如何用Golang处理每分钟100万个请求
Posted 杨建勇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Golang处理每分钟100万个请求相关的知识,希望对你有一定的参考价值。
用Golang处理每分钟100万个请求
转载请注明来源:https://janrs.com/9yaq
面临的问题
在我设计一个分析系统中,我们公司的目标是能够处理来自数百万个端点的大量POST请求。web 网络处理程序将收到一个JSON文档,其中可能包含许多有效载荷的集合,需要写入Amazon S3,以便我们的地图还原系统随后对这些数据进行操作。
传统上,我们会研究创建一个工人层架构,利用诸如以下东西:
- Sidekiq
- Resque
- DelayedJob
- Elasticbeanstalk Worker Tier
- RabbitMQ
- 还有等等其他的技术手段...
并设置 2 个不同的集群,一个用于 Web 前端,另一个用于 worker 处理进程,这样我们就可以扩大我们可以处理的后台工作量。
但从一开始,我们的团队就知道我们应该在 Go 中这样做,因为在讨论阶段我们看到这可能是一个非常大的流量系统。 我使用 Go 已有大约 2 年左右的时间,我们公司在处理业务时开发了一些系统,但没有一个能承受如此大的负载。以下是优化的过程。
我们首先创建一些结构体来定义我们将通过 POST 调用接收的 Web 请求负载,以及一种将其上传到我们的 S3 存储桶的方法。代码如下:
type PayloadCollection struct
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
type Payload struct
// ...负载字段
func (p *Payload) UploadToS3() error
// storageFolder 方法确保在我们在键名中获得相同时间戳时不会发生名称冲突
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil
return encodeErr
// 我们发布到 S3 存储桶的所有内容都应标记为“私有”
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options)
使用 Go 协程
最初我们采用了一个非常简单的 POST 处理程序实现,只是试图将job 处理程序并行化到一个简单的 goroutine 中:
func payloadHandler(w http.ResponseWriter, r *http.Request)
if r.Method != "POST"
w.WriteHeader(http.StatusMethodNotAllowed)
return
// 将body读入字符串进行json解码
var content = &PayloadCollection
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads
go payload.UploadToS3() // <----- 这是不建议的做法。这里是最开始的做法。
w.WriteHeader(http.StatusOK)
对于中等负载,这可能适用于大多数公司的流量,但很快证明这在大规模情况下效果不佳。 我们期望有很多请求,但没有达到我们将第一个版本部署到生产环境时开始看到的数量级。 我们完全低估了流量。
上面的方法在几个不同的方面是不好的。 无法控制我们生成了多少个 go routines。 由于我们每分钟收到 100 万个 POST 请求,因此这段代码很快崩溃了。
进一步优化
我们需要找到一种不同的方式。 从一开始我们就开始讨论我们需要如何保持请求处理程序的生命周期非常短,并在后台进行生成处理。 当然,这是你在使用 Ruby on Rails 时必须做的,否则你将阻止所有可用的 worker web 处理器,无论你使用的是 puma、unicorn 还是 passenger(请不要进入 JRuby 讨论)。 然后我们需要利用常见的解决方案来做到这一点,例如 Resque、Sidekiq、SQS 等等,有很多方法可以实现这一点。
所以第二次迭代是创建一个缓冲通道,我们可以创建一些队列,然后把 job push到队列并将它们上传到 S3,并且由于我们可以控制job 队列中的最大数数量并且我们有足够的内存来处理队列中的 job。在这个方案中,我们认为只需要在通道队列中缓冲需要处理的 job 就可以了。
代码如下:
var Queue chan Payload
func init()
Queue = make(chan Payload, MAX_QUEUE)
func payloadHandler(w http.ResponseWriter, r *http.Request)
...
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads
Queue <- payload // <----- 这是建议的做法。
...
