我用了100行Python代码,实现了与女神尬聊微信(附代码)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我用了100行Python代码,实现了与女神尬聊微信(附代码)相关的知识,希望对你有一定的参考价值。
参考技术A朋友圈很多人都想学python,有一个很重要的原因是它非常适合入门。对于 人工智能算法 的开发,python有其他编程语言所没有的独特优势, 代码量少 ,开发者只需把精力集中在算法研究上面。
本文介绍一个用python开发的,自动与美女尬聊的小软件。以下都是满满的干货,是我工作之余时写的,经过不断优化,现在分享给大家。那现在就让我们抓紧时间开始吧!
准备:
编程工具IDE:pycharm
python版本: 3.6.0
首先新建一个py文件,命名为:ai_chat.py
PS: 以下五步的代码直接复制到单个py文件里面就可以直接运行。为了让读者方便写代码,我把代码都贴出来了,但是排版存在问题,我又把在pycharm的代码排版给截图出来。
第一步: 引入关键包
简单介绍一下上面几个包的作用: pickle 包 是用来对数据序列化存文件、反序列化读取文件,是人类不可读的,但是计算机去读取时速度超快。(就是用记事本打开是乱码)。 而 json包 是一种文本序列化,是人类可读的,方便你对其进行修改(记事本打开,可以看到里面所有内容,而且都认识。) gensim 包 是自然语言处理的其中一个python包,简单容易使用,是入门NLP算法必用的一个python包。 jieba包 是用来分词,对于算法大咖来说效果一般般,但是它的速度非常快,适合入门使用。
以上这些包,不是关键,学习的时候,可以先跳过。等理解整个程序流程后,可以一个一个包有针对性地去看文档。
第二步:静态配置
这里path指的是对话语料(训练数据)存放的位置,model_path是模型存储的路径。
这里是个人编程的习惯,我习惯把一些配置,例如:文件路径、模型存放路径、模型参数统一放在一个类中。当然,实际项目开发的时候,是用config 文件存放,不会直接写在代码里,这里为了演示方便,就写在一起,也方便运行。
第三步: 编写一个类,实现导数据、模型训练、对话预测一体化
首次运行的时候,会从静态配置中读取训练数据的路径,读取数据,进行训练,并把训练好的模型存储到指定的模型路径。后续运行,是直接导入模型,就不用再次训练了。
对于model类,我们一个一个来介绍。
initialize() 函数和 __init__() 函数 是对象初始化和实例化,其中包括基本参数的赋值、模型的导入、模型的训练、模型的保存、最后返回用户一个对象。
__train_model() 函数,对问题进行分词,使用 gesim 实现词袋模型,统计每个特征的 tf-idf , 建立稀疏矩阵,进而建立索引。
__save_model() 函数 和 __load_model() 函数 是成对出现的,很多项目都会有这两个函数,用于保存模型和导入模型。不同的是,本项目用的是文件存储的方式,实际上线用的是数据库
get_answer() 函数使用训练好的模型,对问题进行分析,最终把预测的回答内容反馈给用户。
第四步:写三个工具类型的函数,作为读写文件。
其中,获取对话材料,可以自主修改对话内容,作为机器的训练的数据。我这里只是给了几个简单的对话语料,实际上线的项目,需要大量的语料来训练,这样对话内容才饱满。
这三个工具函数,相对比较简单一些。其中 get_data() 函数,里面的数据是我自己编的,大家可以根据自己的习惯,添加自己的对话数据,这样最终训练的模型,对话方式会更贴近自己的说话方式。
第五步: 调用模型,进行对话预测
主函数main(), 就是你整个程序运行的起点,它控制着所有步骤。
运行结果:
程序后台运行结果:
如果有疑问想获取源码( 其实代码都在上面 ),可以后台私信我,回复:python智能对话。 我把源码发你。最后,感谢大家的阅读,祝大家工作生活愉快!
我用Python爬取了女神视界,爬虫之路永无止境「内附源码」
我发现抖音上很多小姐姐就拍个跳舞的视频就火了,大家是冲着舞蹈水平去的吗,都是冲着颜值身材去的,能刷到这篇文章的都是lsp了,我就跟大家不一样了,一个个刷太麻烦了,我直接爬下来看个够,先随意展示两个。

采集目标
爬取目标:女神世界

效果展示
工具使用
使用环境:Python3.7 工具:pycharm 第三方库:requests, re, pyquery
爬虫思路:
- 获取的是视频数据 (16进制字节)
- 在这个页面没有视频地址 需要进去详情页 所有需要从 视频播放页开始抓取
使用快捷键 F12 进入开发者控制台:

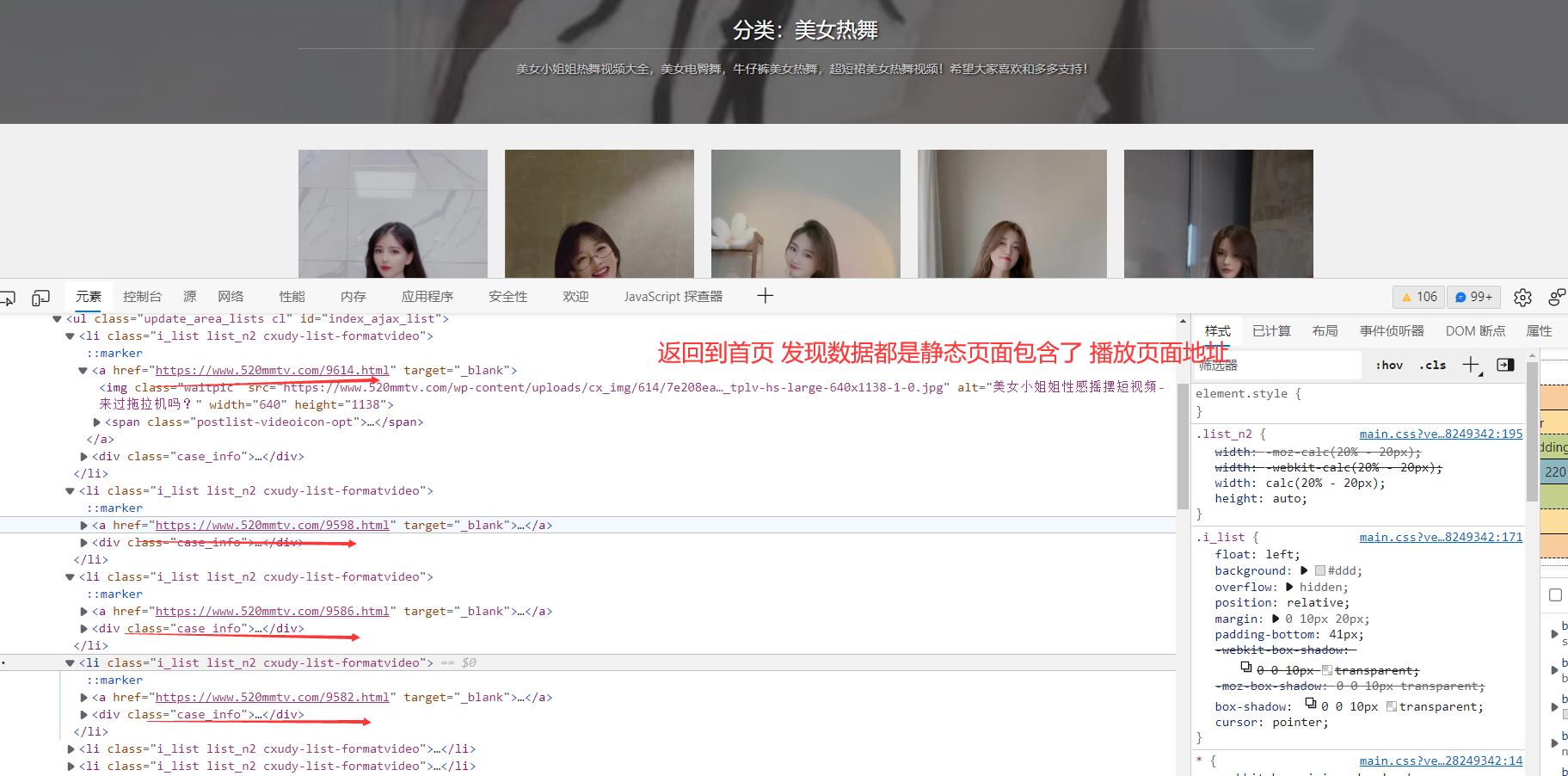
先不急, 找到 视频地址 去搜索他 看看在哪里有包含:


定位他 发现是静态页面返回的数据:

上代码:
def Tools(url):# 封装一个工具函数 用来做请求的
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
response = requests.get(url, headers=headers)
return response
url = 'https://www.520mmtv.com/9614.html'
response = Tools(url).text
video_url = re.findall(r'url: "(.*?)",', response)[0] # 正则表达式提取 视频地址
video_content = Tools(video_url).content
# 视频地址存储 需要在代码同路径 手动创建 短视频文件夹
with open('./短视频/123.mp4', 'ab') as f:
f.write(video_content)
# 下载了一个


def main():
url = 'https://www.520mmtv.com/hd/rewu.html'
response = Tools(url).text
doc = pq(response) # 创建pyquery对象 注意根据css的 class 类选择 和id选择器进行数据提取
i_list = doc('.i_list.list_n2.cxudy-list-formatvideo a').items() # .类选择器 中间有空格的 记得替换成.
meta_title = doc('.meta-title').items() # 标题
for i, t in zip(i_list, meta_title):
href = i.attr('href')
Play(t.text(), href)全部代码:
import requests
import re
from pyquery import PyQuery as pq
def Tools(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
response = requests.get(url, headers=headers)
return response
def Play(title, url):
# url = 'https://www.520mmtv.com/9614.html'
response = Tools(url).text
video_url = re.findall(r'url: "(.*?)",', response)[0]
video_content = Tools(video_url).content
with open('./短视频/{}.mp4'.format(title), 'ab') as f:
f.write(video_content)
print('{}下载完成....'.format(title))
def main():
url = 'https://www.520mmtv.com/hd/rewu.html'
response = Tools(url).text
doc = pq(response) # 创建pyquery对象 注意根据css的 class 类选择 和id选择器进行数据提取
i_list = doc('.meta-title').items() # .类选择器 中间有空格的 记得替换成.
meta_title = doc('.meta-title').items() # 标题
for i, t in zip(i_list, meta_title):
href = i.attr('href')
Play(t.text(), href)
if __name__ == '__main__':
main()下载比较慢网络不好,你网快的话 ,就下载快。
效果:

以上是关于我用了100行Python代码,实现了与女神尬聊微信(附代码)的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点#Python爬虫实战,requests模块,Python实现告诉你女神节送什么礼物