python基础篇13-模块
Posted lriwu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础篇13-模块相关的知识,希望对你有一定的参考价值。
模块
模块(modules)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
-
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块导入的方法:
存在以下两个.py文件,都位于F:\\\\code\\\\day18路径下:
calculate.py
1 print(\'ok\') 2 3 x = 3 4 def add(x,y): 5 return x+y 6 7 def sub(x,y): 8 return x-y
bin.py
1.import语句:
1 import sys 2 3 #搜索路径: 4 print(sys.path) #[\'F:\\\\code\\\\day18\', \'F:\\\\code\', \'E:\\\\soft_install\\\\python\\\\python3.5\\\\python35.zip\', \'E:\\\\soft_install\\\\python\\\\python3.5\\\\DLLs\', \'E:\\\\soft_install\\\\python\\\\python3.5\\\\lib\', \'E:\\\\soft_install\\\\python\\\\python3.5\', \'E:\\\\soft_install\\\\python\\\\python3.5\\\\lib\\\\site-packages\'] 5 6 import calculate #作用是解释器通过搜索路径找到calculate.py模块后,将calculate.py中所有代码解释完成后(即执行模块)赋值给calculate对象,此时calculate.py里的所有方法以及变量都要通过calculate对象来调用。 7 print(calculate.add(1,2)) #调用calculate.py模块的add方法 8 # 输出: 9 # ok 10 # 3 11 12 print(x) #报错:NameError: name \'x\' is not defined 13 print(calculate.x) #3
2.from....import....语句:
1 from calculate import add 也可以只导入模块的部分方法,则模块中的其它方法将无法调用 2 print(add(1,2)) #调用calculate.py模块的add方法 3 # 输出: 4 # ok 5 # 3 6 7 print(sub(1,2)) #报错,NameError: name \'sub\' is not defined
3.from....import* 语句:
1 from calculate import * 2 print(add(1,2)) #和1的区别是无需通过calculate.add()来调用函数 3 print(sub(1,2)) 4 print(x) 5 6 # 输出: 7 # ok 8 # 3 9 # -1 10 # 3
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
4.运行本质:
1 # import calculate 2 # from calculate import add
无论1还是2,首先通过sys.path找到calculate.py,然后执行calculate.py(全部执行),区别是1会将calculate这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
5.自定义方法名
1 from calculate import add as plus 2 3 add(1,2) #报错 4 plus(1,2) #这是需要通过plus来调用方法
模块导入流程:
1. 先从sys.modules里查看模块是否已经被导入
2. 模块如果没有被导入,就依据sys.path路径寻找模块
3. 如果在sys.path路径下找到模块就导入模块
4. 创建这个模块的命名空间,执行模块文件(.py文件),并把模块文件中的名字都放到该命名空间里。
包(package)
作用:如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突;
注意:每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字;调用包就是执行包下的__init__.py文件(即import PACKGE 即执行包下的__init__.py文件)
- 存在如下目录结构:
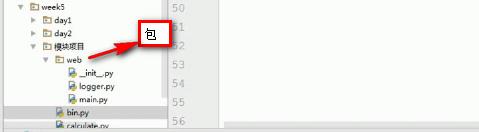
在bin.py模块中调用web下的logger模块:
1 from web import logger 2 logger.logger() #在bin.py模块中就可以实现调用web下logger模块中的方法了
- 存在如下目录结构:
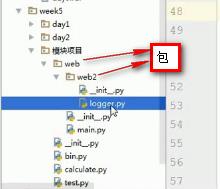
在bin.py模块中调用web下web2下的logger模块:
1 from web.web2 mport logger 2 logger.logger()
只调用logger下的某些方法:
1 from web.web2.logger import logger #调用logger模块下的logger方法 2 logger.logger()
- BASE_DIR引入:
存在如下目录结构:
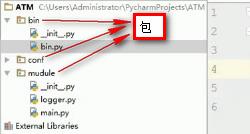
main.py:
1 #import logger #如果这样写,在bin.py中调用main方法时会报无法找到logger的错误,应该改成如下的方式 2 from module import logger 3 def main: 4 logger.logger()
logger.py
1 def logger: 2 print(\'logger\')
如果修改bin.py是程序的入口,在bin.py中如何调用main.py中的main函数?
