awk原理
Posted cherish the present
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了awk原理相关的知识,希望对你有一定的参考价值。
Linux Shell编程 awk命令
概述
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
命令的基本格式如下:
[root@localhost ~]# awk \'条件1 执行语句 1 条件 2 执行语句 2 …\' 文件名
在awk编程中,因为命令语句非常长,所以在输入格式时需要注意以下内容:
-
多个条件动作可以用空格分隔,也可以用回车分隔。
-
在一个动作中,如果需要执行多条命令,则需要用分隔,或用回车分隔。
-
在awk中,变量的赋值与调用都不需要加入"$"符号。
条件(Pattern):
一般使用关系表达式作为条件。这些关系表达式非常多 。
| 条件类型 | 条 件 | 说 明 |
|---|---|---|
| awk保留字 | BEGIN | 在 awk 程序一开始,尚未读取任何数据之前执行。BEGIN 后的动作只在程序开始时执行一次 |
| awk保留字 | END | 在 awk 程序处理完所有数据,即将结束时执行?END 后的动作只在程序结束时执行一次 |
| 关系运算符 | > | 大于 |
| < | 小于 | |
| >= | 大于等于 | |
| <= | 小于等于 | |
| == | 等于。用于判断两个值是否相等。如果是给变童赋值,则使用"=” | |
| != | 不等于 | |
| A~B | 判断字符串 A 中是否包含能匹配 B 表达式的子字符串 | |
| A!~B | 判断字符串 A 中是否不包含能匹配 B 表达式的子字符串 | |
| 正则表达式 | /正则/ | 如果在“//”中可以写入字符,则也可以支持正则表达式 |
awk常见的内置变量
|
awk 内置变量 |
说明 |
| $0 | 当前记录(作为单个变量) |
| $1~$n | 当前记录的第n个字段,字段间由FS分隔 |
| FS | 输入字段分隔符, 默认为空白字符 |
| OFS | 输出字段分隔符, 默认为空白字符 |
| RS | 输入记录分隔符(输入换行符), 指定输入时的换行符 |
| ORS | 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 |
| NF | 当前行的字段的个数(即当前行被分割成了几列),字段数量 |
| NR | 当前处理的文本行的行号 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGC | 命令行参数的个数 |
| ARGV | 数组,保存的是命令行所给定的各参数 |
awk命令示例
awk命令基本示例
列出 student.txt 文件的第二个字段和第六个字段,"$2"和"$6"分别代表第二个字段和第六个字段。
[root@localhost ~]# awk \'printf $2 "\\t" $6 "\\n"\' student.txt#输出第二列和第六列的内容Name AverageLiming 87.66Sc 85.66Gao 91.66
对于 awk 命令来说,只要分隔开,不管是空格还是制表符,都可以识别。 命令如下:
[root@localhost ~]#df -h | awk \'print $1 "\\t" $3\'文件系统 已用/dev/sda3 1.8Gtmpfs 0/dev/sda1 26M/dev/sr0 3.5G
在这两个例子中,如果使用 printf 动作,就必须在最后加入"\\n",因为 printf 只能识别标准输出格式;如果我们不使用"\\n",它就不会换行。而 print 动作则会在每次输出后自动换行,所以不用在最后加入"\\n"。
awk使用条件的示例
BEGIN 是 awk 的保留字,是一种特殊的条件类型。BEGIN 的执行时机是"在 awk 程序一开始,尚未读取任何数据之前"。一旦 BEGIN 后的动作执行一次,当 awk 开始从文件中读入数据时,BEGIN 的条件就不再成立,所以 BEGIN 定义的动作只能被执行一次。例如:
