嵌入式软件开发 C语言笔试面试题
Posted WhyAndy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了嵌入式软件开发 C语言笔试面试题相关的知识,希望对你有一定的参考价值。
1. http://t.csdn.cn/o6ssf
2. http://t.csdn.cn/wY4tn
3. 笔试代码题:http://t.csdn.cn/texoz
问题:
B树每个节点关键字的个数:( ceil(m/2)-1,m-1)
子树的个数:(ceil(m/2),m)
嵌入式软件开发 笔试和面试笔记 (最近更新:2022-02-17)
参考博主:嵌入式与Linux那些事
目录
C/C++
1. 关键字
1.1 volatile 关键字
用volatile声明,该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中,让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
场景
- 多线程应用中被几个任务共享的变量
- 中断服务程序中用到的变量
- 并行设备的硬件寄存器
1.2 static
一般分为三种情况
- 在函数体内部定义变量:这个变量只会被初始化一次,并且在其它地方多次调用这个函数的时候,这个变量的值保持不变
- 在一个模块(一个.c文件) 定义的变量:可以被模块内部的所有函数访问,但是不能被外部模块访问,相当于属于本模块的全局变量
- 在模块内声明的函数:只能在本模块的范围内调用,外部不能调用
static声明的所有对象,都只初始化一次,并且会保存在内存区域,生命周期和程序周期一致。
1.3 extern “C”
- 主要作用是为了能正确实现C++代码调用C代码,加上这个关键字之后,会告诉编译器这段代码按照C的编译规则编译
1.4 const
一般分为3个作用
-
定义变量为常量:定义之后,变量的值不能修改(即赋值),所以定义的时候一定要初始化
-
修饰形参:表示函数体内部不能对形参加以修改
-
修饰返回值:只对指针有意义,如果给用const修饰返回值的类型为指针,那么函数返回值(即指针)的内容是不能被修改的,而且这个返回值只能赋给被const修饰的指针。(如果是修饰普通返回值,那么这个返回这也是一个临时变量,可以认为没有意义 )例如︰
const char getchar() char *str = getchar() //错误 const char *str = getchar //正确场景:变量、数组、对象、指针、引用、返回值、在另一链接文件中引用const常量
1.5 new \\delete malloc\\free
- new \\delete是C++的操作符, malloc\\free是C标准库函数
- 对于非内部数据对象来说,只使用malloc是无法完成动态对象要求的,一般在创建对象时需要调用构造函数,对象消亡时,自动的调用析构函数。而malloc free是库函数而不是运算符,不在编译器控制范围之内,不能够自动调用构造函数和析构函数。而NEW在为对象申请分配内存空间时,可以自动调用构造函数,同时也可以完成对对象的初始化。同理,delete也可以自动调用析构函数。而mallloc只是做一件事,只是为变量分配了内存,同理,free也只是释放变量的内存。
- new返回的是指定类型的指针,并且可以自动计算所申请内存的大小。而malloc需要我们计算申请内存的大小,并且在返回时强行转换为实际类型的指针。
1.6 strlen 和 sizeof
- sizeof是运算符(事实上,sizeof既是关键字,也是运算符,但不是函数),而strlen是函数。
- sizeof运算符的结果类型是size_t,它在头文件中typedef为unsigned int类型。该类型保证能够容纳实现所建立的最大对象的字节大小
- sizeof可以用类型作为参数,strlen只能用char*作参数,而且必须是以“0结尾的。sizeof还可以以函数作为参数,如int g ( ),则sizeof ( g( ) )的值等于sizeof ( int的值,在32位计算机下,该值为4。)
- 大部分编译程序的sizeof都是在编译的时候计算的,所以可以通过sizeof ( x )来定义数组维数。而strlen则是在运行期计算的,用来计算字符串的实际长度,不是类型占内存的大小。例如,charstr[20]= "0123456789”,字符数组str是编译期大小已经固定的数组,在32位机器下,为sizeof ( char ) *20=20,而其strlen大小则是在运行期确定的,所以其值为字符串的实际长度10。5.当数组作为参数传给函数时,传递的是指针,而不是数组,即传递的是数组的首地址。
- 不用sizeof求int字节数 #define Mysizeof(value) (char * )(&value+1)-(char*)&value
1.7 struct union
- 结构体与联合体虽然都是由多个不同的数据类型成员组成的,但不同之处在于联合体中所有成员共用一块地址空间,即联合体只存放了一个被选中的成员,而结构体中所有成员占用空间是累加的,其所有成员都存在,不同成员会存放在不同的地址。在计算一个结构型变量的总长度时,其内存空间大小等于所有成员长度之和(需要考虑字节对齐),而在联合体中,所有成员不能同时占用内存空间,它们不能同时存在,所以一个联合型变量的长度等于其最长的成员的长度。
- 对于联合体的不同成员赋值,
- 会对它的其他成员重写,原来成员的值就不存在了,而对结构体的不同成员赋值是互不影响的。
1.8 ++a a++
- 后置自增运算符需要把原来变量的值复制到一个临时的存储空间,等运算结束后才会返回这个临时变量的值。所以前置自增运算符效率比后置自增要高
1.9 define 和 typedef的区别
Typedef和define都可以用来给对象取一个别名,但是两者却有着很大不同。
- 首先,二者执行时间不同
关键字typedef在编译阶段有效,由于是在编译阶段,因此typedef有类型检查的功能。Define则是宏定义,发生在预处理阶段,也就是编译之前,它只进行简单而机械的字符串替换,而不进行任何检查
#define用法例子:
#define f(x) x*x
void main( )
int a=6,b=2,c;
c=f(a) / f(b);