bin.py
1 from module import main 2 main.main() #这句话类似于将main方法中的所有代码复制至该模块(bin.py)下
注意:bin.py在pycharm中可以正常执行,因为在pycharm中在sys.path中将包bin的父目录的路径也添加到搜索路径,所以在pycharm中可以搜索到module;但是再命令行下将报错(因为在bin.py模块下无法找到module包)。
解决:
__file__:获取程序的相对路径,如
print(__file__) #输出bin.py (在pycharm中打印显示时会将该相对路径转化为绝对路径,其他环境中还是相对路径)
print(os.path.abspath(__file__)) # C:\\\\Users\\\\Administrator\\\\PycharmProjects\\\\ATM\\\\bin (根据相对路径找到绝对路径)
BASE_DIR=(os.path.abspath(os.path.abspath(__file__))) #C:\\\\Users\\\\Administrator\\\\PycharmProjects\\\\ATM
优化后的bin.py的代码如下:将程序移植到任何环境下都能执行
1 import sys,os 2 BASE_DIR=(os.path.abspath(os.path.abspath(__file__))) 3 sys.path.append(BASE_DIR) 4 5 from module import main 6 7 main.main()
if __name__ ==\'__main__\':
如果我们是直接执行某个.py文件的时候,在该文件中”__name__ == \'__main__\'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__;这个功能还有一个用处:调试代码的时候,在”if __name__ == \'__main__\'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
例子:
存在以下目录结构:
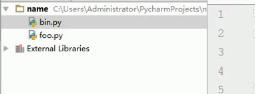
foo.py代码如下:功能模块
def hello:
print(\'hello\')
hello() #调试代码,单独执行foo.py时会执行hello()方法,外部调用foo模块时也会执行hello()方法
bin.py代码如下:调用模块
import foo
foo.hello()
输出:输出了两次hello
hello
hello
优化:
foo.py代码如下:
def hello:
print(\'hello\')
#print(__main__) 在该模块下执行输出的是__main__,则if __name__=\'__main__\'就为True,就会执行调试代码;在模块调用时结果为foo(即为模块名),则在模块调用时if __name__!=\'__main__\',则就不会执行调试代码
if __name__=\'__main__\':
hello() #调试代码,单独执行foo.py时会执行hello()方法,外部调用foo模块时将不会执行hello()方法
bin.py代码如下:调用模块
import foo
foo.hello()
输出:只输出一次hello
hello
time模块
1 import time 2 #print(help(time)) 查看帮助 3 4 print(time.time()) #1517193182.0534253 时间戳(s),unix诞生以来开始计算 5 time.sleep(3) #休眠3s 6 print(time.clock()) #7.551609587825597e-07 计算cpu执行时间(不包括上面的3s) 7 print(time.gmtime()) #结构化时间:time.struct_time(tm_year=2018, tm_mon=1, tm_mday=29, tm_hour=2, tm_min=36, tm_sec=5, tm_wday=0, tm_yday=29, tm_isdst=0) 即UTC(世界标准)时间,和北京时间差8h 8 print(time.localtime()) #本地时间:time.struct_time(tm_year=2018, tm_mon=1, tm_mday=29, tm_hour=10, tm_min=45, tm_sec=10, tm_wday=0, tm_yday=29, tm_isdst=0) 9 10 #print(time.strftime(format,p_tuple)) 将结构化时间以字符串时间形式输出 11 print(time.strftime("%Y-%m-%d %H:%M:%S" )) #字符串时间即自定义格式输出日期 2018-01-29 10:55:02 12 struct_time=time.localtime() 13 print(time.strftime("%Y-%m-%d %H:%M:%S",struct_time)) #将结构化时间以字符串时间输出:2018-01-29 10:58:51 14 15 #time.strptime(string,format) 将字符串时间以结构化时间输出 16 print(time.strptime("2018-01-29 10:58:51","%Y-%m-%d %H:%M:%S")) #time.struct_time(tm_year=2018, tm_mon=1, tm_mday=29, tm_hour=10, tm_min=58, tm_sec=51, tm_wday=0, tm_yday=29, tm_isdst=-1) 17 #取某个时间值: 18 a=time.strptime("2018-01-29 10:58:51","%Y-%m-%d %H:%M:%S") 19 print(a.tm_hour) #10 20 print(a.tm_mon) #1 21 22 #time.ctime(seconds) 23 print(time.ctime()) #取当前时间:Mon Jan 29 11:11:09 2018 24 print(time.ctime(234566)) #将给定的时间以看得懂的方式输出(unix诞生以来的时间开始计算) 25 26 #time.mktime(p_tuple) 27 a=time.localtime() 28 print(time.mktime(a)) #将本地时间转化为时间戳:1517195833.0