[root@localhost ~]# awk \'BEGINprintf "This is a transcript\\n"printf $2 "\\t" $6 "\\n"\' student.txtThis is a transcriptName AverageLiming 87.66Sc 85.66Gao 91.66
awk命令只要检测不到完整的单引号就不会执行,所以这条命令的换行不用加入"\\",就是一行命令。首先使用BEGIN条件在读入文件数据前打印"这是一张成绩单"(只会执行一次),再打印文件的第二个字段和第六个字段。
END 是在 awk 程序处理完所有数据,即将结束时执行的。END 后的动作只在程序结束时执行一次。例如:
[root@localhost ~]# awk \'ENDprintf "The End \\n"printf $2 "\\t" $6 "\\n"\' student.txtName AverageLiming 87.66Sc 85.66Gao 91.66The End
查看平均成绩大于等于 87 分的学员,就可以这样输入命令:
[root@localhost ~]# cat student.txt | grep -v Name |awk\'$6 >= 87 printf $2\'\\n"\'LimingGao
使用cat输出文件内容,用grep取反包含"Name"的行
判断第六个字段(平均成绩)大于等于87分的行,如果判断式成立,则打印第2列学员名
查看Sc用户的平均成绩
[root@localhost ~]# awk\'$2 -/Sc/ printf $6 "\\n"\' student.txt85.66
如果第二个字段中包含"Sc"字符,则打印第六个字段
在 awk 中,只有使用"//"包含的字符串,awk 命令才会査找。也就是说,字符串必须用"//"包含,awk 命令才能正确识别。
査看系统分区的使用情况而不想査看光盘和临时分区的使用情况时,可以只查询包含"sda数字"的行,并打印第一个字段和第五个字段
[root@localhost ~]# df -h | awk \'/sda[0-9]/ printf $1 \'\\t\\ $5 "\\n"\'/dev/sda3 10%/dev/sda1 15%
awk使用内置变量的示例
在 awk 中允许定义变量,允许使用运算符,允许使用流程控制语句和定义函数。这样就使得 awk 编程成了一门完整的程序语言,当然难度也比普通的命令要大得多。
创建文件
[root@localhost ~]# cat student.txtID Name PHP Linux MySQL Average1 Liming 82 95 86 87.662 Sc 74 96 87 85.663 Gao 99 83 93 91.66
在 awk 中定义变量与调用变量的值。假设统计 PHP 成绩的总分:
[root@localhost ~]# awk\'NR==2php1 =$3NR==3php2=$3NR==4php3= $3;totle=php1+php2+php3;print "totle php is" totle\' student.txttotle php is 255
说明:
-
"NR==2php1=$3"(条件是NR==2,动作是php=$3) 是指如果输入数据是第二行(第一行是标题行),就把第二行的第三个字段的值赋予变量"php1"。
-
"NR==3php2=$3"是指如果输入数据是第三行,就把第三行的第三个字段的值赋予变量"php2"。NR==4php3=$3;totle=php1+php2+php3;print"totle php is"totle"("NR==4"是条件,后面中的都是动作)是指如果输入数是第四行,就把第四行的第三个字段的值赋予变量"php3";然后定义变量 totle 的值是"php1+php2+php3";最后输出"totle php is"关键字,后面加变量 totle 的值。
查看Linux 成绩大于 90 分的用户,命令如下:
[root@localhost ~]# awk\' NR>=2 test=$4test>90 printf $2" \\n"\' student.txtLimingSc
先判断行号,如果大于2,就把第四个字段的值赋予变量test
再判断成绩,如果test的值大于90分,就打印好男人

