实例化相关
对象的实例化过程如下所示:
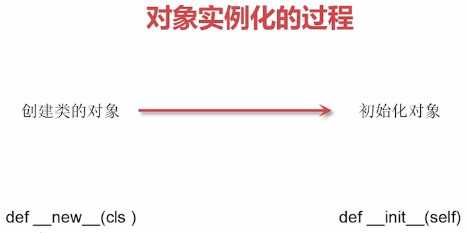
示例:
class Programer():
def __new__(cls,*args,**kwargs):
print('call __new__ method')
print(args)
return super(Programer,cls).__new__(cls)
def __init__(self,name,age):
print('call __init__ method')
self.name = name
self.age = age
if __name__ == '__main__':
programer = Programer('Albert',25)
print(programer.__dict__)运行结果:
call __new__ method
('Albert', 25)
call __init__ method
{'name': 'Albert', 'age': 25}在这个过程中:
__new__(cls[, ...])__new__是在一个对象实例化的时候所调用的第一个方法- 它的第一个参数是这个类,其他的参数是用来直接传递给
__init__方法 __new__决定是否要使用该__init__方法,因为__new__可以调用其他类的构造方法或者直接返回别的实例对象来作为本类的实例,如果__new__没有返回实例对象,则__init__不会被调用__new__主要是用于继承一个不可变的类型比如一个tuple或者string
__init__(self[, ...])- 构造器,当一个实例被创建的时候调用的初始化方法
运算相关
- 比较操作符
__lt__(self, other)定义小于号的行为:x < y调用x.__lt__(y)
__le__(self, other)定义小于等于号的行为:x <= y调用x.__le__(y)__eq__(self, other)定义等于号的行为:x == y调用x.__eq__(y)__ne__(self, other)定义不等号的行为:x != y调用x.__ne__(y)__gt__(self, other)定义大于号的行为:x > y调用x.__gt__(y)__ge__(self, other)定义大于等于号的行为:x >= y调用x.__ge__(y)
- 算数运算符
__add__(self, other)定义加法的行为:+__sub__(self, other)定义减法的行为:-__mul__(self, other)定义乘法的行为:*
__truediv__(self, other)定义真除法的行为:/__floordiv__(self, other)定义整数除法的行为://__mod__(self, other)定义取模算法的行为:%__divmod__(self, other)定义当被divmod()调用时的行为__pow__(self, other[, modulo])定义当被power()调用或**运算时的行为__lshift__(self, other)定义按位左移位的行为:<<
__rshift__(self, other)定义按位右移位的行为:>>
__and__(self, other)定义按位与操作的行为:&
__xor__(self, other)定义按位异或操作的行为:^
__or__(self, other)定义按位或操作的行为:\\|
示例:
class Programer(object):
def __init__(self,name,age):
self.name = name
if isinstance(age,int):
self.age = age
else:
raise Exception('age must be int')
def __eq__(self,other):
if isinstance(other,Programer): # 首先判断是否Programer对象
if self.age == other.age:
return True
else:
return False
else:
raise Exception('The type of object must be Programer')
def __add__(self,other):
if isinstance(other,Programer):
return self.age + other.age
else:
raise Exception('The type of object must be Programer')
if __name__ == '__main__':
p1 = Programer('Albert',25)
p2 = Programer('Bill',30)
print(p1==p2)
print(p1+p2)运行结果:
False
55展现相关
__str__- 把对象转换成适合人看的字符串
__repr__- 把对象转换成适合机器看的字符串,即可以使用
eval函数运行
- 把对象转换成适合机器看的字符串,即可以使用
__dir__(self)- 定义当
dir()被调用时的行为
- 定义当
示例:
class Programer(object):
def __init__(self,name,age):
self.name = name
if isinstance(age,int):
self.age = age
else:
raise Exception('age must be int')
def __str__(self):
