontend/package.json frontend/yarn.lock .
RUN yarn install
COPY frontend .
RUN yarn build
FROM nginx
# ... whatever this Dockerfile had before ...
# (except, change `COPY stuff /image/path` to `COPY nginx/stuff /image/path`)
COPY --from=frontend /frontend/out /var/www/frontend
您可以使用与COPY 静态文件--from 您的web 图像类似的技术;要么使用额外的构建阶段,COPY 它们直接来自构建上下文,要么COPY --from 单独构建图像的名称。 (这有点难以编排,因为 Compose 不会对依赖的构建进行排序。)这避免了类似的问题,即 static_volume 的内容在两个图像中隐藏已更改的静态文件。
services:
nginx:
# The build context must be an ancestor of anything that
# it needs to `COPY` in. Since we `COPY` from both the `frontend`
# and `nginx` directories, we need to specify
build: .
ports: ['80:80']
depends_on: [web]
# No `volumes:`; the image is self-contained
# No build-only `frontend` container
【讨论】:
但是,为什么这在我的本地计算机上有效,而不是在服务器上?以上是关于THMBurp Suite:Other Modules(Burp Suite-其他模块)-学习的主要内容,如果未能解决你的问题,请参考以下文章
python [OS modul]了解python3中的modul操作系统以及如何在实际项目中使用它#Intek #Python #os