- 内容质量低
- 不看此公众号

- 内容质量低
- 不看此公众号

- 内容质量低
- 不看此公众号

shell的文本三剑客awk
awk的工作原理
- 逐行读取文本,默认以空格或t.ab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
- sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示
- 在使用awk命令的过程中,可以使用逻辑操作符"&a”表示"与”、“II"表示"或”、"!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方
命令格式
awk 选项 '模式或条件 {操作}' 文件1 文件2....
awk -f脚本文件 文件1 文件2...
awk常见内建变量
- FS:列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
- NF:当前处理的行的字段个数。
- NR:当前处理的行的行号(序数)。
- $0:当前处理的行的整行内容。
- $n:当前处理行的第n个字段(第n列)。
- FILENAME:被处理的文件名。
- RS:行分隔符。awk从文件上读取资料时,将根据Rs的定义把资料切割成许多条记录, 而awk一次仅读入一条记录,以进行处理。预设值是"\\n’
awk '{print}' sed.txt #输出文件所有内容
等同于
awk '{print $0}' sed.txt #输出文件所有内容
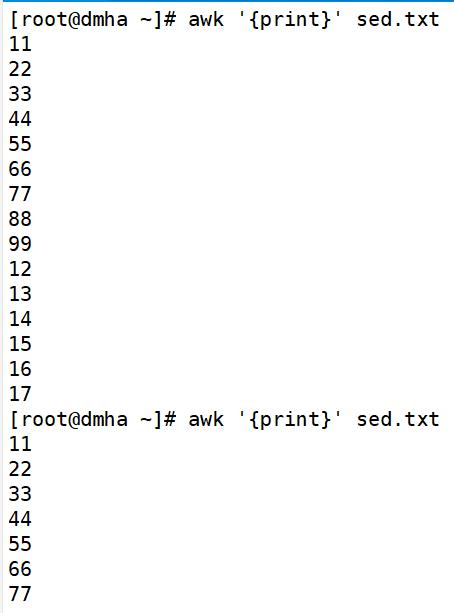
awk 'NR==1,NR==3{print}' sed.txt #输出第1~3行的内容
等同于
awk '(NR>=1)&&(NR<=3){print}' sed.txt #输出第1~3行的内容
awk 'NR==1||NR==3{print}' sed.txt #输出第一行、第三行的内容

awk '(NR%2)==1{print}' sed.txt #输出所有奇数行的内容
awk '(NR%2)==o{print}' sed.txt #输出所有偶数行的内容

