Weex原理及架构剖析
Posted zhoulujun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Weex原理及架构剖析相关的知识,希望对你有一定的参考价值。
早期H5和Hybrid方案的本质是,利用客户端App的内置浏览器(也就是webview)功能,通过开发前端的H5页面满足跨平台需求。比如PhoneGap cordova ionic ……
该方案提升开发效率,同时也满足了跨端的需求。但有一个问题就是,前端H5的性能和客户端的性能相差甚远。Facebook 推出ReactNative
关于RN,安利下《ReactJS到React-Native,架构原理概述》
Weex与ReactNative 都是基于Yogo渲染骨架做的 跨端框架,一个基于React,一个基于Vue,个人偏好RN,但是Weex 貌似更香。
相对于ReactNative的“learn once write anywhere”,weex的: “write once run anywhere”,牛皮更宽广
关于Weex的使用,还是看官方文档好:https://weex.apache.org/zh/guide/introduction.html
Weex的源文件(最新的Weex版本支持的是Vue文件),如果想用React, 也可以用Rax(兼容React接口), 甚至如果可能,可以支持更多的前端框架。因为根据Weex设计前端框架仅仅是语法层(或者叫DSL), 它与原生渲染引擎是分离的。当然自己扩展支持另一套前端框架也比较麻烦,需要做不少工作。




Weex架构分析
js的执行环境
在初始化阶段, WEEX SDK 会准备好一个js的执行环境。因为我们是要在客户端跑js 代码的,所以需要一个js执行环境,这个执行环境类似于浏览器的v8 引擎, 在IOS 上,则是客户端自带的 js core。
这个js执行环境,可以看成是一个在客户端上的沙盒,或者是一个虚拟机。
为了提升性能,js 执行环境只用在初始化的时候初始化一次,之后每个页面都无须再初始化了。也就是说不管客户端打开多少个weex页面,多个页面的 JS 都是跑在同一个js执行环境中的。
weex-vue-famework 框架
weex-vue-framework 框架 是什么呢?
你可以把 weex-vue-framework 框架当成被改造的Vue.js。语法和内部机制都是一样的,只不过Vue.js最终创建的是 DOM 元素,而weex-vue-framework则是向原生端发送渲染指令,最终渲染生成的是原生组件。
同时,Weex为了提高Native的极致性能,做了很多优化的工作。前端优化性能时,会把业务代码和 vue.js 这类的依赖包分开打包,一个份是业务代码,一份是打包的框架依赖。
weex 把weex-vue-framework 这类框架依赖内置到了SDK中,客户端访问Weex页面时,只会网络请求JS Bundle。由于JSFramework在本地,所以就减少了JS Bundle的体积,每个JS Bundle都可以减少一部分体积,从而提升了性能。
WXBridge 通信
WXBridge 是 weex 实现的一种 js 和 客户端通信的机制。
js 执行环境和客户端是隔离的,为了和外界客户端的世界通信,需要有一个通信的桥梁。weex 实现了 WXBrigde, 主要通过 callJS 和 callNative 两个核心的方法,实现 js 代码和客户端代码双向通信。
在完成了上面的初始化之后,weex已经做好了准备,只等着下载 JS bundle 就可开始渲染页面了。
Weex工作原理分析
weex 能让一套代码能做成 native 级别的app,主要是做了三件事:
-
在本地用一个叫做 transformer 的工具把这套代码转成纯 JavaScript 代码
-
在客户端运行一个 JavaScript 引擎,随时接收 JavaScript 代码
-
在客户端设计一套 JS Bridge,让 native 代码可以和 JavaScript 引擎相互通信


Weex源码转换成JS Bundle
整体工作可以分为三个部分
1、转换 <template> 为 类JSON的树状数据结构, 转换数据绑定 为 返回数据的函数原型。#####
<foo a="x" b="1" /> --> type: "foo", attr: a: function () return this.x, b: 1.