然后为了实际出列作业并处理它们,我们使用了类似的东西:
func StartProcessor()
for
select
case job := <-Queue:
job.payload.UploadToS3() // <-- 这里虽然优化了,但还不是最好的。
在上面的代码中,我们用一个缓冲队列来交换有缺陷的并发性,而缓冲队列只是推迟了问题。 我们的同步处理器一次只将一个有效负载上传到 S3,并且由于传入请求的速率远远大于单个处理器上传到 S3 的能力,我们的 job 缓冲通道很快达到了极限并阻止了请求处理程序的能力,队列很快就阻塞满了。
我们只是在避免这个问题,并开始倒计时,直到我们的系统最终死亡。 在我们部署这个有缺陷的版本后,我们的延迟率在几分钟内以恒定的速度持续增加。以下是延迟率增长图:

更好的解决方案
我们决定在使用 Go 通道时使用一种通用模式,以创建一个 2 层通道系统,一个用于 Job 队列,另一个用于控制同时在 Job 队列上操作的 Worker 的数量。
这个想法是将上传到 S3 的数据并行化到某种程度上可持续的速度,这种速度既不会削弱机器也不会开始从 S3 生成连接错误。 所以我们选择创建 Job/Worker 模式。 对于那些熟悉 Java、C# 等的人来说,可以将其视为 Golang 使用通道实现 Worker 线程池的方式。
代码如下:
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job 表示要运行的作业
type Job struct
Payload Payload
// 我们可以在 Job 队列上发送工作请求的缓冲通道。
var JobQueue chan Job
// Worker 代表执行作业的 Worker。
type Worker struct
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
func NewWorker(workerPool chan chan Job) Worker
return Worker
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)
// Start 方法为 Worker 启动循环监听。监听退出信号以防我们需要停止它。
func (w Worker) Start()
go func()
for
// 将当前 woker 注册到工作队列中。
w.WorkerPool <- w.JobChannel
select
case job := <-w.JobChannel:
// 接收 work 请求。
if err := job.Payload.UploadToS3(); err != nil
log.Errorf("Error uploading to S3: %s", err.Error())
case <-w.quit:
// 接收一个退出的信号。
return
()
// 将退出信号传递给 Worker 进程以停止处理清理。
func (w Worker) Stop()
go func()
w.quit <- true
()
我们已经修改了我们的 Web 请求处理程序,以创建一个带有有效负载的 Job 结构实例,并将其发送到 JobQueue 通道以供 Worker 提取。
func payloadHandler(w http.ResponseWriter, r *http.Request)
if r.Method != "POST"
w.WriteHeader(http.StatusMethodNotAllowed)
return
// 将body读入字符串进行json解码
var content = &PayloadCollection
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
// 分别检查每个有效负载和队列项目以发布到 S3
for _, payload := range content.Payloads
// 创建一个有效负载的job
work := JobPayload: payload
// 将 work push 到队列。
JobQueue <- work
w.WriteHeader(http.StatusOK)
在我们的 Web 服务器初始化期间,我们创建一个 Dispatcher 调度器并调用 Run() 来创建 Woker 工作池并开始侦听将出现在 Job 队列中的 Job。
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()
下面是我们的调度程序实现的代码:
type Dispatcher struct
// 通过调度器注册一个 Worker 通道池
WorkerPool chan chan Job
func NewDispatcher(maxWorkers int) *Dispatcher
pool := make(chan chan Job, maxWorkers)
return &DispatcherWorkerPool: pool
func (d *Dispatcher) Run()
// 启动指定数量的 Worker
for i := 0; i < d.maxWorkers; i++
worker := NewWorker(d.pool)
worker.Start()
go d.dispatch()
func (d *Dispatcher) dispatch()
for
select
case job := <-JobQueue:
// 接收一个 job 请求
go func(job Job)
// 尝试获取可用的 worker job 通道
// 这将阻塞 worker 直到空闲
jobChannel := <-d.WorkerPool
// 调度一个 job 到 worker job 通道
jobChannel <- job
(job)
请注意,我们提供了要实例化并添加到我们的 Worker 池中的最大worker 数量。 由于我们在这个项目中使用了 Amazon Elasticbeanstalk 和 dockerized Go 环境,因此我们从环境变量中读取这些值。 这样我们就可以控制 Job 队列的数量和最大大小,因此我们可以快速调整这些值而无需重新部署集群。
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
在我们部署它之后,我们立即看到我们所有的延迟率都下降到极低的延迟,并且我们处理请求的能力急剧上升。以下是流量截图:
在我们的弹性负载均衡器完全预热几分钟后,我们看到我们的 ElasticBeanstalk 应用程序每分钟处理近 100 万个请求。 我们通常在早上有几个小时的流量会飙升至每分钟超过一百万。
一旦我们部署了新代码,服务器数量就从 100 台服务器大幅下降到大约 20 台服务器。以下是服务器数量变化截图:
在正确配置集群和自动缩放设置后,我们能够将其进一步降低到仅 4x EC2 c4.Large 实例,并且如果 CPU 使用率超过 90% 持续 5 天,Elastic Auto-Scaling 将生成一个新实例 分钟值。以下是截图:
总结
可以看出利用 Elasticbeanstalk 自动缩放的强大功能以及 Golang 提供的开箱即用的高效和简单的并发方法,就可以构建出一个高性能的处理程序。
转载请注明来源:https://janrs.com/9yaq
海量数据问题: 如何用JAVA几分钟处理完30亿个数据?
