mit 6.824 lab1分析
Posted Wildhunt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mit 6.824 lab1分析相关的知识,希望对你有一定的参考价值。
6.824 lab1 笔记
1. 阅读论文
略
2. 官网rules & hints
2.1 rules
- map阶段每个worker应该把中间文件分成nReduce份,nReduce是reduce任务的数量
- worker完成reduce任务后生成文件名
mr-out-X mr-out-X文件每行应该是"%v %v"格式,参考main/mrsequential.go- worker处理完map任务,应该把生成的中间文件放到当前目录中,便于worker执行reduce任务时读取中间文件
- 当所有任务完成时,
Done()函数应该返回true,使得coordinator退出 - 所有任务完成时,worker应该退出,方法是:
- 当worker调用rpc向coordinator请求任务时,连接不上coordinator,此时可以认为coordinator已经退出因为所有任务已经完成了
- 当worker调用rpc向coordinator请求任务时,coordinator可以向其回复所有任务已经完成
2.2 hints
-
刚开始可以修改
mr/worker.go\'s ``Worker()向coordinator 发送一个RPC请求一个任务。然后修改coordinator回复一个文件名,代表空闲的map任务。然后worker根据文件名读取文件,调用wc.so-Map函数,调用Map函数可参考mrsequential.go` -
如果修改了
mr/目录下任何文件,应该重新build MapReduce plugins,go build -buildmode=plugin ../mrapps/wc.go -
worker处理完map任务后产生的中间文件命名格式
mr-X-Y,x是map任务的编号,y是reduce任务编号。// 初始文件,通过命令行传入的,如 // pg-being_ernest.txt pg-dorian_gray.txt pg-frankenstein.txt // len(files) = 3 nReduce = 4 // 中间文件 x:map任务的编号 y:reduce任务编号 // mr-0-0 mr-1-0 mr-2-0 // mr-0-1 mr-1-1 mr-2-1 // mr-0-2 mr-1-2 mr-2-2 // mr-0-3 mr-1-3 mr-2-3 -
map任务存储数据到文件可以使用json格式,便于reduce任务读取
// map enc := json.NewEncoder(file) for _, kv := ... err := enc.Encode(&kv) // reduce dec := json.NewDecoder(file) for var kv KeyValue if err := dec.Decode(&kv); err != nil break kva = append(kva, kv) -
map阶段使用
ihash(key)函数把key映射到哪个reduce任务,如某个worker取得了2号map任务,ihash("apple") = 1,那么就应该把该key放到mr-2-1文件中 -
可以参考
mrsequential.go代码:读取初始输入文件、排序key、存储reduce输出文件 -
coordinator是rpc server,将会被并发访问,需要对共享变量加锁
-
若当前未有空闲的map任务可以分配,worker应该等待一段时间再请求任务,若worker频繁请求任务,coordinator就会频繁加锁、访问数据、释放锁,浪费资源和时间。如使用
time.Sleep(),worker可以每隔一秒发送一次请求任务rpc -
coordinator无法辨别某个worker是否crash,有可能某个worker还在运行,但是运行极其慢(由于硬件损坏等原因),最好的办法是:coordinator监控某个任务,若该任务未在规定时间内由worker报告完成,那么coordinator可以把该任务重新分配给其他worker,该lab规定超时时间是10s
-
为了确保某个worker在写入文件时,不会有其他worker同时写入;又或者是某个worker写入文件时中途退出了,只写了部分数据,不能让这个没写完的文件让其他worker看到。可以使用临时文件
ioutil.TempFile,当写入全部完成时,再使用原子重命名os.Rename。 -
Go RPC只能传struct中大写字母开头的变量
-
调用RPC
call()函数时,reply struct应该为空,不然会报错reply := SomeType call(..., &reply)
3. 架构设计
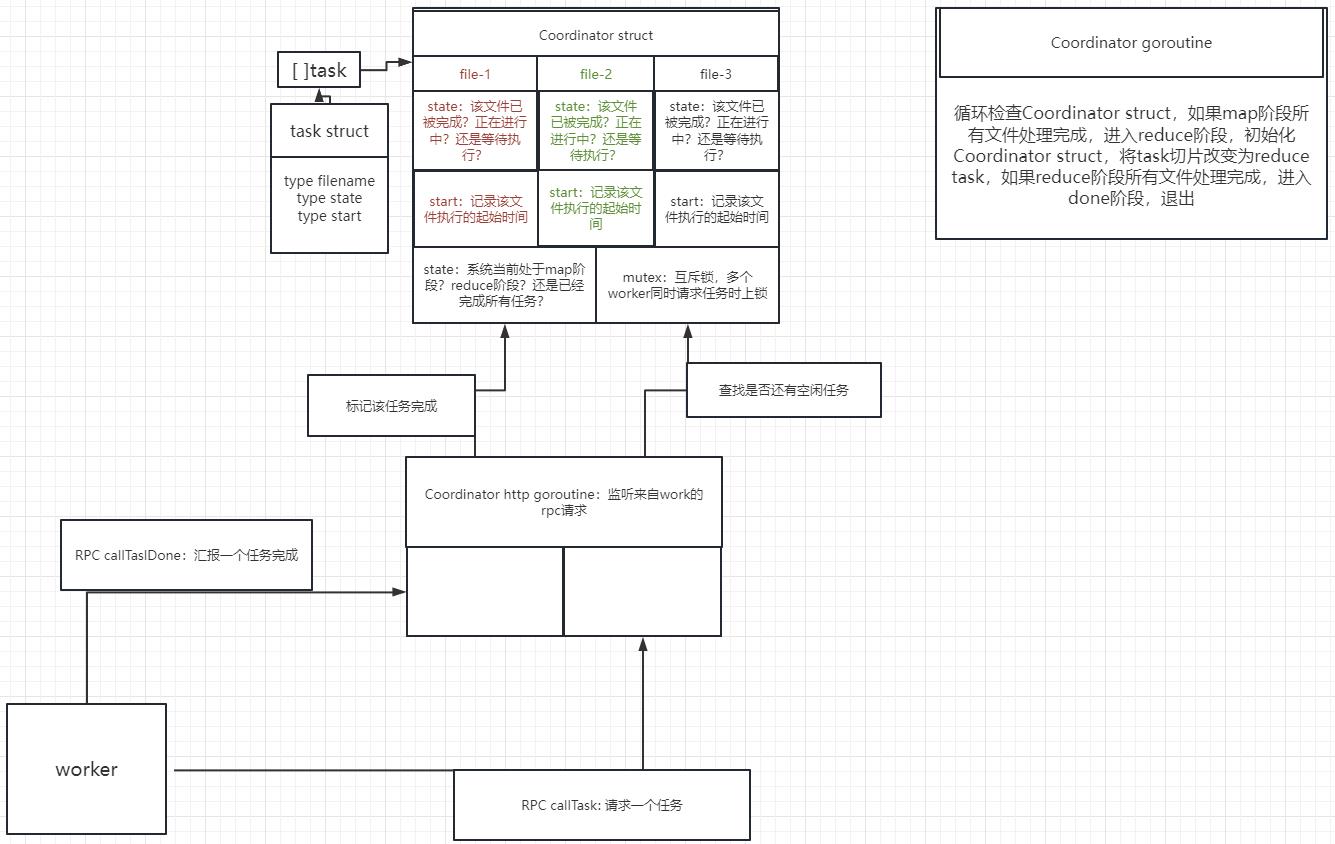
