数据库升级
Posted lin513
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库升级相关的知识,希望对你有一定的参考价值。
修改的地方
1.MydatabaseHelper中的onUpgrade:
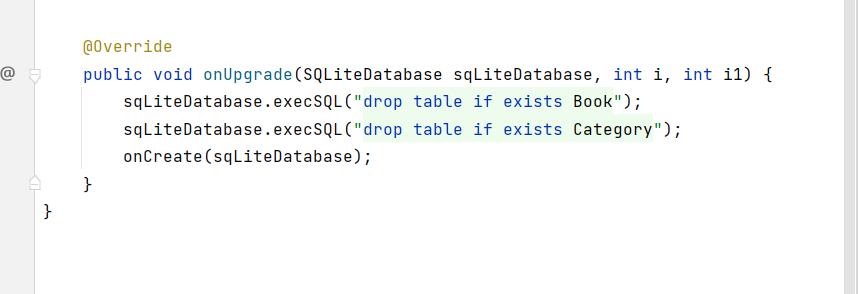
增加了两条语句,并且执行onCreate方法
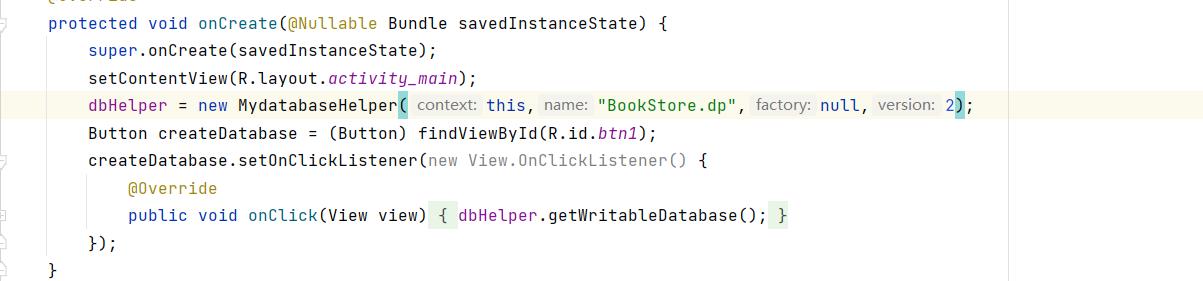
2.MainActivity中将版本号改成2
Druid时序数据库升级流程
Druid升级流程
目前Druid集群版本为0.11.0,新版本0.12.1已支持Druid SQL和Redis,考虑到Druid新特性以及性能的提升,因此需要将Druid从0.11.0版本升级到0.12.1版本,下面将对Druid升级步骤做详细的介绍,升级时请严格按照此步骤进行升级,以免出现一些不可预知的问题。
1. Druid升级包
Druid官网下载druid-0.12.1-bin.tar.gz和mysql-metadata-storage-0.12.1.tar.gz
2. 配置Druid-0.12.1
- 解压druid-0.12.1-bin.tar.gz
[[email protected]]$ tar -zxvf druid-0.12.1-bin.tar.gz
[[email protected]]$ rm -rf druid-0.12.1-bin.tar.gz- 解压mysql-metadata-storage-0.12.1.tar.gz
[[email protected]]$ tar -zxvf mysql-metadata-storage-0.12.1.tar.gz -C druid-0.12.1/extensions/
[[email protected]]$ rm -rf mysql-metadata-storage-0.12.1.tar.gz3. 配置common.runtime.properties
[[email protected] druid-0.11.0]$ cd conf/druid/_common
[[email protected] _common]$ vi common.runtime.properties# If you specify `druid.extensions.loadList=[]`, Druid won‘t load any extension from file system.
# If you don‘t specify `druid.extensions.loadList`, Druid will load all the extensions under root extension directory.
# More info: http://druid.io/docs/latest/operations/including-extensions.html
druid.extensions.loadList=["druid-kafka-eight", "druid-hdfs-storage", "druid-histogram", "druid-datasketches", "druid-lookups-cached-global", "mysql-metadata-storage"]
# If you have a different version of Hadoop, place your Hadoop client jar files in your hadoop-dependencies directory
# and uncomment the line below to point to your directory.
#druid.extensions.hadoopDependenciesDir=/my/dir/hadoop-dependencies
#
# Logging
#
# Log all runtime properties on startup. Disable to avoid logging properties on startup:
druid.startup.logging.logProperties=true
#
# Zookeeper
#
druid.zk.service.host=172.16.XXX.XXX:2181
druid.zk.paths.base=/druid
#
# Metadata storage
#
# For Derby server on your Druid Coordinator (only viable in a cluster with a single Coordinator, no fail-over):
#druid.metadata.storage.type=derby
#druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
#druid.metadata.storage.connector.host=localhost
#druid.metadata.storage.connector.port=1527
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://172.16.XXX.XXX:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456
# For PostgreSQL:
#druid.metadata.storage.type=postgresql
#druid.metadata.storage.connector.connectURI=jdbc:postgresql://db.example.com:5432/druid
#druid.metadata.storage.connector.user=...
#druid.metadata.storage.connector.password=...