目录
一、场景说明
现有一个10G文件的数据,里面包含了18-70之间的整数,分别表示18-70岁的人群数量统计,假设年龄范围分布均匀,分别表示系统中所有用户的年龄数,找出重复次数最多的那个数,现有一台内存为4G、2核CPU的电脑,请写一个算法实现。
23,31,42,19,60,30,36,........
二、模拟数据
Java中一个整数占4个字节,模拟10G为30亿左右个数据, 采用追加模式写入10G数据到硬盘里。
每100万个记录写一行,大概4M一行,10G大概2500行数据。
package bigdata;
import java.io.*;
import java.util.Random;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:05
*/
public class GenerateData
private static Random random = new Random();
public static int generateRandomData(int start, int end)
return random.nextInt(end - start + 1) + start;
/**
* 产生10G的 1-1000的数据在D盘
*/
public void generateData() throws IOException
File file = new File("D:\\\\ User.dat");
if (!file.exists())
try
file.createNewFile();
catch (IOException e)
e.printStackTrace();
int start = 18;
int end = 70;
long startTime = System.currentTimeMillis();
BufferedWriter bos = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file, true)));
for (long i = 1; i < Integer.MAX_VALUE * 1.7; i++)
String data = generateRandomData(start, end) + ",";
bos.write(data);
// 每100万条记录成一行,100万条数据大概4M
if (i % 1000000 == 0)
bos.write("\\n");
System.out.println("写入完成! 共花费时间:" + (System.currentTimeMillis() - startTime) / 1000 + " s");
bos.close();
public static void main(String[] args)
GenerateData generateData = new GenerateData();
try
generateData.generateData();
catch (IOException e)
e.printStackTrace();
上述代码调整参数执行2次, 凑10个G的数据在D盘的User.dat文件里: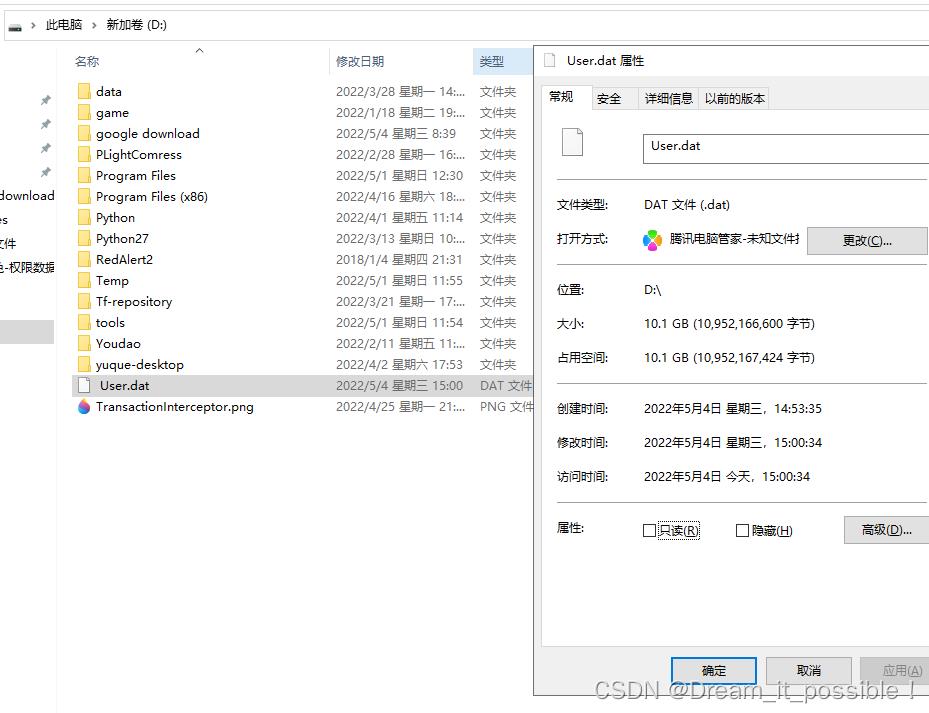
准备好10G数据后,接着写如何处理这些数据
三、场景分析
10G的数据比当前拥有的运行内存大的多,不能全量加载到内存中读取,如果采用全量加载,那么内存会直接爆掉,只能按行读取,Java中的bufferedReader的readLine()按行读取文件里的内容。
四、读取数据
首先我们写一个方法单线程读完这30E数据需要多少时间,每读100行打印一次:
private static void readData() throws IOException
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null)
// 按行读取
// SplitData.splitLine(line);
if (count % 100 == 0)
System.out.println("读取100行,总耗时间: " + (System.currentTimeMillis() - start) / 1000 + " s");
System.gc();
count++;
running = false;
br.close();
按行读完10G的数据大概20秒,基本每100行,1E多数据花1S,速度还挺快:

五、处理数据
思路一
通过单线程处理,初始化一个countMap, key为年龄,value为出现的次数, 将每行读取到的数据按照"," 进行分割,然后获取到的每一项进行保存到countMap里,如果存在,那么值key的value+1。
for (int i = start; i <= end; i++)
try
File subFile = new File(dir + "\\\\" + i + ".dat");
if (!file.exists())
subFile.createNewFile();
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
catch (FileNotFoundException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
单线程读取并统计countMap:
public static void splitLine(String lineData)
String[] arr = lineData.split(",");
for (String str : arr)
if (StringUtils.isEmpty(str))
continue;
countMap.computeIfAbsent(str, s -> new AtomicInteger(0)).getAndIncrement();
通过比较找出年龄数最多的年龄并打印出来:
private static void findMostAge()
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext())