2、转换 <style> 为 类JSON的树状数据结构。
.classname name: value; --> classname : name : value .
3、 把上面两部分的内容和 <script> 中的内容结合成一个JavaScript AMD(AMD:异步模块规范) 模块。#####
<template> <foo a="x" b="1" class="bar"></foo> </template> <style> .bar width: 200; height: 200 </style> <script> module.exports = data: function () return x: 100 </script>
将转换为:
define(\'@weex-component/main\', function () module.exports = data: function () return x: 100 module.template = type: "foo", attr: a: function () return this.x, b: 1, classname: [\'bar\'] module.style = bar: width: 200, height: 200 ) bootstrap(\'@weex-component/main\')
说明1:除此之外,转换器还会做一些额外的事情: 合并Bundle ,添加引导函数,配置外部数据等等。
说明2:案例来自Weex的官方文档。当前大部分Weex工具最终输出的JS Bundle格式都经过了Webpack的二次处理,所以你实际使用工具输出的JS Bundle会和上面的有所区别。
获取到JS Bundle后创建 weex 实例
实际上当WEEX SDK获取到JS Bundle后,第一时间并不是立马渲染页面,而是先创建WEEX的实例。
每一个JS bundle对应一个实例,同时每一个实例都有一个instance id。
我们上文中说过,由于所有的js bundle都是放入到同一个JS执行引擎中执行,那么当js执行引擎通过WXBridge将相关渲染指令传出的时候,需要通过instance id才能知道该指定要传递给哪个weex实例
在创建实例完成后,接下来才是真正将js bundle交给js执行引擎执行。


在实例创建完成后,接下来就是执行JS bundle 了。JS bundle 的结果是生成Virtual DOM ,然后去patch 新旧 Vnode 树,根据diff 算法找出最佳的DOM操作,唯一和浏览器不同的是,调用的是 Native app api ,而不是浏览器里面对DOM节点增删改查的操作。
Native渲染
Native 渲染引擎提供客户端组件(Component)和模块(Module)
-
组件(Component):在屏幕内可见,有特定行为,能被配置不同的属性和样式,能响应用户交互,常见的组件有: <div>、<text>、 <image>。
-
模块(Module): 是一组能被JS Framework调用的API. 其中的一些能以异步的方式调用JS Framework, 例如: 发送HTTP请求。
Weex 的渲染流程
Weex 的渲染流程如下图:
Virtual DOM ->
-> Build Tree -> Apply Style -> Create View -> Update Frame -> Attach Event ->CSS Layout ->Update Frame
->Native/H5 View
输入:虚拟DOM
-
构造树结构. 分析虚拟DOM JSON数据以构造渲染树(RT).
-
添加样式. 为渲染树的各个节点添加样式.
-
创建视图. 为渲染树各个节点创建Native视图.
-
绑定事件. 为Native视图绑定事件.
-
CSS布局. 使用 css-layout 来计算各个视图的布局.
-
更新视窗(Frame). 采用上一步的计算结果来更新视窗中各个视图的最终布局位置.