几种时间格式之间的转换
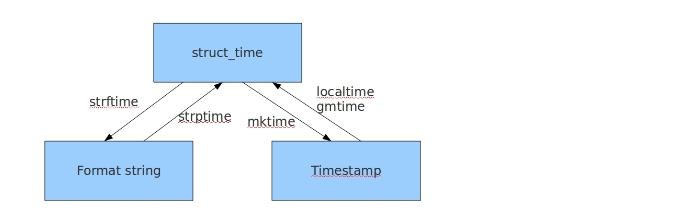
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 >>>time.strftime("%Y-%m-%d %X") \'2017-07-24 14:55:36\' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) \'2017-07-14\' #字符串时间-->结构化时间 #time.strptime(时间字符串,字符串对应格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
datatime模块
1 import datetime 2 print(datetime.datetime.now()) #2018-01-29 11:20:48.342246
random模块-随机数模块
1 import random 2 print(random.random()) #取0-1内的随机数 3 print(random.randint(1,8)) #1-8内的随机数,包括8 4 print(random.choice("hello")) #在给定的字符串选取随机数 5 print(random.choice([1,2,3,4,5])) #也可以放列表 6 print(random.sample([1,2,[3,4]],2)) #在序列中随机选2个,[2, [3, 4]] 7 print(random.randrange(1,10)) #取1-10的数,不包括10 8 9 10 #生成随机验证码 11 import random 12 checkcode = \'\' 13 for i in range(4): 14 current = random.randrange(0,4) 15 if current != i: 16 temp = chr(random.randint(65,90)) 17 else: 18 temp = random.randint(0,9) 19 checkcode += str(temp) 20 print checkcode
os模块-和操作系统交互的模块
提供对操作系统进行调用的接口。
r:以字符原意思输出。
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径; 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd ;os.chdir(r\'F:\\code\') # r:取消所有转义 3 os.curdir 返回当前目录: (\'.\') 4 os.pardir 获取当前目录的父目录字符串名:(\'..\') 5 os.makedirs(\'dirname1/dirname2\') 可生成多层递归目录;os.makedirs(r\'abc\\lriwu\\alen\') 6 os.removedirs(\'dirname1/dirname2\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 ;s.removedirs(r\'abc\\lriwu\\alen\') 7 os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat(\'path/filename\') 获取文件/目录信息 os.stat(\'path/filename\').st_size 获取文件大小,返回值是int类型 13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n" 15 os.pathsep 输出用于分割文件路径的字符串,如环境变量;windows:\';\' linux:\':\' 16 os.name 输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\' 17 os.system("bash command") 运行shell命令,直接显示,无返回值 os.system("dir")
ret = os.popen("dir").read() 运行shell命令,不显示,有返回值
print(ret) 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径;print(os.path.abspath(\'./os.py\')) # D:\\code\\os.py 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如果path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 根据当前操作系统的路径分隔符将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
print(os.path.join(\'c:\',\'user\',\'local\')) # c:user\\local 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
30 os.path.getsize(path) 返回path的大小,path为具体文件名,如果path为目录将不准确
注意:os.stat(\'path/filename\') 获取文件/目录信息 的结构说明:


stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
sys模块-和python解释器交互的模块
1 sys.argv 命令行参数List,第一个元素是程序本身文件名 2 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称 print(sys.platform) #win32 7 sys.stdout.write(\'please:\') 8 val = sys.stdin.readline()[:-1]
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法;
