Python爬虫进阶(Scrapy框架爬虫)
Posted HaoYu'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫进阶(Scrapy框架爬虫)相关的知识,希望对你有一定的参考价值。
准备工作:
配置环境问题什么的我昨天已经写了,那么今天直接安装三个库
首先第一步:
(我们要用到scrapy框架,在python里调用windows 命令,使用mongodb存储爬到的数据 )
进入DOS python/Script>路径下 输入命令:
python/Script> pip install pypiwin32
python/Script> pip install scrapy
python/Script> pip install pymongo
三个库下载完成后,打开DOS 输入命令:
(将指令路径转到你需要创建爬虫项目文件的目录。例如:e:)
e:\\> scrapy startproject projectFileName ##创建一个scrapy框架的爬虫项目文件 ,名字为projectName
(运行下一步之前需要将DOS的指令路径cd 到上一步操作创建的项目文件)
scrapy genspider projectName Http:\\\\www.baidu.com ##创建一个爬虫项目,这里后面网址随便填后面可以修改,但是这一项是必填项
以上操作都完成后,打开Pycharm 打开我们事先用DOS创好的爬虫项目文件projectFileName
开始编译:
(我这里以爬贴吧的名字和类以及链接并最后自动存入mongodb为例)
以下为projectName.py的源代码
#-*- coding: utf-8 -*-
import scrapy
from TieBa.items import TiebaItem ##引用items里面的Tiebaltem,方便后面存储数据
class BaidutiebaSpider(scrapy.Spider):
name = \'baidutieba\'
def start_requests(self): ##定义一个start_requests方法
header = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0\'} ##昨天已经解释了,模仿浏览器登录
yield scrapy.Request(url=\'http://tieba.baidu.com/f/index/forumclass\', headers=header, meta={\'headers\': header}, callback=self.parse_class) ##向目标页面发送请求,并用字典把headers存储起来,callback=跳转的下一个方法,self可以理解为c#里面的this
def parse_class(self, response): ##这里的response是上个Request获取的目标网页的信息
class_1s = response.xpath("//div[@class=\'clearfix\']/div[@class=\'class-item\']") ##这里我们直接用xpath获取需要的属性
for class_1 in class_1s:
class_1_name = class_1.xpath("a/text()").extract()[0] ##extract()提取信息,此方法返回值为一个list数组,虽然我们这里只有一个值但是也得取下标
class_2s = class_1.xpath("ul/li")
for class_2 in class_2s:
class_2_name = class_2.xpath("a/text()").extract()[0]
class_2_url = \'http://tieba.baidu.com\' + class_2.xpath("a/@href").extract()[0] + \'&pn=\' ##给每个子网页加上前缀和页数的后缀
for page in range(30):
yield scrapy.Request(url=class_2_url + str(page + 1), headers=response.meta[\'headers\'], meta={\'headers\': response.meta[\'headers\'], \'class_1_name\': class_1_name, \'class_2_name\': class_2_name}, callback=self.parse) ##与上一个方法类似,一样用字典储存一部分信息供下面使用
def parse(self, response):
tiebas = response.xpath("//div[@id=\'ba_list\']/div")
for tieba in tiebas:
tieba_name = tieba.xpath("a/div/p[@class=\'ba_name\']/text()").extract()[0]
tieba_url = \'http://tieba.baidu.com\' + tieba.xpath("a/@href").extract()[0]
item = TiebaItem(class_1=response.meta[\'class_1_name\'], class_2=response.meta[\'class_2_name\'], name=tieba_name, url=tieba_url)
yield item ##提交item
以下为items.py的源代码
import scrapy
class TiebaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
class_1 = scrapy.Field() ##获取projectName.py里面传的字典属性值,以下参数同理
class_2 = scrapy.Field()
name = scrapy.Field()
url = scrapy.Field()
以下为pipelines.py的源代码
import pymongo ##因为要使用mongodb所以要引用pymongo
class TiebaPipeline(object): ##此类名和setting里面的ITEM_PIPELINES下面的名字一致 ProjectFileName.pipelines.类名
def open_spider(self,spider): ##写一个open_apider开始爬虫的方法
self.client = pymongo.MongoClient(\'mongodb://localhost:27017\') ##连接mongodb,此处pymongo.MongoClient(\'mongodb://数据库连接\')
def close_spider(self,spider):
self.client.close() ##写入完记得关闭
def process_item(self, item, spider):
self.client[\'TieBa\'][\'datas\'].insert(dict(item)) ##往TieBa数据库里的datas表插入从projectName.py里传过来的itme(字典化)的值
以下为settings.py需要修改的部分代码
ROBOTSTXT_OBEY = False ##不遵从robots.txt里的Robot协议
ITEM_PIPELINES = { ##激活项目管道组件
\'TieBa.pipelines.TiebaPipeline\': 300
}
最后写一个启动start.py来运行scrapy框架下写的projectName.py
import os
os.system(\'scrapy crawl baidutieba\')
到这里,此次爬虫的编码就结束了,打开mongodb就能看到我们爬到的数据了
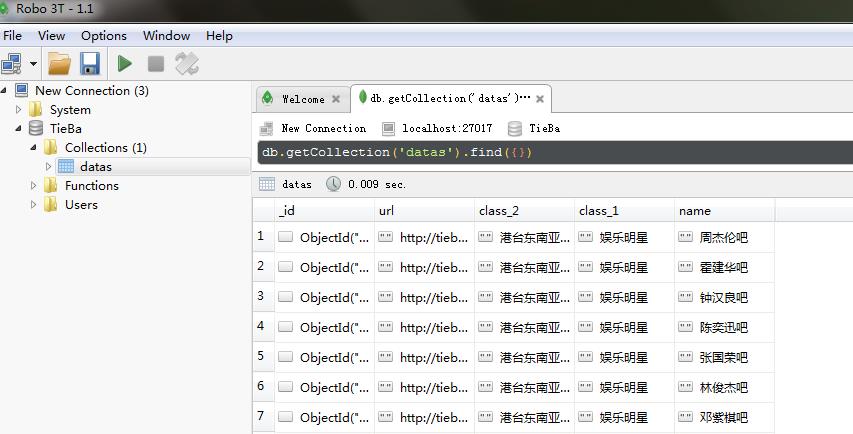
若有改进方案,问题 欢迎留言讨论
以上是关于Python爬虫进阶(Scrapy框架爬虫)的主要内容,如果未能解决你的问题,请参考以下文章