输出:Native UI 页面
参考文章:
Weex 2:浅说Weex工作原理 https://www.jianshu.com/p/32285c709682
深入理解weex内核原理 https://zhuanlan.zhihu.com/p/71064826
转载本站文章《Weex原理及架构剖析》,
请注明出处:https://www.zhoulujun.cn/html/webfront/AppDev/Weex/8495.html
Flink 核心组件 架构原理 多图剖析
一、Flink 整体架构
-
接受 application,包含 StreamGraph(DAG),JobGraph(优化过的)和 JAR,将 JobGraph 转换为 Execution Graph -
申请资源,调度任务,执行任务,保存作业的元数据,如Checkpoint -
协调各个 Task 的 Checkpoint。
二、JobManager 内部组成原理
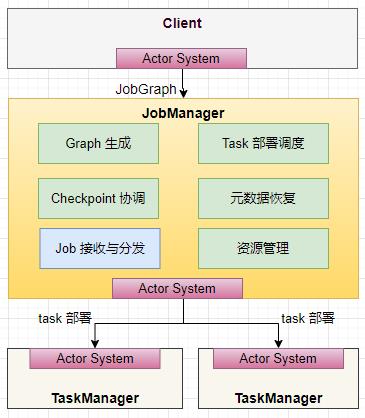
-
负责 Checkpoint 的协调,通过定时做快照的方式记录任务状态信息; -
Job Dispatch 负责接收客户端发送过来的 JobGraph 对象(DAG),并且在内部生成 ExecutionGraph(物理执行图); -
将作业拆分成 Task,部署到不同的 TaskManager 上去执行;ctorSystem 是 基于 akka 实现的一个通信模块,负责节点之间的通信,如 Client 和 JobManager 之间,JobManager 和 TaskManager 之间的通信; -
负责资源管理,对于不同的部署模式,有相应的 ResourceManager 的实现; -