return '%s is %s years old'%(self.name,self.age)
def __dir__(self):
return self.__dict__.keys()
if __name__ == '__main__':
p = Programer('Albert',25)
print(p)
print(dir(p))运行结果:
Albert is 25 years old
['age', 'name']属性控制相关
设置对象属性
__setattr__(self, name, value)
获取对象属性
__getattr__(self, name)- 当查询不到时才会调用
__getattribute__(self, name)- 每次访问时一定会被调到
删除对象属性
__del__(self)
限制添加属性
__slots__由于
Python是动态语言,任何实例在运行期都可以动态地添加属性。如果要限制添加的属性,例如,
Student类只允许添加name、gender和score这3个属性,就可以利用Python的一个特殊的__slots__来实现。顾名思义,
__slots__是指一个类允许的属性列表:
示例1
class Programer(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __getattribute__(self,name):
# return getattr(self,name) # 会产生无限递归
# 调用父类的getattribute方法,不会产生无限递归
return super(Programer,self).__getattribute__(name)
def __setattr__(self,name,value):
# setattr(self,name,value) # 会产生无限递归
self.__dict__[name] = value
if __name__ == '__main__':
p = Programer('Albert',25)
print(p.name)运行结果:
Albert示例2
class Student(object):
__slots__ = ('name', 'gender', 'score')
def __init__(self, name, gender, score):
self.name = name
self.gender = gender
self.score = score现在,对实例进行操作:
>>> s = Student('Bob', 'male', 59)
>>> s.name = 'Tim' # OK
>>> s.score = 99 # OK
>>> s.grade = 'A'
Traceback (most recent call last):
...
AttributeError: 'Student' object has no attribute 'grade'__slots__的目的是限制当前类所能拥有的属性,如果不需要添加任意动态的属性,使用__slots__也能节省内存。
示例3
假设Person类通过__slots__定义了name和gender,请在派生类Student中通过__slots__继续添加score的定义,使Student类可以实现name、gender和score3个属性。
Student类的__slots__只需要包含Person类不包含的score属性即可。
参考代码:
class Person(object):
__slots__ = ('name', 'gender')
def __init__(self, name, gender):
self.name = name
self.gender = gender
class Student(Person):
__slots__ = ('score',)
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
s = Student('Bob', 'male', 59)
s.name = 'Tim'
s.score = 99
print s.score容器相关
len__(self)返回容器的长度,可变和不可变类型都需要实现。
__getitem__(self, key)定义对容器中某一项使用
self[key]的方式进行读取操作时的行为。这也是可变和不可变容器类型都需要实现的一个方法。它应该在键的类型错误式产生 TypeError 异常,同时在没有与键值相匹配的内容时产生KeyError异常。__setitem__(self, key)定义对容器中某一项使用
self[key]的方式进行赋值操作时的行为。它是可变容器类型必须实现的一个方法,同样应该在合适的时候产生KeyError和TypeError异常。__iter__(self, key)它应该返回当前容器的一个迭代器。迭代器以一连串内容的形式返回,最常见的是使用
iter()函数调用,以及在类似for x in container:的循环中被调用。迭代器是他们自己的对象,需要定义__iter__方法并在其中返回自己。__reversed__(self)定义了对容器使用
reversed()内建函数时的行为。它应该返回一个反转之后的序列。当你的序列类是有序时,类似列表和元组,再实现这个方法,__contains__(self, item)__contains__定义了使用 in 和 not in 进行成员测试时类的行为。你可能好奇为什么这个方法不是序列协议的一部分,原因是,如果 contains 没有定义,Python就会迭代整个序列,如果找到了需要的一项就返回 True 。__missing__(self ,key)__missing__在字典的子类中使用,它定义了当试图访问一个字典中不存在的键时的行为(目前为止是指字典的实例,例如我有一个字典d,“george”不是字典中的一个键,当试图访问d[“george’]时就会调用d.__missing__(“george”) )。
