如何安装Spark amp;TensorflowOnSpark
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何安装Spark amp;TensorflowOnSpark相关的知识,希望对你有一定的参考价值。
参考技术A安装scala和Spark
搭建好了上边的来我们进行下一个教程[微笑]
1. 安装scala最好选择一个2.10.X,这样对spark支持比较好,不会出现一些幺蛾子。这有个教程,应该是可以的
2. 安装spark大概是这里面最简单的事了吧点这里下载spark。鉴于我们已经安装好了hadoop,所以我们就下载一个不需要hadoop的spark包,就是这个with user-provided Hadoop这个 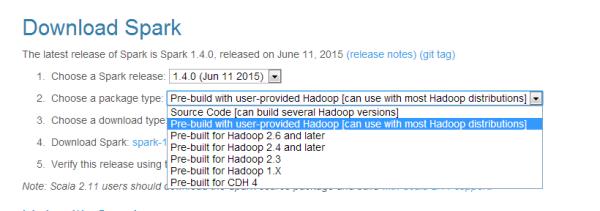
我用的是1.6.0好像大家用这个的比较多,最新的已经到2.1.x了。
解压到你想安装的目录
sudo tar -zxf ~/下载/spark-1.6.0-bin-without-hadoop.tgz -C /usr/local/cd /usr/localsudo mv ./spark-1.6.0-bin-without-hadoop/ ./sparksudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名1234
之后很重点的一步是修改spark-env.sh的内容,好像要改好多好多。。。
cd /usr/local/sparkcp ./conf/spark-env.sh.template ./conf/spark-env.shvim conf/spark-enf.sh123
这里是我的spark-env.sh的一些配置
export HADOOP_HOME=/home/ubuntu/workspace/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HADOOP_HDFS_HOME=/home/ubuntu/workspace/hadoopexport SPARK_DIST_CLASSPATH=$(/home/ubuntu/workspace/hadoop/bin/hadoop classpath)export JAVA_HOME=/home/ubuntu/workspace/jdk/export SCALA_HOME=/home/ubuntu/workspace/scalaexport SPARK_MASTER_IP=192.168.1.129export SPARK_WORKER_MEMORY=1Gexport SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORDER_INSTANCES=2export SPARK_EXECUTOR_INSTANCES=2123456789101112131415161718
属性不明白的可以打开spark-env.sh,里面前面又好多注释,讲各种属性的意思。(ps:这里有个SPARK_DIST_CLASSPATH一定要照着改对,否则会运行不起来)
这是给力星大大的教程写得很好。
3. 分布式spark部署
重点来了,当然,教程在这里
这里好像没什么坑,但是好像我记得刚开始的时候别的机器上的worker老是启动不起来,但是忘记是什么原因了,可能是免密登录没设置还是怎么的。
照着教程完成了之后,你就获得了spark的集群辣,撒花~(≧▽≦)/~
ps:这里还有个搭建standalone集群的简单介绍,Spark的Standalone模式安装部署
安装TensorflowOnSpark
这个真是说难也难,说简单真是巨简单,因为步骤github上已经写得好好的了,但是,有些坑,确实会把人坑死的。
雅虎开源的TensorflowOnSpark
1. 啥?你说全是英文看不懂,好吧我也看不懂,不过你想安装TensorflowOnSpark的话,应该拉到底点这里的wiki site 
2. 由于前面说了,我们用的是自带的standalone集群管理器,所以,就点 
3. 进入了教程之后,第一步复制粘贴,如果没git请按照提示安装git;
第二步不需要,因为你安装好了Spark了;第三步点进去那个instruction,或者你会发现你点不开(我就点不开。。。),你可以选择这里:tensorflow中文网。要注意的一点小坑是,在第三步的最后有一个测试
python $TFoS_HOME/tensorflow/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py --data_dir $TFoS_HOME/mnist1
如果你下载的是tensorflow1.x的版本,可能会有问题运行不出来,因此我下载的是0.12.1版本,啥,你问我怎么下,就是教程里的这句
$ pip install
里的0.5.0改成0.12.1就木有问题了。
还有就是那个mnist的数据集可能由于某些原因链接不上那个网址也下载不下来(我也是酱紫的。。。),可以到我的csdn上下载
4. 第四步就是启动spark了,其实直接启动就行了,底下那些乱七八糟的设置可以自行配置。
5. 第五步,把我坑成狗。。。需要像下面这么改,而这个cv.py其实就是改了文件输入的路径,好像本来是在hdfs上,我给改成本地的路径,噢,对了,这里的输出是输出到hdfs上,所以一定要打开hdfs啊,否则就GG了。
$SPARK_HOME/bin/spark-submit \\
--master spark://master:7077 \\$TFoS_HOME/examples/mnist/cv.py \\
--output examples/mnist/csv \\--format csv12345
cv.py的改动就是把mnist_data_setup.py第132,133行调用writeMNIST的方法的参数改了。具体见下图 
改动后是这样 
这个代码运行了之后去50070端口的hdfs查看你的文件就有了。 
6. 第六步是train,就是用刚才那个转换的数据进行训练模型,这里也需要改一些东西
$SPARK_HOME/bin/spark-submit \\
--master spark://master:7077 \\--py-files $TFoS_HOME/tfspark.zip,$TFoS_HOME/examples/mnist/spark/mnist_dist.py \\--conf spark.cores.max=4 \\--conf spark.task.cpus=2 \\--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \\$TFoS_HOME/examples/mnist/spark/mnist_spark.py \\