TaskManager 启动时,会向 JobManager 注册自己,并时刻和 JobManager 保持心跳。
三、TaskManager 内部原理
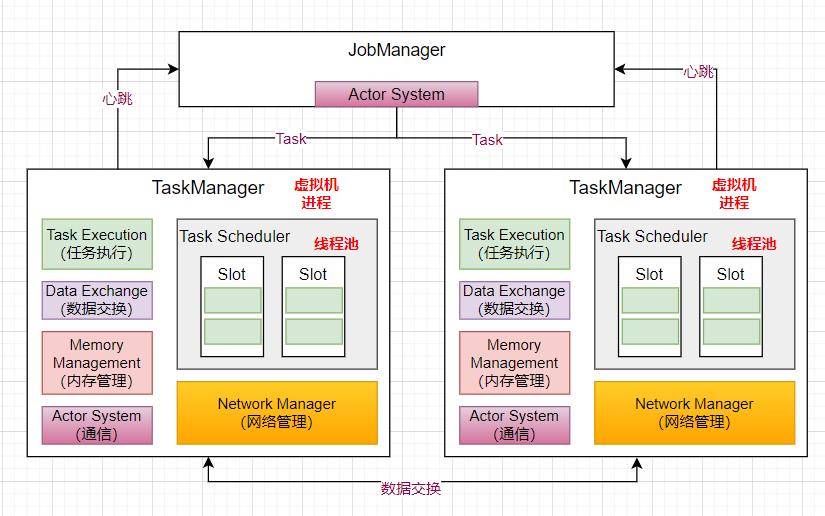
-
TaskManager 是作为一个虚拟机进程存在,TaskManager 启动的时候,会向 JobManager 注册自己; -
JobManager 提交作业的时候,TaskManager 会启动 Task 线程将 Job 运行起来,TaskManager 里面有线程池负责线程的调度执行。 -
在 Flink 内部也会有类似 Spark 或者 MapReduce 节点 shuffle 的过程,比如进行了一个 GroupByKey 的操作,就会涉及到数据的交互;Network Manager 是基于 Netty 实现的一个数据传输模块; -
而节点和节点之间的通信是基于 akka 实现的 Actor System,来进行远程的 rpc 通信; -
Memory Management 是内存管理模块,当数据进来时,负责申请内存来运行任务。
TaskManager 如何负责数据传输
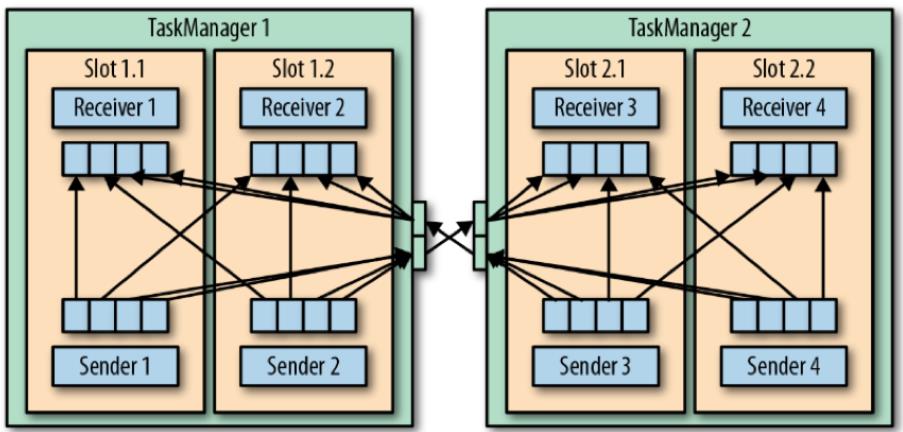
四、Client 内部原理
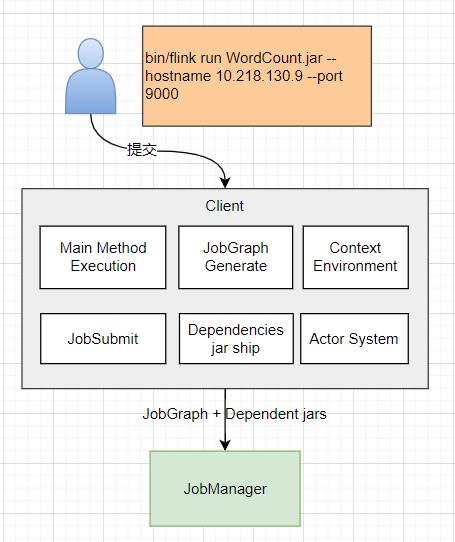
五、JobGraph
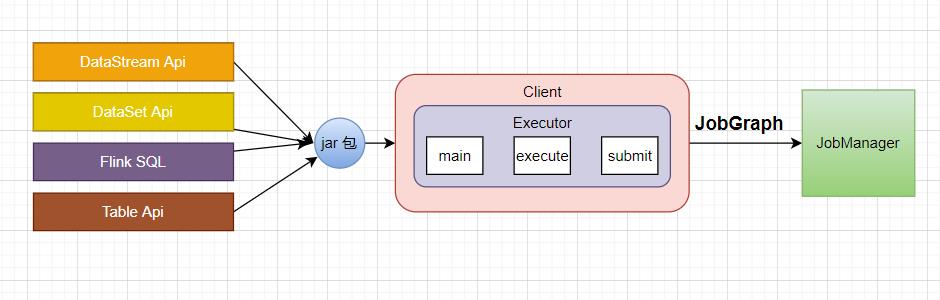
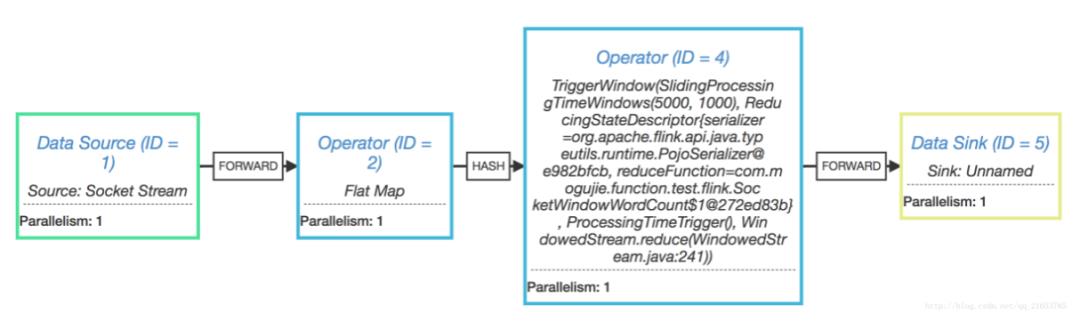
End

Q: 关于实时数仓你还想了解什么?
更多精彩,请在文末点击“实时数仓”查看
!关注不迷路~ 各种福利、资源定期分享!
以上是关于Weex原理及架构剖析的主要内容,如果未能解决你的问题,请参考以下文章