示例:
class FunctionalList:
'''一个列表的封装类,实现了一些额外的函数式
方法,例如head, tail, init, last, drop和take。'''
def __init__(self, values=None):
if values is None:
self.values = []
else:
self.values = values
def __len__(self):
return len(self.values)
def __getitem__(self, key):
# 如果键的类型或值不合法,列表会返回异常
return self.values[key]
def __setitem__(self, key, value):
self.values[key] = value
def __delitem__(self, key):
del self.values[key]
def __iter__(self):
return iter(self.values)
def __reversed__(self):
return reversed(self.values)
def append(self, value):
self.values.append(value)
def head(self):
# 取得第一个元素
return self.values[0]
def tail(self):
# 取得除第一个元素外的所有元素
return self.valuse[1:]
def init(self):
# 取得除最后一个元素外的所有元素
return self.values[:-1]
def last(self):
# 取得最后一个元素
return self.values[-1]
def drop(self, n):
# 取得除前n个元素外的所有元素
return self.values[n:]
def take(self, n):
# 取得前n个元素
return self.values[:n]就是这些,一个(微不足道的)有用的例子,向你展示了如何实现自己的序列。当然啦,自定义序列有更大的用处,而且绝大部分都在标准库中实现了(
Python是自带电池的,记得吗?),像Counter,OrderedDict和NamedTuple。
上下文相关
在Python 2.5中引入了一个全新的关键词,随之而来的是一种新的代码复用方法—— with 声明。上下文管理的概念在Python中并不是全新引入的(之前它作为标准库的一部分实现),直到PEP 343被接受,它才成为一种一级的语言结构。可能你已经见过这种写法了:
with open('foo.txt') as bar:
# 使用bar进行某些操作当对象使用 with 声明创建时,上下文管理器允许类做一些设置和清理工作。上下文管理器的行为由下面两个魔法方法所定义:
__enter__(self)定义使用
with 声明创建的语句块最开始上下文管理器应该做些什么。注意__enter__的返回值会赋给with 声明的目标,也就是as之后的东西。__exit__(self, exception_type, exception_value, traceback)定义当
with 声明语句块执行完毕(或终止)时上下文管理器的行为。它可以用来处理异常,进行清理,或者做其他应该在语句块结束之后立刻执行的工作。如果语句块顺利执行,exception_type,exception_value和traceback会是None。否则,你可以选择处理这个异常或者让用户来处理。如果你想处理异常,确保__exit__在完成工作之后返回True。如果你不想处理异常,那就让它发生吧。
对一些具有良好定义的且通用的设置和清理行为的类,__enter__ 和 __exit__ 会显得特别有用。你也可以使用这几个方法来创建通用的上下文管理器,用来包装其他对象。下面是一个例子:
class Closer:
'''一个上下文管理器,可以在with语句中
使用close()自动关闭对象'''
def __init__(self, obj):
self.obj = obj
def __enter__(self, obj):
return self.obj # 绑定到目标
def __exit__(self, exception_type, exception_value, traceback):
try:
self.obj.close()
except AttributeError: # obj不是可关闭的
print 'Not closable.'
return True # 成功地处理了异常这是一个 Closer 在实际使用中的例子,使用一个FTP连接来演示(一个可关闭的socket):
>>> from magicmethods import Closer
>>> from ftplib import FTP
>>> with Closer(FTP('ftp.somesite.com')) as conn:
... conn.dir()
...
# 为了简单,省略了某些输出
>>> conn.dir()
# 很长的 AttributeError 信息,不能使用一个已关闭的连接
>>> with Closer(int(5)) as i:
... i += 1
...
Not closable.
