python爬虫
Posted CCColby
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫相关的知识,希望对你有一定的参考价值。
人生苦短,我用python!
一、关于爬虫
鉴于我的windos环境使用命令行感觉非常不便,也懒得折腾虚拟机,于是我选择了一个折中的办法——Cmder。它的下载地址是:cmder.net
Cmder是一个增强型命令行工具,不仅可以使用windows下的所有命令,更爽的是可以使用linux的命令,shell命令。下载下来后,解压即可使用。稍加设置(具体的设置可以百度),你就会发现它比windos的cmd要好用的多。
爬虫分为通用爬虫和聚焦爬虫,我们所研究的就是聚焦爬虫——抓取网页时筛选,尽量只抓与需求相关的网页信息。而网络爬虫的抓取过程我们可以理解为模拟浏览器操作的过程,这个过程基于Http(超文本传输协议)和Https(安全版的Http)的。当我们向浏览器中输入https://www.baidu.com/时,它就会根据这个地址来获取网页信息。我们所输入的网址就是URL——统一资源定位符,它是用于完整地描述Internet上网页和其它资源的地址的一种标识方式。
二、Python的urllib包
在Python3中,我们可以使用urlib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一些处理URL的模块。我们可以使用help命令查看一下。
import urllib help(urllib)
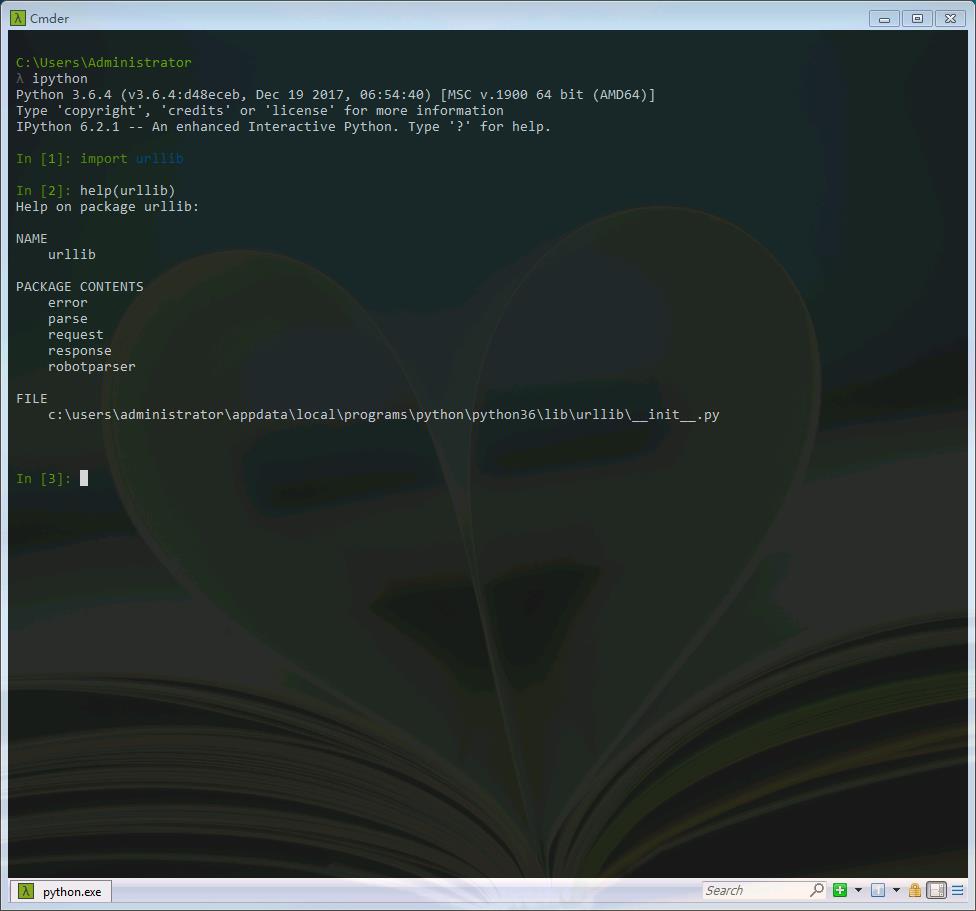
其中:
1.urllib.request模块是用来打开和读取URLs的;
2.urllib.error模块包含一些有urllib.request产生的错误,可以使用try进行捕捉处理(可以学习一下python的异常处理机制);
3.urllib.parse模块包含了一些解析URLs的方法;
4.urllib.robotparser模块用来解析robots.txt(爬虫协议)文本文件,它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法测试爬虫是否可以下载一个页面。
三、下载一个页面
了解了以上这些,我们可以用request来尝试下载一个页面。在ipython中测试一下:
1 from urllib import request 2 3 response=request.urlopen(\'http://www.17jita.com/\') 4 html=response.read() 5 6 print(html)

看起来有些乱码,别着急,我们可以通过简单的decode()命令将网页的信息进行解码,并显示出来.