3.1 RPC设计
在该lab中,我们需要两个RPC,一个是callTask RPC向coordinator请求一个任务,一个是callTaskDone RPC向coordinator报告某个任务的完成,以下皆在rpc.go中定义
-
首先定义一个枚举变量,表示coordinator给worker分配的任务类型,也可用来表示coordinator当前的phase
type taskType int const ( // map任务 mapType taskType = iota // reduce任务 reduceType // 当前没有空闲任务,请等待 waitting // 已经完成全部任务,可以退出了 done ) -
定义拉取任务RPC的args和reply struct
CallTaskArgs中不需要包含变量,只需要让coordinator知道该worker正在请求一个任务,coordinator会随机选择空闲任务进行分配填入CallTaskReply中CallTaskReply包含以下变量:FileName:map阶段,worker需要知道具体的文件名才能解析该文件tp:指示该任务的具体类型TaskID:worker将该变量放入CallTaskDoneArgs中,coordinator可以迅速定位Task[TaskID],并且在reduce阶段中,搭配nFiles变量,worker读取mr-0-TaskID、mr-1-TaskID....mr-nFiles-1-TaskID文件nFiles:初始文件的数量,用于搭配TaskID,在上面已介绍nReduce:用于map阶段,ihash(key) % nReduce
type CallTaskArgs struct type CallTaskReply struct FileName string TaskID int tp taskType nFiles int nReduce int -
定义报告任务完成RPC的args和reply struct
TaskID变量作用在CallTaskReply: TaskID中提及tp的作用是用于coordinator判断该RPC是否是合法的,举例:worker-1成功请求到map-1任务,但是因为worker-1节点硬件问题处理缓慢而导致coordinator检测到该map-1任务超时,于是把map-1任务分配给了worker-2。等到某个时间点,已经完成所有map任务,coordinator进入到了reduce阶段,但此时worker-1节点才刚运行完map-1任务并报告给coordinator,coordinator检测到当前是reduce阶段,但收到报告完成的rpc是map类型,不会对其进行任何操作。type CallTaskDoneArgs struct TaskID int tp taskType type CallTaskDoneReply struct
3.2 Coordinator
3.2.1 结构体设计
type taskState int
const (
spare taskState = iota
executing
finish
)
type task struct
fileName string
id int
state taskState
start time.Time
首先设计一个task struct,该结构体代表一个任务
filename:在map阶段,用于coordinator告知worker要读取的初始文件id: 该任务的id,传给worker,作用在RPC设计中提及state:任务有三个状态:空闲、执行中、已完成。若空闲则可以分配给worker;若执行中,则监视该任务是否超时start:任务刚开始执行的时间
type Coordinator struct
// Your definitions here.
mu sync.Mutex
state taskType
tasks []*task
mapChan chan *task
reduceChan chan *task
nReduce int
nFiles int
finished int
接着设计主要Coordinator结构体
state:当前系统的状态,map阶段(分配map任务)、reduce阶段(分配reduce任务)、全部完成done(可以结束系统运行)tasks: *task的切片,维护了一组任务mapChan、reduceChan:用于分发map、reduce任务的channel。map阶段,若有空闲map任务,则放至channel中,当有worker请求任务时,则可取出来。reduce阶段同理finished:当前已完成任务的数量。map阶段,若finished == nFiles,则表示所有map任务完成,可以进入reduce阶段。reduce阶段同理,进入done
3.2.2 初始化
func MakeCoordinator(files []string, nReduce int) *Coordinator
