sql数据库中出现重复行数据,如何删除这些重复记录?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql数据库中出现重复行数据,如何删除这些重复记录?相关的知识,希望对你有一定的参考价值。
我现在有一个表 有一些记录行是一模一样的 id和其他字段都是一样 哪何删除一个 因为id都一样,我现在很难删除
示例
假设存在一个产品信息表Products,其表结构如下:
CREATE TABLE Products (ProductID int,
ProductName nvarchar (40),
Unit char(2),
UnitPrice money
)
表中数据如图:
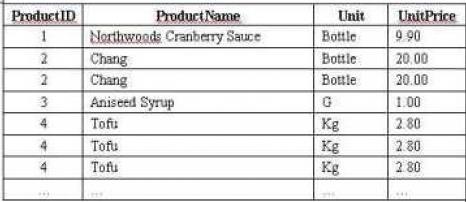
图中可以看出,产品Chang和Tofu的记录在产品信息表中存在重复。现在要删除这些重复的记录,只保留其中的一条。步骤如下:
第一步——建立一张具有相同结构的临时表
CREATE TABLE Products_temp (ProductID int,
ProductName nvarchar (40),
Unit char(2),
UnitPrice money
)
第二步——为该表加上索引,并使其忽略重复的值
方法是在企业管理器中找到上面建立的临时表Products _temp,单击鼠标右键,选择所有任务,选择管理索引,选择新建。如图2所示。
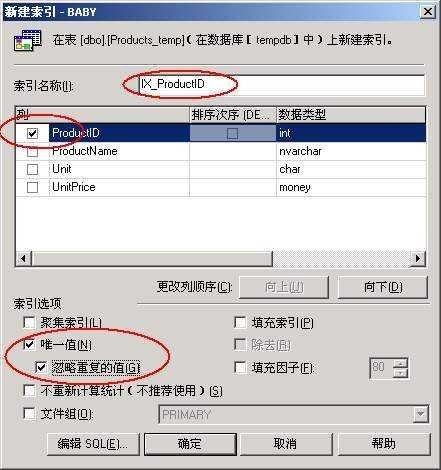
按照图2中圈出来的地方设置索引选项
第三步——拷贝产品信息到临时表
insert into Products_temp Select * from Products此时SQL Server会返回如下提示:
服务器: 消息 3604,级别 16,状态 1,行 1
已忽略重复的键。
它表明在产品信息临时表Products_temp中不会有重复的行出现。
第四步——将新的数据导入原表
将原产品信息表Products清空,并将临时表Products_temp中数据导入,最后删除临时表Products_temp。
这样就完成了对表中重复记录的删除。无论表有多大,它的执行速度都是相当快的,而且因为几乎不用写语句,所以它也是很安全的
参考技术A一般情况下,数据库去重复有以下那么三种方法:
第一种:
两条记录或者多条记录的每一个字段值完全相同,这种情况去重复最简单,用关键字distinct就可以去掉。例:
SELECT DISTINCT * FROM TABLE第二种:
两条记录之间之后只有部分字段的值是有重复的,但是表存在主键或者唯一性ID。如果是这种情况的话用DISTINCT是过滤不了的,这就要用到主键id的唯一性特点及group by分组。例:
SELECT * FROM TABLE WHERE ID IN (SELECT MAX(ID) FROM TABLE GROUP BY [去除重复的字段名列表,....])
第三种:
两条记录之间之后只有部分字段的值是有重复的,但是表不存在主键或者唯一性ID。这种情况可以使用临时表,讲数据复制到临时表并添加一个自增长的ID,在删除重复数据之后再删除临时表。例:
//创建临时表,并将数据写入到临时表SELECT IDENTITY(INT1,1) AS ID,* INTO NEWTABLE(临时表) FROM TABLE
//查询不重复的数据
SELECT * FROM NEWTABLE WHERE ID IN (SELECT MAX(ID) FROM NEWTABLE GROUP BY [去除重复的字段名列表,....])