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue)
targetValue = value;
targetKey = key;
System.out.println("数量最多的年龄为:" + targetKey + "数量为:" + targetValue);
完整代码
package bigdata;
import org.apache.commons.lang3.StringUtils;
import java.io.*;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:19
* 单线程处理
*/
public class HandleMaxRepeatProblem_v0
public static final int start = 18;
public static final int end = 70;
public static final String dir = "D:\\\\dataDir";
public static final String FILE_NAME = "D:\\\\ User.dat";
/**
* 统计数量
*/
private static Map<String, AtomicInteger> countMap = new ConcurrentHashMap<>();
/**
* 开启消费的标志
*/
private static volatile boolean startConsumer = false;
/**
* 消费者运行保证
*/
private static volatile boolean consumerRunning = true;
/**
* 按照 "," 分割数据,并写入到countMap里
*/
static class SplitData
public static void splitLine(String lineData)
String[] arr = lineData.split(",");
for (String str : arr)
if (StringUtils.isEmpty(str))
continue;
countMap.computeIfAbsent(str, s -> new AtomicInteger(0)).getAndIncrement();
/**
* init map
*/
static
File file = new File(dir);
if (!file.exists())
file.mkdir();
for (int i = start; i <= end; i++)
try
File subFile = new File(dir + "\\\\" + i + ".dat");
if (!file.exists())
subFile.createNewFile();
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
catch (FileNotFoundException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
public static void main(String[] args)
new Thread(() ->
try
readData();
catch (IOException e)
e.printStackTrace();
).start();
private static void readData() throws IOException
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null)
// 按行读取,并向map里写入数据
SplitData.splitLine(line);
if (count % 100 == 0)
System.out.println("读取100行,总耗时间: " + (System.currentTimeMillis() - start) / 1000 + " s");
try
Thread.sleep(1000L);
catch (InterruptedException e)
e.printStackTrace();
count++;
findMostAge();
br.close();
private static void findMostAge()
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext())
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue)
targetValue = value;
targetKey = key;
System.out.println("数量最多的年龄为:" + targetKey + "数量为:" + targetValue);
private static void clearTask()
// 清理,同时找出出现字符最大的数
findMostAge();
System.exit(-1);
测试结果
总共花了3分钟读取完并统计完所有数据:
 内存消耗为2G-2.5G, CPU利用率太低,只向上浮动了20%-25%之间:
内存消耗为2G-2.5G, CPU利用率太低,只向上浮动了20%-25%之间:

要想提高CPU的利用率,那么可以使用多线程去处理。
下面我们使用多线程去解决这个CPU利用率低的问题
思路二分治法
使用多线程去消费读取到的数据。 采用生产者、消费者模式去消费数据,因为在读取的时候是比较快的,单线程的数据处理能力比较差,因此思路一的性能阻塞在取数据方,又是同步的,所以导致整个链路的性能会变的很差。
所谓分治法就是分而治之,也就是说将海量数据分割处理。 根据CPU的能力初始化n个线程,每一个线程去消费一个队列,这样线程在消费的时候不会出现抢占队列的问题,同时为了保证线程安全和生产者消费者模式的完整,采用阻塞队列,Java中提供了LinkedBlockingQueue就是一个阻塞队列。
初始化阻塞队列