c := Coordinator
// Your code here.
c.mapPhase(files, nReduce)
go c.watch()
c.server()
return &c
func (c *Coordinator) mapPhase(files []string, nReduce int)
c.state = mapType //设置系统状态为map阶段
c.nReduce = nReduce
c.nFiles = len(files)
c.tasks = make([]*task, c.nFiles)
c.mapChan = make(chan *task, c.nFiles) // c.nFiles长度的map channel
for i := 0; i < c.nFiles; i++
c.tasks[i] = &taskfileName: files[i], id: i
c.mapChan <- c.tasks[i] // 刚开始所有任务都是空闲状态,放入channel中
系统刚开始时即map阶段,mapPhase初始化Coordinator结构体。然后启动c.watch()协程,用于监视任务是否超时,放后面讲
3.2.3 分配任务
func (c *Coordinator) CallTask(args *CallTaskArgs, reply *CallTaskReply) error
c.mu.Lock()
defer c.mu.Unlock()
if c.state == done
reply.Tp = done
else if c.state == mapType
switch len(c.mapChan) > 0
case true:
task := <-c.mapChan
c.setReply(task, reply)
case false:
reply.Tp = waitting
else
switch len(c.reduceChan) > 0
case true:
task := <-c.reduceChan
c.setReply(task, reply)
case false:
reply.Tp = waitting
return nil
func (c *Coordinator) setReply(t *task, reply *CallTaskReply)
if t.state == finish
reply.Tp = waitting
return
reply.Tp = c.state
reply.TaskID = t.id
reply.NReduce = c.nReduce
reply.NFiles = c.nFiles
reply.FileName = t.fileName
t.state = executing
t.start = time.Now()
分配任务的主要函数,worker处会调用call("Coordinator.CallTask", &args, &reply)。
- 若当前系统状态为done,则返回done,告知worker可以退出了
- 若当前系统状态为map阶段:如果当前有任务可以分配
len(c.mapChan) > 0,则取出一个task,调用c.setReply(task, reply),将任务的相关信息填入reply中,并把task的当前状态设为执行中,开始时间设为time.Now()。如果没有可分配的任务,则设reply.Tp = waitting,让worker等待一会再请求任务 - 若当前系统状态为reduce阶段:同上
3.2.4 任务完成
func (c *Coordinator) CallTaskDone(args *CallTaskDoneArgs, reply *CallTaskDoneReply) error
c.mu.Lock()
defer c.mu.Unlock()
if c.state != args.Tp || c.state == done
return nil
if c.tasks[args.TaskID].state != finish
c.tasks[args.TaskID].state = finish
c.finished++
//fmt.Printf("task %v done\\n", args.TaskID)
if c.state == mapType && c.finished == c.nFiles
c.reducePhase()
else if c.state == reduceType && c.finished == c.nReduce
close(c.reduceChan)
c.state = done
return nil
func (c *Coordinator) reducePhase()
//fmt.Printf("reduce phase\\n")
close(c.mapChan)
c.state = reduceType