1 from urllib import request 2 3 response=request.urlopen(\'http://www.17jita.com/\') 4 html=response.read().decode(\'gbk\') 5 6 print(html)
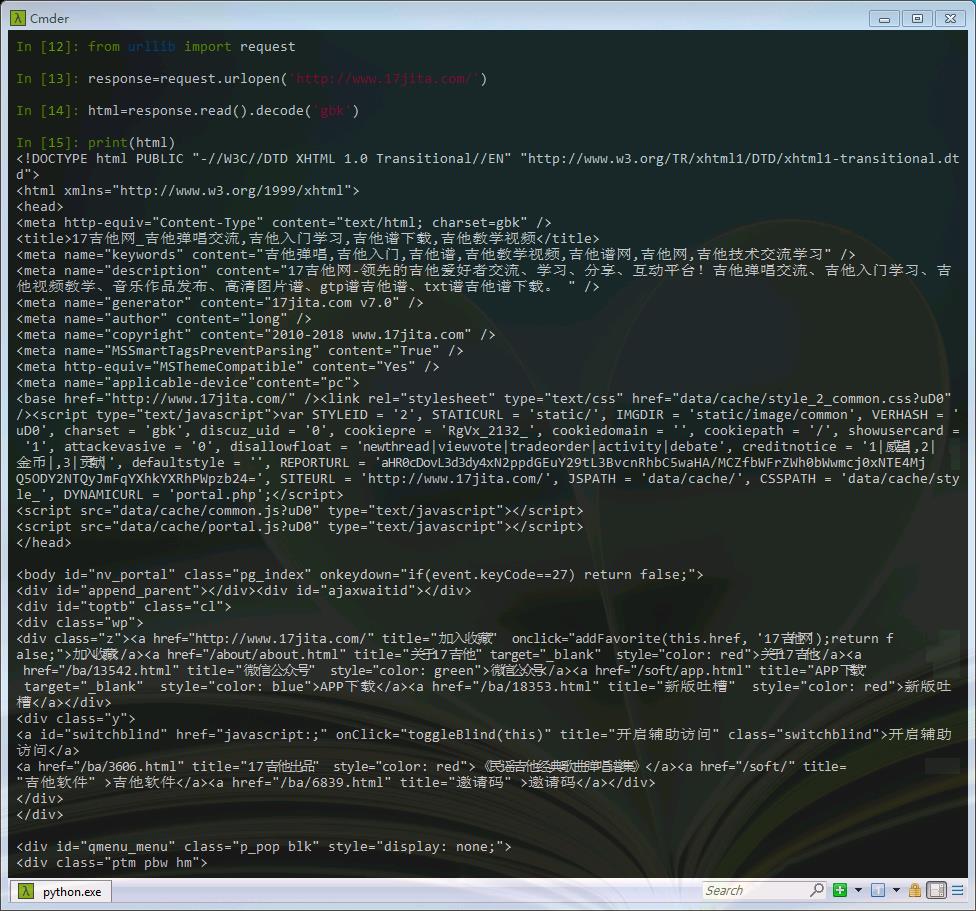
这样我们就可以利用python看到网页的源码了,这与在浏览器右键查看网页源代码所看到的是一致的。
值得注意的是,在使用decode解码时,我们要了解到一些一些常用的编码方式,如:gbk,gb2312,utf-8,Unicode等等。python2的编码就常常为人所诟病,但是在在python3中,这个问题得到了解决。具体资料可以自行百度。
以上是关于python爬虫的主要内容,如果未能解决你的问题,请参考以下文章