hadoop集群报错:There are 0 datanode(s) running and no node(s) are excluded in this operation
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop集群报错:There are 0 datanode(s) running and no node(s) are excluded in this operation相关的知识,希望对你有一定的参考价值。
参考技术A hadoop搭建完成,namenode format完成,start-all.sh成功。namenode与datanode均启动成功。./hdfs dfs -mkdir -p /data/hdfs/input完成
但是,
奇怪的事情发生了:
./hdfs dfs -put test.txt /data/hdfs/input失败;
实在是不懂hadoop,继续老套路,网上查资料,发现了以下几种可能:
查看发现了一个更神奇的现象:
master的/hdfs/name文件夹有current文件夹;node的/hdfs/data文件中什么都没有; datanode明明已经启动了T_T。
于是./stop-all.sh 再删除/hdfs/name/中所有内容,重新格式化,启动。发现没任何改变。排除该可能。
想了一下,master的防火墙还未做任何处理,应该是有端口没开放,查看进程占用了哪些端口,全部开放
将以上端口全部加入防火墙规则,重启,node的/hdfs/data文件夹出现了current文件夹;(主要是9000端口,ResourceManage的端口还不清楚干嘛用的,后面熟悉以后再补充)
但是./hdfs dfs -put test.txt /data/hdfs/input还是失败,最后发现还是防火墙问题,node的防火墙有端口未开放;
将node的50010端口开放。
终于成功了,阿西吧!
ENVI PCA unable to compute convarirance statistics because there are NaN pixels contained in this da
1.问题
计算到99%出现:
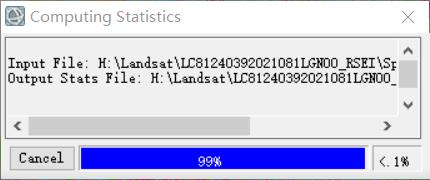
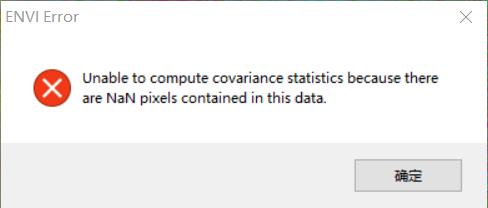
点击确定继续计算:
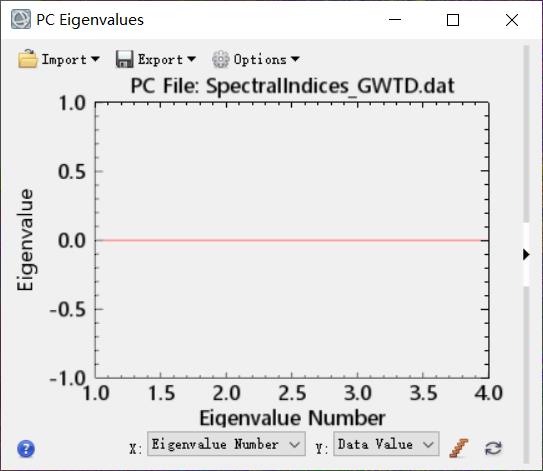
会计算出一个结果图层,也可以使用,但是关于统计分析的数据没有计算出来。
2.解决办法
2.1 使用ENVI拓展工具去除NaN值,通常改为0或者-9999.
2.2 另存为erdas可以识别的格式,然后使用erdas软件计算,没有报错,不过输出结果有问题,不推荐这个。
2.3 将数据进行归一化处理,因为使用的数据是采用多个指数通过LayerStack工具合并在一起的。使用Stretch Data工具归一化处理再做PCA正确输出结果。
以上是关于hadoop集群报错:There are 0 datanode(s) running and no node(s) are excluded in this operation的主要内容,如果未能解决你的问题,请参考以下文章
hadoop报错:There are 653 missing blocks. The following files may be corrupted
hadoop报错:There are 653 missing blocks. The following files may be corrupted
hadoop报错:There are 653 missing blocks. The following files may be corrupted
hadoop报错:There are 653 missing blocks. The following files may be corrupted
There are 0 datanode(s) running and no node(s) are excluded in this operation.
ENVI PCA unable to compute convarirance statistics because there are NaN pixels contained in this da