awk '/^root/{print}' /etc/passwd #输出以root开头的行

awk '/nologin$/{print}' /etc/passwd #输出以nologin结尾的行

awk 'BEGIN {x=0};/\\/bin\\/bash$/{x++};END {print x}' /etc/passwd #统计以/bin/bash结尾的行数
等同于
grep -c "/bin/bash" /etc/passwd
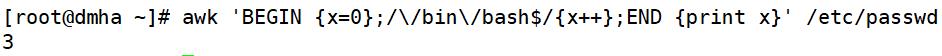
注:BBGITN模式表示,在处理指定的文本之前,需要先执行BBGIN模式中指定的动作; awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句
按字段输出文本
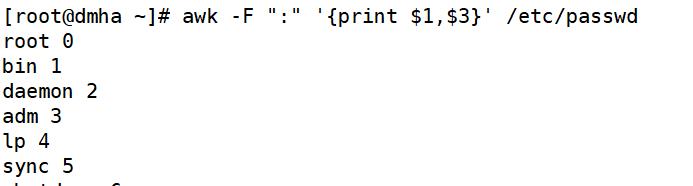
awk -F ":" '{print $1,$3}' /etc/passwd #以:为分割,输出每行第1个、第3个字段
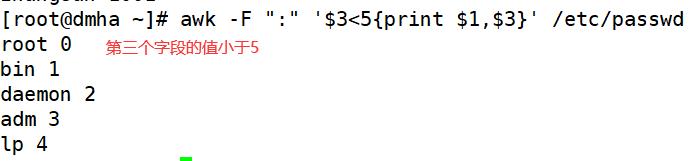
awk -F ":" '$3<5{print $1,$3}' /etc/passwd #输出第3个字段小于5的每行第1个、第3个字段
awk -F ":" '!($3<200){print}' /etc/passwd #输出第3个字段不小于200的
等同于
awk 'BEGIN {FS=":"};{if($3>=200){print}}' /etc/passwd #先处理完BEGIN的内容,再打印结果
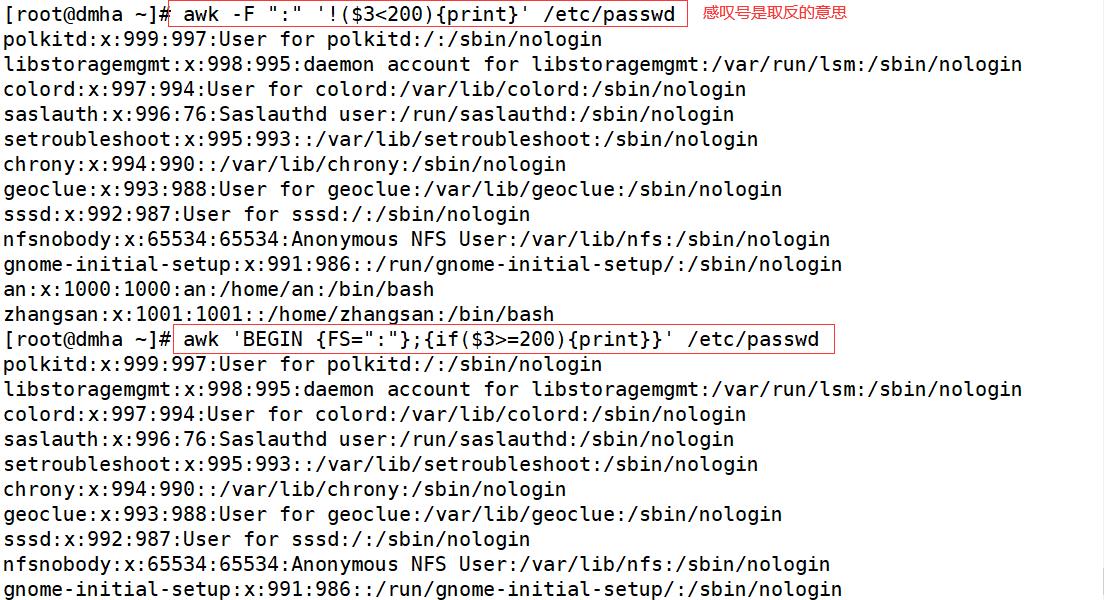
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc//passwd
#($3>$4)?$3:$4三元运算符,如果第3个字段的值大于第4个字段的值,则把第3个字段的值赋给max,否则第4个字段的值赋给max
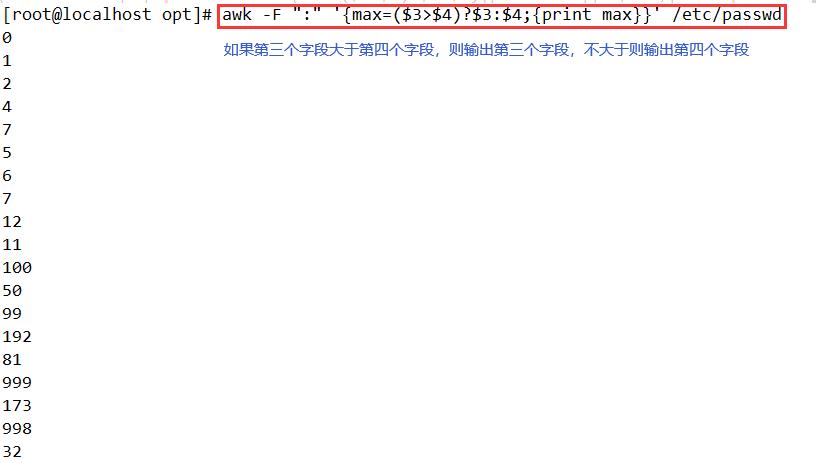
awk -F ":" '{print NR,$0}' /etc/passwd
#输出每行内容和行号,每处理完一条记录,NR值加1
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd
#输出以冒号分隔且第7个字段中包含/bash的行的第1个字段