--cluster_size 2 \\--images examples/mnist/csv/train/images \\--labels examples/mnist/csv/train/labels \\--format csv \\--mode train \\--model mnist_model12345678910111213
注意有几个worker这个cluster_size就至少要设置成几,spark.task.cpu的数量要大于等于worker的数量。虽然都设置好了,也看起来像跑起来了,但是会被卡住不动。这时需要进入8080端口里看看worker的strerr,我这里曾经报错说没有设置 HADOOP_HDFS_HOME,这个需要在spark-env.sh里export一下,就设置成和HADOOP_HOME一样就行了。这只好了还是动,需要改一下mnist_spark.py的第109行,把logdir=logdir –>logdir=None(另外这里119行也同样改动,否则下一步识别的时候也会卡住)
7. 第七步的时候还是照常修改一些数(主要是我没设置这些),然后改一下代码。
$SPARK_HOME/bin/spark-submit \\
--master spark://master:7077 \\--py-files $TFoS_HOME/tfspark.zip,$TFoS_HOME/examples/mnist/spark/mnist_dist.py \\--conf spark.cores.max=4 \\--conf spark.task.cpus=2 \\--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \\$TFoS_HOME/examples/mnist/spark/mnist_spark.py \\
--cluster_size 2 \\--images examples/mnist/csv/test/images \\--labels examples/mnist/csv/test/labels \\--mode inference \\--format csv \\--model mnist_model \\--output predictions1234567891011121314
然后你愉快地发现你的hdfs上有了识别后的结果了
就像这样(强迫症地切割了下图片) 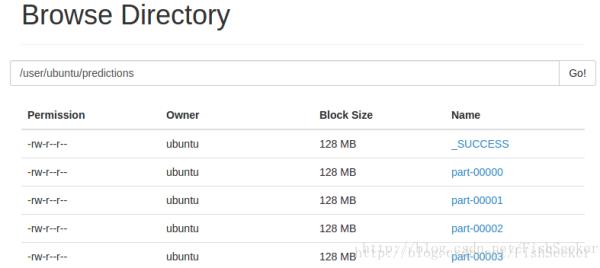
然后你打开个就看见了和网站上差不多的美妙结果。
如何在windows安装部署spark 求大神们的告知
参考技术A (1)安装JDK相对于Linux、Windows的JDK安装更加自动化,用户可以下载安装Oracle JDK或者OpenJDK。只安装JRE是不够的,用户应该下载整个JDK。
安装过程十分简单,运行二进制可执行文件即可,程序会自动配置环境变量。
(2)安装Cygwin
Cygwin是在Windows平台下模拟Linux环境的一个非常有用的工具,只有通过它才可以在Windows环境下安装Hadoop和Spark。具体安装步骤如下。
1)运行安装程序,选择install from internet。
2)选择网络最好的下载源进行下载。
3)进入Select Packages界面(见图2-2),然后进入Net,选择openssl及openssh。因为之后还是会用到ssh无密钥登录的。
另外应该安装“Editors Category”下面的“vim”。这样就可以在Cygwin上方便地修改配置文件。
最后需要配置环境变量,依次选择“我的电脑”→“属性”→“高级系统设置”→“环境变量”命令,更新环境变量中的path设置,在其后添加Cygwin的bin目录和Cygwin的usr\bin两个目录。
(3)安装sshd并配置免密码登录
1)双击桌面上的Cygwin图标,启动Cygwin,执行ssh-host-config -y命令,出现如图2-3所示的界面。
2)执行后,提示输入密码,否则会退出该配置,此时输入密码和确认密码,按回车键。最后出现Host configuration finished.Have fun!表示安装成功。
3)输入net start sshd,启动服务。或者在系统的服务中找到并启动Cygwin sshd服务。
注意,如果是Windows 8操作系统,启动Cygwin时,需要以管理员身份运行(右击图标,选择以管理员身份运行),否则会因为权限问题,提示“发生系统错误5”。
(4)配置SSH免密码登录
1)执行ssh-keygen命令生成密钥文件,如图2-4所示。
2)执行此命令后,在你的Cygwin\home\用户名路径下面会生成.ssh文件夹,可以通过命令ls -a /home/用户名 查看,通过ssh -version命令查看版本。
3)执行完ssh-keygen命令后,再执行下面命令,生成authorized_keys文件。
cd ~/.ssh/ cp id_dsa.pub authorized_keys
这样就配置好了sshd服务。
(5)配置Hadoop
修改和配置相关文件与Linux的配置一致,读者可以参照上文Linux中的配置方式,这里不再赘述。
(6)配置Spark
修改和配置相关文件与Linux的配置一致,读者可以参照上文Linux中的配置方式,这里不再赘述。
(7)运行Spark
1)Spark的启动与关闭
①在Spark根目录启动Spark。
./sbin/start-all.sh
②关闭Spark。
./sbin/stop-all.sh
2)Hadoop的启动与关闭
①在Hadoop根目录启动Hadoop。
./sbin/start-all.sh
②关闭Hadoop。
./sbin/stop-all.sh
3)检测是否安装成功
正常状态下会出现如下内容。
-bash-4.1# jps 23526 Jps 2127 Master 7396 NameNode 7594 SecondaryNameNode 7681 ResourceManager 1053 DataNode 31935 NodeManager 1405 Worker
如缺少进程请到logs文件夹下查看相应日志,针对具体问题进行解决。
以上是关于如何安装Spark amp;TensorflowOnSpark的主要内容,如果未能解决你的问题,请参考以下文章
如何在资源有限的笔记本电脑上安装 pyspark 和 spark 用于学习目的?