每日学习记录20230321_Bert
Posted Molesular Blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日学习记录20230321_Bert相关的知识,希望对你有一定的参考价值。
20230321:Bert
-
Bert
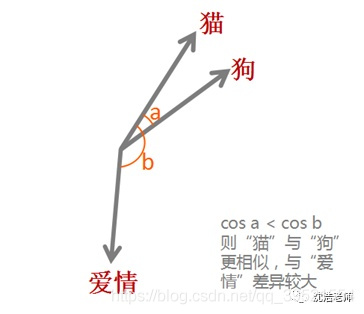
词嵌入(word embedding): 词嵌入是词的表示. 是一种词的类型表示,具有相似意义的词具有相似的表示,是将词汇映射到实数向量的方法总称。之所以希望把每个单词都变成一个向量,目的还是为了方便计算,比如“猫”,“狗”,“爱情”三个词。对于我们人而言,我们可以知道“猫”和“狗”表示的都是动物,而“爱情”是表示的一种情感,但是对于机器而言,这三个词都是用0,1表示成二进制的字符串而已,无法对其进行计算。而通过词嵌入这种方式将单词转变为词向量,机器便可对单词进行计算,通过计算不同词向量之间夹角余弦值cosine而得出单词之间的相似性。
此外,词嵌入还可以做类比,比如:v(“国王”)-v(“男人”)+v(“女人”)≈v(“女王”),v(“中国”)+v(“首都”)≈v(“北京”),当然还可以进行算法推理。有了
这些运算,机器也可以像人一样“理解”词汇的意思了。那么如何进行词嵌入呢?目前主要有三种算法:
Embedding Layer
由于缺乏更好的名称,Embedding Layer是与特定自然语言处理上的神经网络模型联合学习的单词嵌入。该嵌入方法将清理好的文本中的单词进行one hot编码(热编码),向量空间的大小或维度被指定为模型的一部分,例如50、100或300维。向量以小的随机数进行初始化。Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。
被编码过的词映射成词向量,如果使用多层感知器模型MLP,则在将词向量输入到模型之前被级联。如果使用循环神经网络RNN,则可以将每个单词作为序列中的一个输入。
这种学习嵌入层的方法需要大量的培训数据,可能很慢,但是可以学习训练出既针对特定文本数据又针对NLP的嵌入模型。
Word2Vec(Word to Vector)/ Doc2Vec(Document to Vector)
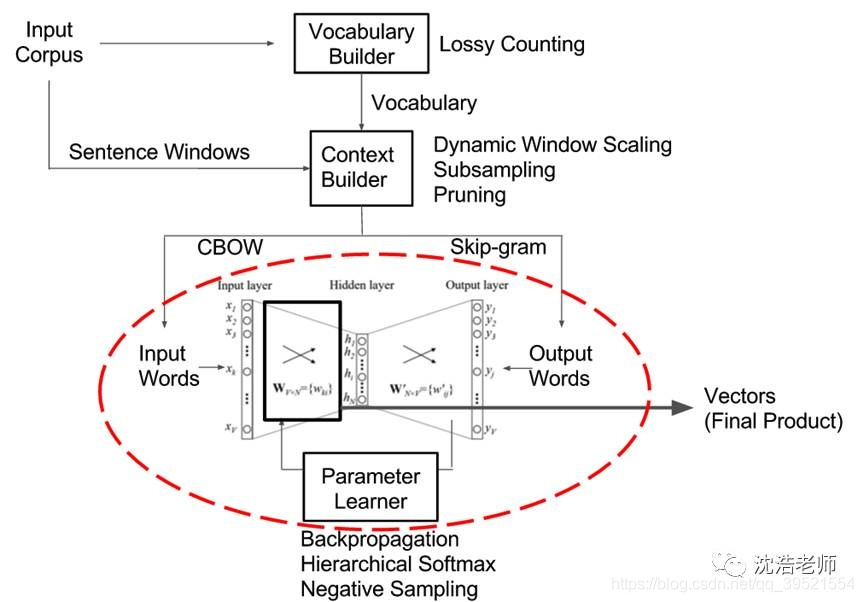
Word2Vec是由Tomas Mikolov 等人在《Efficient Estimation of Word Representation in Vector Space》一文中提出,是一种用于有效学习从文本语料库嵌入的独立词语的统计方法。其核心思想就是基于上下文,先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。Word2Vec 的网络主体是一种单隐层前馈神经网络,网络的输入和输出均为词向量,其主要训练的是图中的红圈部分。
这种算法有2种训练模式:- 通过上下文来预测当前词
- 通过当前词来预测上下文
GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
TestLink学习——每日例会记录
2017.11.14例会内容
小组进行了第一次线下讨论,针对一些资料和当前进度进行了讨论
1.组内人员分享了对TestLink的基本了解,同时分享了相关资料的出处。各小组将与TestLink有关的资料进行了汇总整理,用于后续了解和学习。
2.组内针对SPOC上的任务进行了细致的讨论。
3.工具使用手册小组主要是搜索了与TestLink的相关博客、视频教程等资料,了解了TestLink工具的基本情况。在电脑上部署了使用环境。确定好了工具使用手册的大体框架,后续将整合组内的资料,进行手册的撰写。
4.操作视频制作小组搜索了TestLink相关的使用教程视频,并根据视频教程进行了电脑环境的配置,后续将进一步在电脑上进行相关操作,熟悉了解TestLink,为视频制作做准备。
5.博客小组主要负责辅助工具使用手册小组和视频操作小组搜索相关资料,跟踪记录当日各组的进度,负责例会内容记录,以及博客的撰写。
以上是关于每日学习记录20230321_Bert的主要内容,如果未能解决你的问题,请参考以下文章