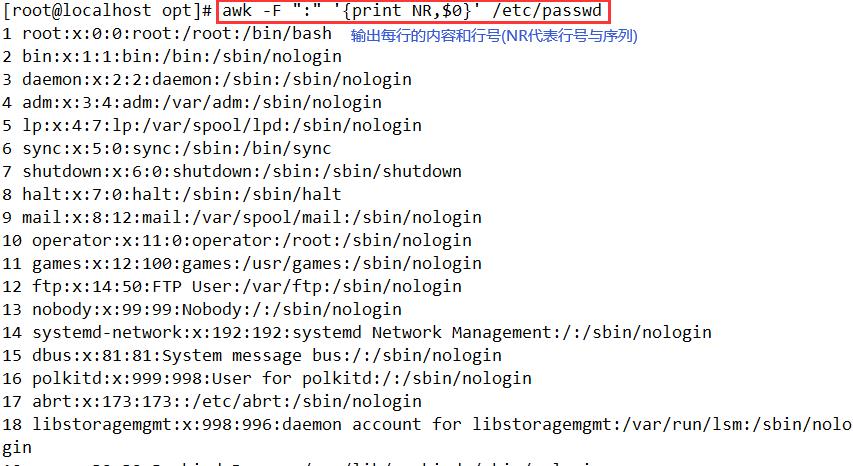
awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd
#输出第1个字段中包含root且有7个字段的行的第1、2个字段
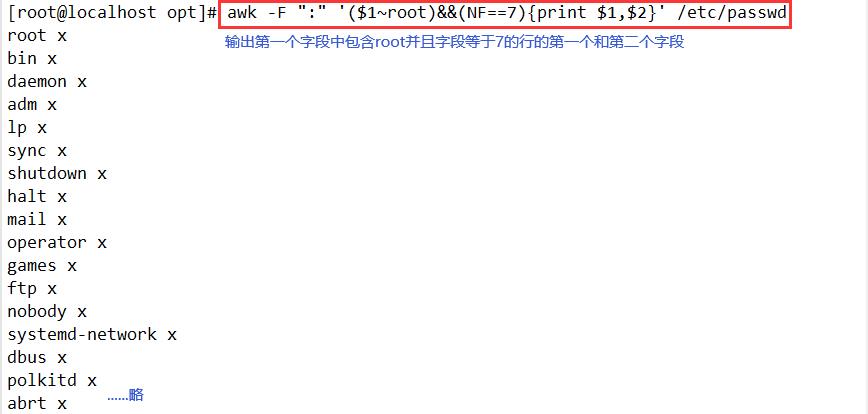
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd
#输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行

通过管道符号、双引号调用shell 命令
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}'
#统计以冒号分隔的文本段落数,END{}语句块中,往往会放入打印结果等语句

awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
#调用 wc -l 命令统计使用 bash 的用户个数,等同于 grep -c "bash$" /etc/passwd

free -m | awk '/Mem:/ {print int($3/($3+$4)*100)}'
#查看当前内存使用百分比

top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}'
#查看当前CPU空闲率,(-b -n 1 表示只需要1次的输出结果)

date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S"
#显示上次系统重启时间,等同于uptime;second ago为显示多少秒前的时间,+"%F %H:%M:%S"等同于+"%Y-%m-%d %H:%M:%S"的时间格式

awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}"%"}'
#调用w命令,并用来统计在线用户数

awk 'BEGIN {"hostname" | getline ; {print $0}}'
#调用 hostname,并输出当前的主机名

ps:
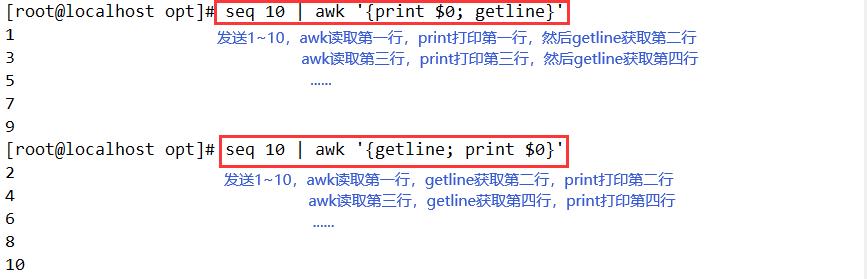
- 当getline左右无重定向符“<”或“|”时,getline作用于当前文件,读入当前文件的第一行给其后跟的变量var或$0;应该注意到,由于awk在处理getline之前已经读入了一行,所以getline得到的返回结果是隔行的
- 当getline左右有重定向符“<”或“|”时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行
seq 10 | awk '{print $0; getline}'
seq 10 | awk '{getline; print $0}'
以上是关于awk原理的主要内容,如果未能解决你的问题,请参考以下文章