使用linkedList创建一个阻塞队列列表:
private static List<LinkedBlockingQueue<String>> blockQueueLists = new LinkedList<>();
在static块里初始化阻塞队列的数量和单个阻塞队列的容量为256, 上面讲到了30E数据大概2500行,按行塞到队列里,20个队列,那么每个队列125个,因此可以容量可以设计为256即可:
//每个队列容量为256
for (int i = 0; i < threadNums; i++)
blockQueueLists.add(new LinkedBlockingQueue<>(256));
生产者
为了实现负载的功能, 首先定义一个count计数器,用来记录行数:
private static AtomicLong count = new AtomicLong(0);
按照行数来计算队列的下标: long index=count.get()%threadNums。 下面算法就实现了对队列列表中的队列进行轮询的投放:
static class SplitData
public static void splitLine(String lineData)
// System.out.println(lineData.length());
String[] arr = lineData.split("\\n");
for (String str : arr)
if (StringUtils.isEmpty(str))
continue;
long index = count.get() % threadNums;
try
// 如果满了就阻塞
blockQueueLists.get((int) index).put(str);
catch (InterruptedException e)
e.printStackTrace();
count.getAndIncrement();
消费者
队列线程私有化
消费方在启动线程的时候根据index去获取到指定的队列,这样就实现了队列的线程私有化。
private static void startConsumer() throws FileNotFoundException, UnsupportedEncodingException
//如果共用一个队列,那么线程不宜过多,容易出现抢占现象
System.out.println("开始消费...");
for (int i = 0; i < threadNums; i++)
final int index = i;
// 每一个线程负责一个queue,这样不会出现线程抢占队列的情况。
new Thread(() ->
while (consumerRunning)
startConsumer = true;
try
String str = blockQueueLists.get(index).take();
countNum(str);
catch (InterruptedException e)
e.printStackTrace();
).start();
多子线程分割字符串
由于从队列中多到的字符串非常的庞大,如果又是用单线程调用split(",")去分割,那么性能同样会阻塞在这个地方。
// 按照arr的大小,运用多线程分割字符串
private static void countNum(String str)
int[] arr = new int[2];
arr[1] = str.length() / 3;
// System.out.println("分割的字符串为start位置为:" + arr[0] + ",end位置为:" + arr[1]);
for (int i = 0; i < 3; i++)
final String innerStr = SplitData.splitStr(str, arr);
// System.out.println("分割的字符串为start位置为:" + arr[0] + ",end位置为:" + arr[1]);
new Thread(() ->
String[] strArray = innerStr.split(",");
for (String s : strArray)
countMap.computeIfAbsent(s, s1 -> new AtomicInteger(0)).getAndIncrement();
).start();
分割字符串算法
分割时从0开始,按照等分的原则,将字符串n等份,每一个线程分到一份。
用一个arr数组的arr[0] 记录每次的分割开始位置, arr[1] 记录每次分割的结束位置,如果遇到的开始的字符不为",", 那么就startIndex-1, 如果结束的位置不为",", 那么将endIndex向后移一位。
如果endIndex超过了字符串的最大长度,那么就把最后一个字符赋值给arr[1]。
/**
* 按照 x坐标 来分割 字符串,如果切到的字符不为“,”, 那么把坐标向前或者向后移动一位。
*
* @param line
* @param arr 存放x1,x2坐标
* @return
*/
public static String splitStr(String line, int[] arr)
int startIndex = arr[0];
int endIndex = arr[1];
char start = line.charAt(startIndex);
char end = line.charAt(endIndex);
if ((startIndex == 0 || start == ',') && end == ',')
arr[0] = endIndex + 1;
arr[1] = arr[0] + line.length() / 3;
if (arr[1] >= line.length())
arr[1] = line.length() - 1;
return line.substring(startIndex, endIndex);
if (startIndex != 0 && start != ',')
startIndex = startIndex - 1;