1 import hashlib 2 3 m = hashlib.md5() 4 m.update("Hello".encode(\'utf8\')) #python3中,内存中的字符串都是unicode类型,update参数一定需要接收bytes类型,所以需要encode转换(因为python3中只有bytes和str两种数据类型) 5 m.update("It\'s me".encode(\'utf8\')) 6 print(m.digest()) #2进制格式hash b\']\\xde\\xb4{/\\x92Z\\xd0\\xbf$\\x9cR\\xe3Br\\x8a\' 7 print(len(m.hexdigest())) #16进制格式hash 5ddeb47b2f925ad0bf249c52e342728a 8 9 10 #加密过程等同于: 11 m2 = hashlib.md5() 12 m2.update("HelloIt\'s me".encode(\'utf8\')) 13 print(len(m2.hexdigest())) #16进制格式hash 5ddeb47b2f925ad0bf249c52e342728a 14 15 16 17 18 import hashlib 19 20 # ######## md5 ######## 21 22 hash = hashlib.md5() 23 hash.update(\'admin\') 24 print(hash.hexdigest()) 25 26 # ######## sha1 ######## 27 28 hash = hashlib.sha1() 29 hash.update(\'admin\') 30 print(hash.hexdigest()) 31 32 # ######## sha256 ######## 33 34 hash = hashlib.sha256() 35 hash.update(\'admin\') 36 print(hash.hexdigest()) 37 38 39 # ######## sha384 ######## 40 41 hash = hashlib.sha384() 42 hash.update(\'admin\') 43 print(hash.hexdigest()) 44 45 # ######## sha512 ######## 46 47 hash = hashlib.sha512() 48 hash.update(\'admin\') 49 print(hash.hexdigest())
logging模块
1.简单应用
1 import logging 2 logging.debug(\'debug message\') 3 logging.info(\'info message\') 4 logging.warning(\'warning message\') 5 logging.error(\'error message\') 6 logging.critical(\'critical message\') #输出 WARNING:root:warning message ERROR:root:error message CRITICAL:root:critical message
可见,默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
2.灵活配置日志级别,日志格式,输出位置(文件输出和标准输出只能选一种)
1 import logging 2 logging.basicConfig(level=logging.DEBUG, 3 format=\'%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s\', 4 datefmt=\'%a, %d %b %Y %H:%M:%S\', 5 filename=\'/tmp/test.log\', 6 filemode=\'w\') 7 8 logging.debug(\'debug message\') 9 logging.info(\'info message\') 10 logging.warning(\'warning message\') 11 logging.error(\'error message\') 12 logging.critical(\'critical message\') #查看输出: cat /tmp/test.log Mon, 05 May 2014 16:29:53 test_logging.py[line:8] DEBUG debug message Mon, 05 May 2014 16:29:53 test_logging.py[line:9] INFO info message Mon, 05 May 2014 16:29:53 test_logging.py[line:10] WARNING warning message Mon, 05 May 2014 16:29:53 test_logging.py[line:11] ERROR error message Mon, 05 May 2014 16:29:53 test_logging.py[line:12] CRITICAL critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。(a:追加写;w:覆盖写)
注意:如果没有指定filename和filemode,默认将日志打印到了标准输出中。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的默认日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(\'test.log\',\'w\')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
3.logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical() 分别用以记录不同级别的日志信息;logging.basicConfig() 用默认日志格式为日志系统建立一个默认的流处理器:设置基础配置(如日志级别等)并加到root logger中,这几个是logging模块级别的函数;另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
先看一个最简单的过程:
1 import logging 2 #创建一个日志(logger)对象 3 logger = logging.getLogger() 4 5 # 创建一个handler即文件输出流对象,用于写入日志文件 6 fh = logging.FileHandler(\'test.log\') 7 8 # 再创建一个handler即标准输出流对象,用于输出到控制台以上是关于python基础篇13-模块的主要内容,如果未能解决你的问题,请参考以下文章