08_Python编码与解码
Posted 短毛兔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了08_Python编码与解码相关的知识,希望对你有一定的参考价值。
一、编码的由来
因为计算机只能处理010101二进制数据,如果要处理文本,图像,视频等,需要我们把数据转换成01010二进制格式才能被计算机处理
最先出现的是ASCII,用8位一个字节来表示,成为单字节码,一个字节最多能表示256种可能,只能表示英文和符号。无法表示中文、日文、韩文等其他语言256明显不够。所以unicode应运而生,unicode采用32位4个字节来表示,把所有的语言都统一到一套编码里,解决了乱码问题。
但新的问题出现了,如果编写一份英文文档,采用unicode编码的文件比ascii编码的文件多两倍的空间,在存储和传输上显得浪费资源。
utf-8应运而生,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
二、计算机编码工作方式:
在计算机内存种,统一使用unicode编码,当需要保存到硬盘或者需要传输的时候,采用utf-8编码。
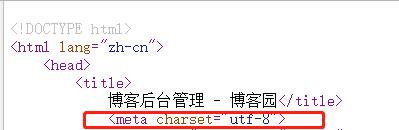
我们查看博客园的源代码,就可以看出,服务器传输给浏览器的编码格式是utf-8.
三、Python3字符编码
在python3当中,str在内存中的编码是unicode。如果需要存储、传输,使用unicode太浪费资源,所以转换成非unicode编码进行存储和传输。
bytes(字节):数据存储是以bytes为单位。字节是指一小组相邻的二进制数码。通常是8位作为一个字节。它是构成信息的一个小单位,并作为一个整体来参加操作,比字符串小,是构成字符串的单位。
字节:一串二进制数码作为一个整体来处理或运算,而这个整体就是字节。在计算机中,通常使用字节来表示存储器的存储容量,
在数据类型中,通常char占1个字节,int4个字节。
在字符编码中:
ASCII编码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
Unicode编码:一个英文等于四个字节,一个中文(含繁体)等于四个字节。
unicode -> 非unicode编码
Bytes类型和str类型数据转换其实就是编码与解码的过程
utf-8,gbk都是指定编解码时的格式
#str -> gbk s = \'zhangsan\' b = s.encode("gbk") s1 = \'中国\' b1 = s1.encode("gbk") print(b)#b\'zhangsan\' print(b1)#b\'\\xd6\\xd0\\xb9\\xfa\' gbk是两个字节一个中文 中\\xd6\\xd0 国\\xb9\\xfa # str -> utf-8 s = \'zhangsan\' s1 = \'张三\' b = s.encode(\'utf-8\') b1 = s1.encode(\'utf-8\') print(b) #b\'zhangsan\' print(b1) #b\'\\xe5\\xbc\\xa0\\xe4\\xb8\\x89\' utf8是三个字节一个中文 张\\xe5\\xbc\\xa0 三\\xe4\\xb8\\x89
str 内部是unicode
使用encod转换成非unicode编码,如utf、gbk
以上是关于08_Python编码与解码的主要内容,如果未能解决你的问题,请参考以下文章