c.tasks = make([]*task, c.nReduce)
c.finished = 0
c.reduceChan = make(chan *task, c.nReduce)
for i := 0; i < c.nReduce; i++
c.tasks[i] = &taskid: i
c.reduceChan <- c.tasks[i]
worker处会调用call("Coordinator.CallTaskDone", &args, &reply)来报告某任务的完成
首先判断c.state != args.Tp,即报告完成的任务类型和当前系统状态不匹配,可能发生在该情况:work-1请求了map-1任务,但是work-1运行太缓慢导致Coordinator监测到map-1任务超时,于是把map-1任务分配给了work-2。当所有map任务完成时,Coordinator进入了reduce阶段,这时work-1才报告map-1任务完成,与当前系统状态不匹配,故会直接返回
若该任务未完成,则将该任务标记未已完成,c.finished++。
- 如果当前为map阶段并且所有map任务已完成
c.state == mapType && c.finished == c.nFiles,则进入reduce阶段:- 关闭map channel
- 将系统状态设为reduce
- 重置c.tasks为一系列reduce任务
- 创建长度为c.nReduce的reduce channel
- 放入任务
- 如果当前为reduce阶段并且所有map任务已完成
c.state == reduceType && c.finished == c.nReduce,则进入done阶段:- 关闭reduce channel
- 将系统状态设为done
3.2.5 监测超时任务goroutine
func (c *Coordinator) watch()
for
time.Sleep(time.Second)
c.mu.Lock()
if c.state == done
return
for _, task := range c.tasks
if task.state == executing && time.Since(task.start) > timeout
task.state = spare
switch c.state
case mapType:
c.mapChan <- task
case reduceType:
c.reduceChan <- task
c.mu.Unlock()
如果当前系统状态为done了,可以退出协程了
循环任务列表,如果该任务状态是正在执行但是超时了time.Since(task.start) > timeout(time.Since可以计算系统当前时间距离start过去了多少时间),将该任务状态重置为空闲状态,并且根据系统当前状态,把该任务重新放入对应的channel中
3.3 Worker
3.3.1 主流程
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string)
for
args := CallTaskArgs
reply := CallTaskReply
ok := call("Coordinator.CallTask", &args, &reply)
//now := time.Now()
if ok
switch reply.Tp
case mapType:
executeMap(reply.FileName, reply.NReduce, reply.TaskID, mapf)
case reduceType:
executeReduce(reply.NFiles, reply.TaskID, reducef)
case waitting:
time.Sleep(time.Second * 2)
continue
case done:
os.Exit(0)
else
time.Sleep(time.Second * 2)
continue
//fmt.Printf("finish task: %v %v use %v\\n", reply.TaskID, rs(reply.Tp), time.Since(now).Seconds())
a := CallTaskDoneArgsreply.TaskID, reply.Tp
r := CallTaskDoneReply
call("Coordinator.CallTaskDone", &a, &r)
time.Sleep(time.Second * 2)
首先向Coordinator发送请求任务rpc:
- map任务:执行
- reduce任务:执行
- waitting:当前Coordinator没有空闲任务,sleep一段时间再请求
- done:所有任务已完成,退出
任务执行完成后,报告任务完成
3.3.2 执行map任务
