这是跟着韦伟老师的Python数据分析课程做的爬虫实战项目,在这里记录下来,也方便学习分享。
2018-01-28 完成项目:
利用Python爬虫爬取淘宝网某类商品的图片
******Step1******
以连衣裙为例,观察淘宝网连衣裙商品第1页、第2页、第3页……网址的规律:
因此,不难发现出规律,q=后面接搜索词,s=(页数-1)*44
import urllib.request
import re
keyname="连衣裙"
key=urllib.request.quote(keyname)
for i in range(0,15):
url="https://s.taobao.com/search?q="+key+"&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s="+str(i*44)
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
先尝试上述代码的运行,若没报错误说明可以读取到相应搜索词的网页,则可进行下一步。
****Step2****
接着在网页中查看源代码,找出高清大图的网址,并构造其正则表达式:
我们先在第一页右键单击某张图片,复制其图片地址:
{kind=link}
打开该地址,发现是缩略图,并不是我们想要的高清图片。
通过与其他缩略图的网址相比较后,我们发现该网址中的TB1vTPZnL6H8KJjy0FjXXaXepXa为关键字符串,因此我们以此为关键字进行查找,仍显示没找到;我们将关键字缩短,最终发现,以“TB”为关键字,可以找到数十个类似以下格式的图片地址:
"pic_url":"//gsearch2.alicdn.com/img/bao/uploaded/i4/i2/1763644554/TB1VVVPocrI8KJjy0FhXXbfnpXa_!!0-item_pic.jpg"
我们将其打开,发现正是我们要找的高清大图的图片网址!
因此,我们构建出图片地址的正则表达式:
"pic_url":"//(.*?)"
接着step1的代码:
pat=‘"pic_url":"//(.*?)"‘
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
img=imagelist[j]
imgurl="http://"+img
file="F:/数据分析教程/result/taobao/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(imgurl,filename=file)
运行代码,没有报错,在python shell中输入imagelist查看是否成功:
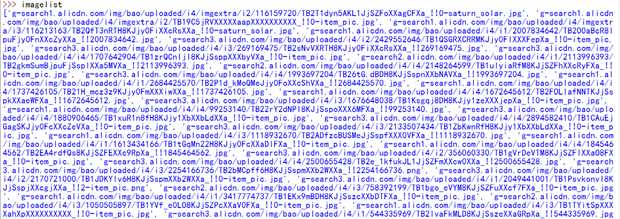
部分结果如上图,以列表形式存储的,正常来说是成功的,再回到代码中设置的F:/数据分析教程/result/taobao/目录下,发现图片都存放其中,并以ij.jpg命名。
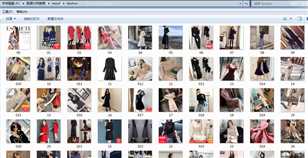
点击其中某一张,确定是高清大图,项目实验成功!