if (end != ',')
endIndex = endIndex + 1;
arr[0] = startIndex;
arr[1] = endIndex;
if (arr[1] >= line.length())
arr[1] = line.length() - 1;
return splitStr(line, arr);
完整代码
package bigdata;
import cn.hutool.core.collection.CollectionUtil;
import org.apache.commons.lang3.StringUtils;
import java.io.*;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.ReentrantLock;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:19
* 多线程处理
*/
public class HandleMaxRepeatProblem
public static final int start = 18;
public static final int end = 70;
public static final String dir = "D:\\\\dataDir";
public static final String FILE_NAME = "D:\\\\ User.dat";
private static final int threadNums = 20;
/**
* key 为年龄, value为所有的行列表,使用队列
*/
private static Map<Integer, Vector<String>> valueMap = new ConcurrentHashMap<>();
/**
* 存放数据的队列
*/
private static List<LinkedBlockingQueue<String>> blockQueueLists = new LinkedList<>();
/**
* 统计数量
*/
private static Map<String, AtomicInteger> countMap = new ConcurrentHashMap<>();
private static Map<Integer, ReentrantLock> lockMap = new ConcurrentHashMap<>();
// 队列负载均衡
private static AtomicLong count = new AtomicLong(0);
/**
* 开启消费的标志
*/
private static volatile boolean startConsumer = false;
/**
* 消费者运行保证
*/
private static volatile boolean consumerRunning = true;
/**
* 按照 "," 分割数据,并写入到文件里
*/
static class SplitData
public static void splitLine(String lineData)
// System.out.println(lineData.length());
String[] arr = lineData.split("\\n");
for (String str : arr)
if (StringUtils.isEmpty(str))
continue;
long index = count.get() % threadNums;
try
// 如果满了就阻塞
blockQueueLists.get((int) index).put(str);
catch (InterruptedException e)
e.printStackTrace();
count.getAndIncrement();
/**
* 按照 x坐标 来分割 字符串,如果切到的字符不为“,”, 那么把坐标向前或者向后移动一位。
*
* @param line
* @param arr 存放x1,x2坐标
* @return
*/
public static String splitStr(String line, int[] arr)
int startIndex = arr[0];
int endIndex = arr[1];
char start = line.charAt(startIndex);
char end = line.charAt(endIndex);
if ((startIndex == 0 || start == ',') && end == ',')
arr[0] = endIndex + 1;
arr[1] = arr[0] + line.length() / 3;
if (arr[1] >= line.length())
arr[1] = line.length() - 1;
return line.substring(startIndex, endIndex);
if (startIndex != 0 && start != ',')
startIndex = startIndex - 1;
if (end != ',')
endIndex = endIndex + 1;
arr[0] = startIndex;
arr[1] = endIndex;
if (arr[1] >= line.length())
arr[1] = line.length() - 1;
return splitStr(line, arr);
public static void splitLine0(String lineData)
String[] arr = lineData.split(",");
for (String str : arr)
if (StringUtils.isEmpty(str))
continue;
int keyIndex = Integer.parseInt(str);
ReentrantLock lock = lockMap.computeIfAbsent(keyIndex, lockMap -> new ReentrantLock());