>>> i
6看到我们的包装器是如何同时优雅地处理正确和不正确的调用了吗?这就是上下文管理器和魔法方法的力量。Python标准库包含一个 contextlib 模块,里面有一个上下文管理器 contextlib.closing() 基本上和我们的包装器完成的是同样的事情(但是没有包含任何当对象没有close()方法时的处理)。
复制相关
有些时候,特别是处理可变对象时,你可能想拷贝一个对象,改变这个对象而不影响原有的对象。这时就需要用到Python的 copy 模块了。然而(幸运的是),Python模块并不具有感知能力, 因此我们不用担心某天基于Linux的机器人崛起。但是我们的确需要告诉Python如何有效率地拷贝对象。
__copy__(self)定义对类的实例使用
copy.copy()时的行为。copy.copy()返回一个对象的浅拷贝,这意味着拷贝出的实例是全新的,然而里面的数据全都是引用的。也就是说,对象本身是拷贝的,但是它的数据还是引用的(所以浅拷贝中的数据更改会影响原对象)。__deepcopy__(self, memodict=)定义对类的实例使用
copy.deepcopy()时的行为。copy.deepcopy()返回一个对象的深拷贝,这个对象和它的数据全都被拷贝了一份。memodict是一个先前拷贝对象的缓存,它优化了拷贝过程,而且可以防止拷贝递归数据结构时产生无限递归。当你想深拷贝一个单独的属性时,在那个属性上调用copy.deepcopy(),使用memodict作为第一个参数。
这些魔法方法有什么用武之地呢?像往常一样,当你需要比默认行为更加精确的控制时。例如,如果你想拷贝一个对象,其中存储了一个字典作为缓存(可能会很大),拷贝缓存可能是没有意义的。如果这个缓存可以在内存中被不同实例共享,那么它就应该被共享。
持久化相关
Pickle不仅仅可以用于内建类型,任何遵守pickle协议的类都可以被pickle。Pickle协议有四个可选方法,可以让类自定义它们的行为(这和C语言扩展略有不同,那不在我们的讨论范围之内)。
__getinitargs__(self)如果你想让你的类在反
pickle时调用__init__,你可以定义__getinitargs__(self),它会返回一个参数元组,这个元组会传递给__init__。注意,这个方法只能用于旧式类。__getnewargs__(self)对新式类来说,你可以通过这个方法改变类在反pickle时传递给
__new__的参数。这个方法应该返回一个参数元组。__getstate__(self)你可以自定义对象被
pickle时被存储的状态,而不使用对象的__dict__属性。 这个状态在对象被反pickle时会被__setstate__使用。__setstate__(self)当一个对象被反
pickle时,如果定义了__setstate__,对象的状态会传递给这个魔法方法,而不是直接应用到对象的__dict__属性。这个魔法方法和__getstate__相互依存:当这两个方法都被定义时,你可以在Pickle时使用任何方法保存对象的任何状态。__reduce__(self)当定义扩展类型时(也就是使用
Python的C语言API实现的类型),如果你想pickle它们,你必须告诉Python如何pickle它们。__reduce__被定义之后,当对象被Pickle时就会被调用。它要么返回一个代表全局名称的字符串,Pyhton会查找它并pickle,要么返回一个元组。这个元组包含2到5个元素,其中包括:一个可调用的对象,用于重建对象时调用;一个参数元素,供那个可调用对象使用;被传递给__setstate__的状态(可选);一个产生被pickle的列表元素的迭代器(可选);一个产生被pickle的字典元素的迭代器(可选);__reduce_ex__(self)__reduce_ex__的存在是为了兼容性。如果它被定义,在pickle时__reduce_ex__会代替__reduce__被调用。__reduce__也可以被定义,用于不支持__reduce_ex__的旧版pickle的API调用。
示例
我们的例子是 Slate ,它会记住它的值曾经是什么,以及那些值是什么时候赋给它的。然而 每次被pickle时它都会变成空白,因为当前的值不会被存储:
import time
class Slate:
'''存储一个字符串和一个变更日志的类
每次被pickle都会忘记它当前的值'''
def __init__(self, value):
self.value = value
self.last_change = time.asctime()
self.history = {}
def change(self, new_value):
# 改变当前值,将上一个值记录到历史
self.history[self.last_change] = self.value
self.value = new_value)
self.last_change = time.asctime()
def print_change(self):
print 'Changelog for Slate object:'
for k,v in self.history.items():
print '%s\\t %s' % (k,v)
def __getstate__(self):
# 故意不返回self.value或self.last_change
# 我们想在反pickle时得到一个空白的slate
return self.history
def __setstate__(self):
# 使self.history = slate,last_change
# 和value为未定义
self.history = state
self.value, self.last_change = None, None