func executeMap(fileName string, nReduce, taskID int, mapf func(string, string) []KeyValue)
file, err := os.Open(fileName)
if err != nil
log.Fatalf("cannot open %v", fileName)
content, err := ioutil.ReadAll(file)
if err != nil
log.Fatalf("cannot read %v", fileName)
file.Close()
kva := mapf(fileName, string(content))
// 上面的代码参考mrsequential.go
files := []*os.File
tmpFileNames := []string
encoders := []*json.Encoder
for i := 0; i < nReduce; i++
tempFile, err := ioutil.TempFile("./", "")
if err != nil
log.Fatalf("cannot open temp file")
files = append(files, tempFile)
tmpFileNames = append(tmpFileNames, tempFile.Name())
encoders = append(encoders, json.NewEncoder(tempFile))
for _, kv := range kva
n := ihash(kv.Key) % nReduce
encoders[n].Encode(kv)
for i := 0; i < nReduce; i++
files[i].Close()
os.Rename(tmpFileNames[i], "./"+intermediateFileName(taskID, i))
在当前目录创建nReduce个临时文件ioutil.TempFile("./", ""),使用该临时文件创建json.Encoder(在hints第四条),使用ihash函数把每个key映射到哪个文件,写入json格式,然后对每个临时文件重命名为mr-x-y格式
生成中间文件名函数:
func intermediateFileName(x, y int) string
return fmt.Sprintf("mr-%v-%v", x, y)
3.3.3 执行reduce
func executeReduce(nFiles, taskID int, reducef func(string, []string) string)
kvs := []KeyValue
for i := 0; i < nFiles; i++
filename := intermediateFileName(i, taskID)
// 读取每个中间文件
file, err := os.Open(filename)
if err != nil
log.Fatalf("cannot open %v", filename)
// 参考hints第四条,从文件中取出json格式的每条数据
decoder := json.NewDecoder(file)
for
var kv KeyValue
// 已读到文件末尾
if err := decoder.Decode(&kv); err != nil
break
kvs = append(kvs, kv)
file.Close()
// 参考mrsequential.go
oname := fmt.Sprintf("mr-out-%v", taskID)
tempFile, _ := ioutil.TempFile("./", "")
tempFileName := tempFile.Name()
sort.Sort(ByKey(kvs))
for i := 0; i < len(kvs);
j := i + 1
for j < len(kvs) && kvs[j].Key == kvs[i].Key
j++
values := []string
for k := i; k < j; k++
values = append(values, kvs[k].Value)
output := reducef(kvs[i].Key, values)
fmt.Fprintf(tempFile, "%v %v\\n", kvs[i].Key, output)
i = j
tempFile.Close()
os.Rename(tempFileName, "./"+oname)
MIT开发神经网络模型,检测自然对话中的抑郁迹象
编译:chux
出品:ATYUN订阅号
麻省理工学院的研究人员开发了一种神经网络模型,可以分析采访中的原始文本和音频数据,以发现指示抑郁症的语音模式。该方法可用于为临床医生开发诊断辅助工具,以便在自然对话中检测到抑郁症的迹象。