lock.lock();
try
valueMap.get(keyIndex).add(str);
finally
lock.unlock();
// boolean wait = true;
// for (; ; )
// if (!lockMap.get(Integer.parseInt(str)).isLocked())
// wait = false;
// valueMap.computeIfAbsent(Integer.parseInt(str), integer -> new Vector<>()).add(str);
//
// // 当前阻塞,直到释放锁
// if (!wait)
// break;
//
//
/**
* init map
*/
static
File file = new File(dir);
if (!file.exists())
file.mkdir();
//每个队列容量为256
for (int i = 0; i < threadNums; i++)
blockQueueLists.add(new LinkedBlockingQueue<>(256));
for (int i = start; i <= end; i++)
try
File subFile = new File(dir + "\\\\" + i + ".dat");
if (!file.exists())
subFile.createNewFile();
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
// lockMap.computeIfAbsent(i, lock -> new ReentrantLock());
catch (FileNotFoundException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
public static void main(String[] args)
new Thread(() ->
try
// 读取数据
readData();
catch (IOException e)
e.printStackTrace();
).start();
new Thread(() ->
try
// 开始消费
startConsumer();
catch (FileNotFoundException e)
e.printStackTrace();
catch (UnsupportedEncodingException e)
e.printStackTrace();
).start();
new Thread(() ->
// 监控
monitor();
).start();
/**
* 每隔60s去检查栈是否为空
*/
private static void monitor()
AtomicInteger emptyNum = new AtomicInteger(0);
while (consumerRunning)
try
Thread.sleep(10 * 1000);
catch (InterruptedException e)
e.printStackTrace();
if (startConsumer)
// 如果所有栈的大小都为0,那么终止进程
AtomicInteger emptyCount = new AtomicInteger(0);
for (int i = 0; i < threadNums; i++)
if (blockQueueLists.get(i).size() == 0)
emptyCount.getAndIncrement();
if (emptyCount.get() == threadNums)
emptyNum.getAndIncrement();
// 如果连续检查指定次数都为空,那么就停止消费
if (emptyNum.get() > 12)
consumerRunning = false;
System.out.println("消费结束...");
try
clearTask();
catch (Exception e)
System.out.println(e.getCause());
finally
System.exit(-1);
private static void readData() throws IOException
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null)
// 按行读取,并向队列写入数据
SplitData.splitLine(line);
if (count % 100 == 0)
System.out.println("读取100行,总耗时间: " + (System.currentTimeMillis() - start) / 1000 + " s");
try
Thread.sleep(1000L);
System.gc();
catch (InterruptedException e)
e.printStackTrace();
count++;
br.close();
private static void clearTask()
// 清理,同时找出出现字符最大的数
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext())
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue)
targetValue = value;
targetKey = key;
System.out.println("数量最多的年龄为:" + targetKey + "数量为:" + targetValue);
System.exit(-1);
/**
* 使用linkedBlockQueue
*
* @throws FileNotFoundException
* @throws UnsupportedEncodingException
*/
private static void startConsumer() throws FileNotFoundException, UnsupportedEncodingException