//删除临时表
DROP TABLE NEWTABLE
参考技术B 怕用别的方法删除出错的话,可以用 去重查询,放到另一张表中,删除后再放回去啊!
select distinct * into A from B 去重存另一张表
delete B-- 删除B中数据
--放回数据
insert into B
select * from A
注意:分开执行!用go分开的话,有可能删除数据,但因为语句没结果而未完全删除。 参考技术C delete from TABLE_name t1
where t1.rowid >
(select min(rowid) from TABLE_name t2
where t1.name = t2.name
group by name
having count(name) > 1); 肯定没问题的哈本回答被提问者采纳
一条SQL删除重复记录,重复的只保留一条
情景:
我们的数据库中可能会存在很多因各种原因而重复的记录,我们需要对这些重复的记录进行删除,每组组重复的记录只保留一条就行
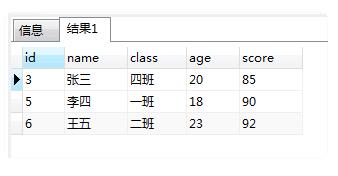
例如我们有这么个表:两个框框都是有重复记录的,红框和绿框都只需要留下一条,其他的都干掉。
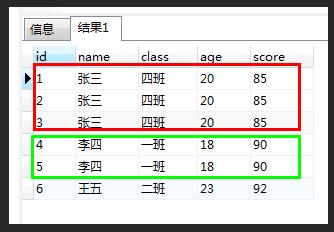
前提:
1:每天记录都要有一个唯一id
2:每组重复的记录要有字段能进行分组,例如上面我们按name、class、age、score相同的就是一组。
数据宝贵,请先备份!!!
数据宝贵,请先备份!!!
数据宝贵,请先备份!!!
放上整条SQL:
DELETE FROM "t_hw_test_del" t3 WHERE 1 = 1 AND EXISTS ( SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL AND t1."id" = t3."id" )
按步分析:
1:找到我们需要的记录,因为我们可能只是要处理某天的记录,所以要先筛选一下,我这里用1=1来代替
SELECT * FROM "t_hw_test_del" WHERE 1 = 1
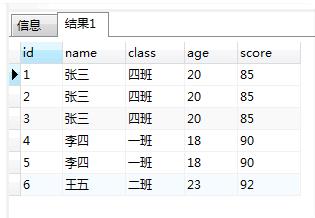
SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score"
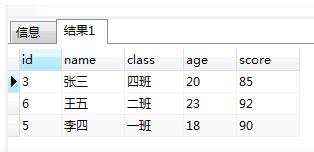
3:用我们找到的需要处理的记录和要保留的记录关联起来, 用分组字段和唯一id关联,左联
SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score"
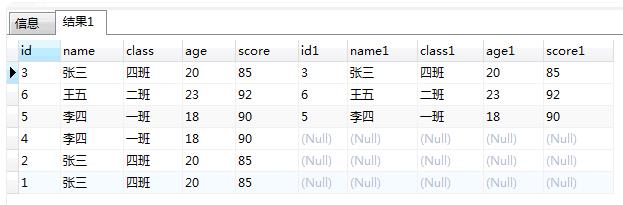
4:右表为null的记录,对应的左表记录就是我们要删掉的,加个条件右表为null
SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL
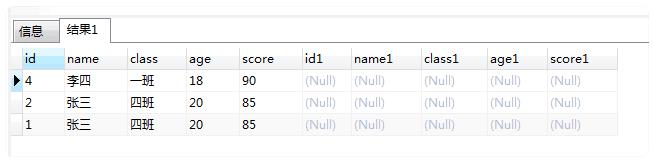
5: 用我们原来的记录id在我们不需要的记录里面找,如果这条记录在我们不需要的记录集里,那这条记录就可以删除
DELETE FROM "t_hw_test_del" t3 WHERE 1 = 1 AND EXISTS ( SELECT * FROM ( SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 )t1 LEFT JOIN ( SELECT "MAX"("id") as "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1 GROUP BY "name","class","age","score" ) t2 ON t1."id" = t2."id" AND t1."name" = t2."name" AND t1."class" = t2."class" AND t1."age" = t2."age" AND t1."score" = t2."score" WHERE t2."id" is NULL AND t1."id" = t3."id" )
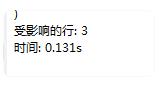
6: 检查一下结果符不符合我们的要求
SELECT "id","name","class","age","score" FROM "t_hw_test_del" WHERE 1 = 1
以上是关于sql数据库中出现重复行数据,如何删除这些重复记录?的主要内容,如果未能解决你的问题,请参考以下文章