#
# Deep storage
#
# For local disk (only viable in a cluster if this is a network mount):
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
# For HDFS:
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
# For S3:
#druid.storage.type=s3
#druid.storage.bucket=your-bucket
#druid.storage.baseKey=druid/segments
#druid.s3.accessKey=...
#druid.s3.secretKey=...
#
# Indexing service logs
#
# For local disk (only viable in a cluster if this is a network mount):
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
# For HDFS:
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
# For S3:
#druid.indexer.logs.type=s3
#druid.indexer.logs.s3Bucket=your-bucket
#druid.indexer.logs.s3Prefix=druid/indexing-logs
#
# Service discovery
#
druid.selectors.indexing.serviceName=druid/overlord
druid.selectors.coordinator.serviceName=druid/coordinator
#
# Monitoring
#
druid.monitoring.monitors=["io.druid.java.util.metrics.JvmMonitor"]
druid.emitter=logging
druid.emitter.logging.logLevel=info
# Storage type of double columns
# ommiting this will lead to index double as float at the storage layer
druid.indexing.doubleStorage=double4. 复制HDFS配置文件
[[email protected] _common]$ cp core-site.xml /alidata/server/druid-0.12.1/conf/druid/_common/
[[email protected] _common]$ cp hdfs-site.xml /alidata/server/druid-0.12.1/conf/druid/_common/
[[email protected] _common]$ cp mapred-site.xml /alidata/server/druid-0.12.1/conf/druid/_common/
[[email protected] _common]$ cp yarn-site.xml /alidata/server/druid-0.12.1/conf/druid/_common/5.启用Druid SQL功能
[[email protected] broker]$ vi runtime.propertiesdruid.service=druid/broker
druid.host=172.16.XXX.XXX
druid.port=8082
# HTTP server threads
druid.broker.http.numConnections=5
druid.server.http.numThreads=9
# Processing threads and buffers
druid.processing.buffer.sizeBytes=256000000
druid.processing.numThreads=2
# Query cache (we use a small local cache)
druid.broker.cache.useCache=true
druid.broker.cache.populateCache=true
druid.cache.type=local
druid.cache.sizeInByte=2000000000
# enable druid sql and http
druid.sql.enable=true
druid.sql.avatica.enable=true
druid.sql.http.enable=true备注:broker、overlord、coordinator、historical、middleManager等目录下的runtime.properties新增属性druid.host=ipAddress
6. 更新MiddleManager任务执行数capacity
[email protected] middleManager]$ vi runtime.propertiesdruid.service=druid/middleManager
druid.host=172.16.XXX.XXX
druid.port=8091
# Number of tasks per middleManager
druid.worker.capacity=20
# Task launch parameters
druid.indexer.runner.javaOpts=-server -Xmx2g -Duser.timezone=UTC -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.indexer.task.baseTaskDir=var/druid/task
# HTTP server threads
druid.server.http.numThreads=9
# Processing threads and buffers on Peons
druid.indexer.fork.property.druid.processing.buffer.sizeBytes=256000000
druid.indexer.fork.property.druid.processing.numThreads=2
# Hadoop indexing
druid.indexer.task.hadoopWorkingPath=var/druid/hadoop-tmp
druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.7.3"]7. 升级Historical
[[email protected] druid-0.12.1]$ nohup >> nohuphistorical.out java `cat conf/druid/historical/jvm.config | xargs` -cp conf/druid/_common:conf/druid/historical:lib/* io.druid.cli.Main server historical &8. 升级Overlord
[[email protected] druid-0.12.1]$ nohup >> logs/nohupoverlord.out java `cat conf/druid/overlord/jvm.config | xargs` -cp conf/druid/_common:conf/druid/overlord:lib/* io.druid.cli.Main server overlord &9. 升级MiddleManager
- 禁止Overlor再向指定服务的MiddleManager分配任务
http://<MiddleManager_IP:PORT>/druid/worker/v1/disable- 查看指定MiddleManager任务列表
http://<MiddleManager_IP:PORT>/druid/worker/v1/tasks- 启动MiddleManager
[[email protected] druid-0.12.1]$ nohup >> logs/nohupmiddleManager.out java `cat conf/druid/middleManager/jvm.config | xargs` -cp conf/druid/_common:conf/druid/middleManager:lib/* io.druid.cli.Main server middleManager &- 启用Overlord向指定MiddleManager分配任务
http://<MiddleManager_IP:PORT>/druid/worker/v1/enable10. 升级Broker
[[email protected] druid-0.12.1]$ nohup >> nohupbroker.out java `cat conf/druid/broker/jvm.config | xargs` -cp conf/druid/_common:conf/druid/broker:lib/* io.druid.cli.Main server broker &11. 升级Coordinator
[[email protected] druid-0.12.1]$ nohup >> nohupcoordinator.out java `cat conf/druid/coordinator/jvm.config | xargs` -cp conf/druid/_common:conf/druid/coordinator:lib/* io.druid.cli.Main server coordinator &至此,Druid就完成从0.11.0版本升级到0.12.1版本。
以上是关于数据库升级的主要内容,如果未能解决你的问题,请参考以下文章