//如果共用一个队列,那么线程不宜过多,容易出现抢占现象
System.out.println("开始消费...");
for (int i = 0; i < threadNums; i++)
final int index = i;
// 每一个线程负责一个queue,这样不会出现线程抢占队列的情况。
new Thread(() ->
while (consumerRunning)
startConsumer = true;
try
String str = blockQueueLists.get(index).take();
countNum(str);
catch (InterruptedException e)
e.printStackTrace();
).start();
// 按照arr的大小,运用多线程分割字符串
private static void countNum(String str)
int[] arr = new int[2];
arr[1] = str.length() / 3;
// System.out.println("分割的字符串为start位置为:" + arr[0] + ",end位置为:" + arr[1]);
for (int i = 0; i < 3; i++)
final String innerStr = SplitData.splitStr(str, arr);
// System.out.println("分割的字符串为start位置为:" + arr[0] + ",end位置为:" + arr[1]);
new Thread(() ->
String[] strArray = innerStr.split(",");
for (String s : strArray)
countMap.computeIfAbsent(s, s1 -> new AtomicInteger(0)).getAndIncrement();
).start();
/**
* 后台线程去消费map里数据写入到各个文件里, 如果不消费,那么会将内存程爆
*/
private static void startConsumer0() throws FileNotFoundException, UnsupportedEncodingException
for (int i = start; i <= end; i++)
final int index = i;
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(dir + "\\\\" + i + ".dat", false), "utf-8"));
new Thread(() ->
int miss = 0;
int countIndex = 0;
while (true)
// 每隔100万打印一次
int count = countMap.get(index).get();
if (count > 1000000 * countIndex)
System.out.println(index + "岁年龄的个数为:" + countMap.get(index).get());
countIndex += 1;
if (miss > 1000)
// 终止线程
try
Thread.currentThread().interrupt();
bw.close();
catch (IOException e)
if (Thread.currentThread().isInterrupted())
break;
Vector<String> lines = valueMap.computeIfAbsent(index, vector -> new Vector<>());
// 写入到文件里
try
if (CollectionUtil.isEmpty(lines))
miss++;
Thread.sleep(1000);
else
// 100个一批
if (lines.size() < 1000)
Thread.sleep(1000);
continue;
// 1000个的时候开始处理
ReentrantLock lock = lockMap.computeIfAbsent(index, lockIndex -> new ReentrantLock());
lock.lock();
try
Iterator<String> iterator = lines.iterator();
StringBuilder sb = new StringBuilder();
while (iterator.hasNext())
sb.append(iterator.next());
countMap.get(index).addAndGet(1);
try
bw.write(sb.toString());
bw.flush();
catch (IOException e)
e.printStackTrace();
// 清除掉vector
valueMap.put(index, new Vector<>());
finally
lock.unlock();
catch (InterruptedException e)
).start();
测试结果
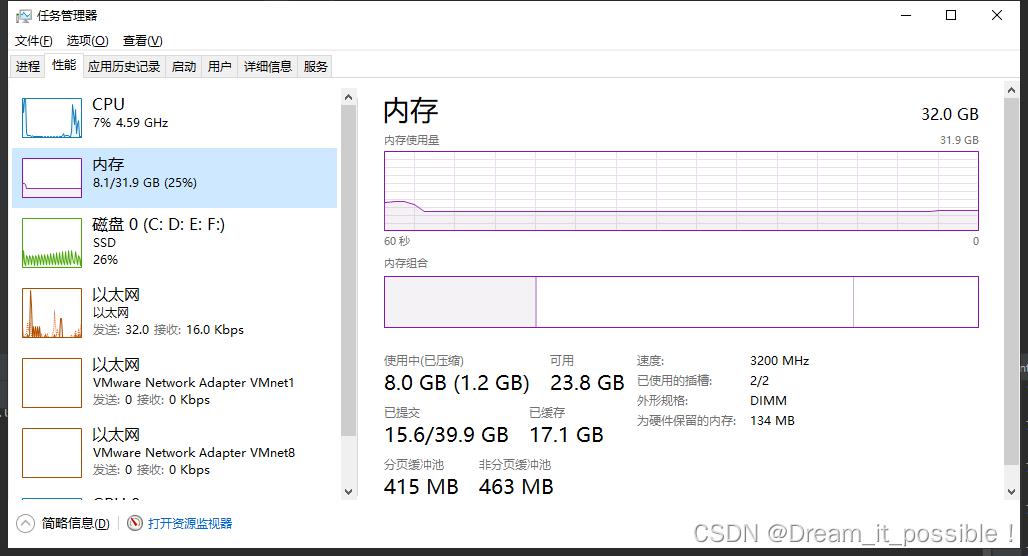
内存和CPU初始占用大小:
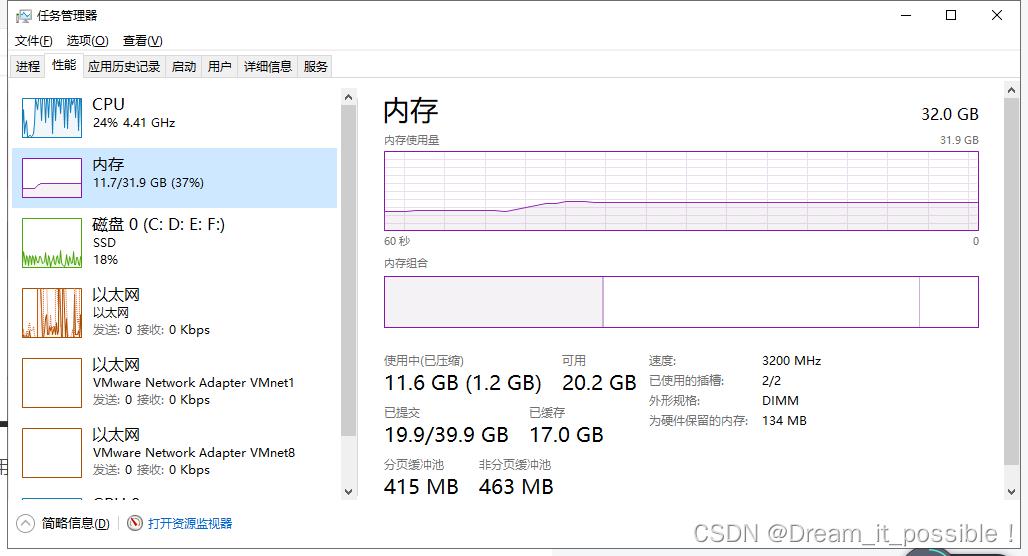
启动后,运行时稳定在11.7,CPU稳定利用在90%以上。
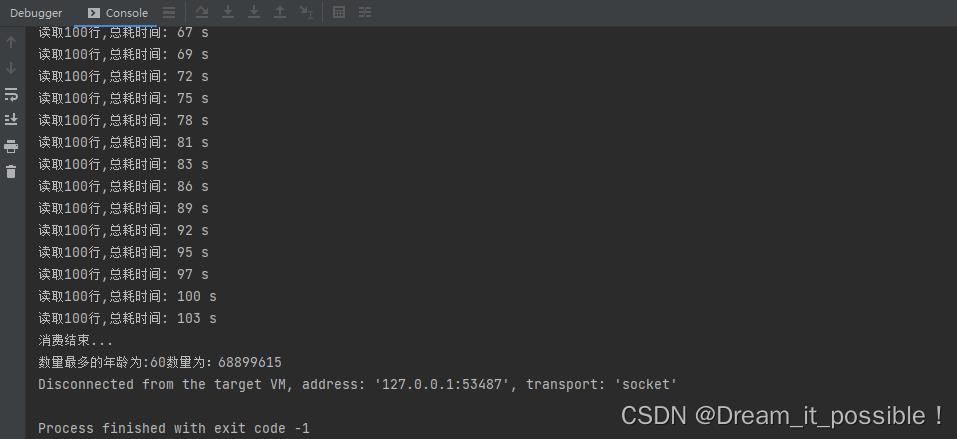
总耗时由180S缩减到103S,效率提升75%,得到的结果也与单线程处理的一致!
遇到的问题
如果在运行了的时候,发现GC突然罢工了,开始不工作了,有可能是JVM的堆中存在的垃圾太多,没回收导致内存的突增。

解决方法: 在读取一定数量后,可以让主线程暂停几秒,手动调用GC。
提示: 本demo的线程创建都是手动创建的,实际开发中使用的是线程池 !~
以上是关于如何用Golang处理每分钟100万个请求的主要内容,如果未能解决你的问题,请参考以下文章