为了诊断抑郁症,临床医生采访患者,询问具体问题,例如,过去的精神疾病,生活方式和情绪,并根据患者的反应确定病情。
近年来,机器学习一直被认为是诊断的有用辅助手段。例如,机器学习模型可以检测指示抑郁的语音的单词和语调。但是这些模型倾向于根据个人对特定问题的具体答案来预测一个人是否抑郁。这些方法是准确的,但是它们依赖于被问到的问题类型,这样限制了它们的使用方式和位置。
在Interspeech会议上发表的一篇论文中,麻省理工学院的研究人员详细介绍了一种神经网络模型,该模型可以通过采访发现原始文本和音频数据,以发现指示抑郁症的语音模式。给定一个新的主题,它可以准确地预测个体是否抑郁,而不需要任何其他有关问题和答案的信息。
研究人员希望这种方法可以用来开发在自然对话中检测抑郁迹象的工具。例如,在未来,该模型可以为移动应用程序提供支持,以监控用户的文本和语音以进行精神痛苦并发送警报。这对于那些无法获得初步临床医生诊断的人来说尤其有用,因为有距离、成本的限制,或者缺乏相关意识。
论文第一作者,计算机科学与人工智能实验室研究员Tuka Alhanai说:“我们得到的第一个提示是,一个人可能快乐,兴奋,悲伤或有一些严重的认知状况,如抑郁症。如果你想以可扩展的方式部署抑郁检测模型……你希望最大限度地减少对你正在使用的数据的约束。你希望在任何常规对话中部署它,并从自然交互,个人状态中获取模型。”
CSAIL的高级研究科学家James Glass补充说,该技术当然可用于识别临床办公室临时谈话中的精神痛苦。“每个病人的谈话方式都不同,如果模型看到变化可能会提示医生,这是一种进步,看是否可以做一些帮助临床医生的辅助工作。”
该论文的另一位合着者是医学工程与科学研究所(IMES)成员Mohammad Ghassemi。
无上下文建模
该模型的关键创新在于能够检测指示抑郁症的模式,然后将这些模式映射到新的个体,而无需额外的信息。“我们称之为’无上下文’,因为你没有对你正在寻找的问题类型以及对这些问题的回答类型施加任何限制,”Alhanai说。
其他模型提供了一组特定的问题,然后举例说明没有抑郁症的人如何回应以及抑郁症患者如何反应的例子,例如,直截了当的询问,“你有抑郁症的历史吗?”它使用那些确切的答案,然后在被问到完全相同的问题时确定新个体是否抑郁。“但这不是自然对话的工作方式,”Alhanai说。
另一方面,研究人员使用了一种称为序列建模的技术,通常用于语音处理。通过这种技术,他们一个接一个地从抑郁和非抑郁个体的问题和答案中提供文本和音频数据的模型序列。随着序列的积累,该模型提取出有或没有抑郁症的人出现的语音模式。诸如“悲伤”,“低”或“向下”之类的单词可以与更平白且更单调的音频信号配对。患有抑郁症的个体也可能说话较慢并且在单词之间使用较长的暂停。在以前的研究中已经探索了这些用于精神痛苦的文本和音频标识符。最终由模型确定是否有任何模式可以预测抑郁症。
Alhanai表示,“该模型可以看到单词或说话风格的序列,并确定这些模式更有可能出现在抑郁或不抑郁的人身上。然后,如果它在新实验对象中看到相同的序列,它也可以预测他们是否是抑郁的。”
这种测序技术还有助于模型将整个会话视为对话,并注意随着时间的推移,有抑郁症和无抑郁症的人之间的差异。
检测抑郁症
研究人员在来自遇险分析访谈语料库的142个相互作用的数据集上训练和测试了他们的模型,该数据集包含患有心理健康问题的患者和由人类控制的虚拟智能体的音频,文本和视频访谈。使用个人健康问卷调查,每个受试者按0到27之间的等级评定抑郁。高于中度(10至14)和中度(15至19)之间的阈值的得分被认为是抑郁的,而低于该阈值的所有其他得分被认为是不抑制的。在数据集中的所有主题中,28个(20%)被标记为抑郁。
在实验中,使用精确度和回忆来评估模型。精确度测量由模型识别的哪些抑郁受试者被诊断为抑郁。回忆测量模型在检测整个数据集中被诊断为抑郁的所有受试者时的准确性。在精确度方面,该模型得分为71%,并且在回忆得分为83%。考虑到任何的错误,这些指标的平均综合得分为77%。在大多数测试中,研究人员的模型几乎超过了所有其他模型。
Alhanai指出,该研究的一个关键见解是,在实验过程中,该模型需要更多的数据来预测音频中的抑郁而不是文本。通过文本,模型可以使用平均七个问答序列准确地检测抑郁症。通过音频,该模型需要大约30个序列。“这意味着人们使用的词汇模式可以预测抑郁症发生在文本的短时间内,而不是音频,”Alhanai说。这些见解可以帮助麻省理工学院的研究人员和其他人进一步完善他们的模型。
Glass表示,这项工作代表了一个“非常鼓舞人心”的试点。但现在研究人员试图发现模型在大量原始数据中识别出哪些特定模式。“现在它有点像黑盒子,但是,当你对他们正在采取的措施有所解释时,这些系统更加可信。接下来的挑战是找出它抓住的数据。”
研究人员还旨在测试这些方法来测试来自更多具有其他认知条件(如痴呆)的受试者的其他数据。“这不是检测抑郁症,而是类似的概念,如果有人有认知障碍可以根据言语中的日常信号进行评估。”
以上是关于mit 6.824 lab1分析的主要内容,如果未能解决你的问题,请参考以下文章