printf("%d //n",c);
程序的输出结果是: 36,根本原因就在于#define只是简单的字符串替换。
- 功能不同
Typedef用来定义类型的别名,这些类型不只包含内部类型(int,char等),还包括自定义类型(如struct),可以起到使类型易于记忆的功能。
如: typedef int (*PF) (const char *, const char *);
定义一个指向函数的指针的数据类型PF,其中函数返回值为int,参数为const char *。
typedef 有另外一个重要的用途,那就是定义机器无关的类型,例如,你可以定义一个叫 REAL 的浮点类型,在目标机器上它可以i获得最高的精度:typedef long double REAL;
在不支持 long double 的机器上,该 typedef 看起来会是下面这样:typedef double REAL;
并且,在连 double 都不支持的机器上,该 typedef 看起来会是这样:typedef float REAL;
#define不只是可以为类型取别名,还可以定义常量、变量、编译开关等。
- 作用域不同
#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。
而typedef有自己的作用域。
void fun()
\\#define A int
void gun()
//在这里也可以使用A,因为宏替换没有作用域,
//但如果上面用的是typedef,那这里就不能用A ,不过一般不在函数内使用typedef
2 内存
2.1 分配方式
- 静态存储区分配:内存分配在程序编译之前完成,且在程序的整个运行期间都存在,例如全局变量、静态变量等。
- 栈上分配:在函数执行时,函数内的局部变量的存储单元在栈上创建,函数执行结束时这些存储单元自动释放。
- 堆上分配:
2.2 栈的作用
- 存储临时变量:形参、返回值
- 是多线程的基础,每个线程都会有独立的栈空间
- 中断 异常
2.3 压栈顺序
- 右–>左
2.4 C++的内存管理
在C++中,虚拟内存分为代码段、数据段、BSS段、堆区、文件映射区以及栈区六部分。
- 代码段︰包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。数据段∶存储程序中已初始化的全局变量和静态变量
- BSS段∶存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。
- 堆区︰调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。映射区:存储动态链接库以及调用mmap函数进行的文件映射
- 栈︰使用栈空间存储函数的返回地址、参数、局部变量、返回值
3. 指针
3.1 数组指针和指针数组的区别
- 数组指针就是指向数组的指针,它表示的是一个指针,这个指针指向的是一个数组,它重点是指针
#include <stdio.h>
#include <stdlib.h>
void main()
int b[12] = 1,2,3,4,5,6,7,8,9,10,11,12;
int (*p)[4];
p=b;
printf("%d\\n",**(++p));
程序的输出结果为5。
p是一个数组指针,它指向一个包含有4个int类型数组的指针,刚开始p被初始化为指向数组b的首地址并且占四个int的空间,++p相当于把p所指向的地址向后移动4个int所占用的空间,此时p指向数组(5,6,7,8),语句*(++p)﹔表示的是这个数组中第一个元素的地址(可以理解p为指向二维数组的指针, 1,2,3.4 , 5,6,7,8 , 9,10,11,12。p指向的就是 1,2,3,4的地址,*p就是指向元素, 1,2,3,4,[p指向的就是1),语句(++p )会输出这个数组的第一个元素5。
- 指针数组表示的是一个数组,而且数组中的每个元素都是一个指针
#include <stdio.h>
int main()
int i;
int *p[4];
int a[4] = 1,2,3,4;
p[0] = &a[0];
p[1] = &a[1];
p[2] = &a[2];
p[3] = &a[3];
for(i=0;i<4;i++)
printf("%d",*p[i]);
结果为1234
3.2 函数指针和指针函数的区别
-
函数指针:在程序编译的时候会为已经定义了的函数分配一段存储空间,这段存储空间的首地址称为函数的地址,地址名字可以表示这个地址,所以当一个指针指向它这个地址的时候,这个指针被称为函数指针
//函数指针的定义 int (*p)(int ,int);
解释:由于()的优先级比 * 的优先级要高,所以p先和结合,故p是一个指针,加上(int, int)就成为了函数指针,完整解释:定义了一个指针p,该指针变量可以指向返回值类型为int,两个int形参的函数,p的类型应该属于 int( * ) (int ,int),*p的两端括号不能省略,如果省略的话那么就是成为了一个返回值类型为指针型的函数 :int *p(int , int)
-
指针函数:一个返回值是地址的函数,函数返回子必须用同类型的指针变量来承接
int *pfunc(int.int); //等价于 int *(pfunc(int,int))
3.3 数组名和指针的区别和联系
- 数据保存方面:指针保存的是地址(保存的是目标数据地址,自身的地址是由编译器分配),内存访问的偏移量是四个字节,跟位数有关。数组名表示的是第一个元素的地址,内存偏移量是保存的元素数据类型的偏移量,只有对数据名取地址(&)的时候才表示整个数组,内存偏移量是整个数组大小 sizeof(数组名)
- 数据访问方面:指针对数据的访问是间接访问,需要用到解引用符号—>*数组名。数组对数据的访问是直接访问,通过下表访问数组名+元素偏移方式
- 使用场景:指针多用于动态数据结构,如链表;数组多用于存储固定个数且类型统一的数据结构。
3.4 指针常量、常量指针、指向常量的常量指针有什么区别
-
指针常量:就是一个指向固定地址的指针,不能修改这个指针的指向,但是指向的地址的内容可以修改
int * const p; -
常量指针:就是指向常量的指针,不能通过这个指针来修改指向的值
const int *p; int const *p; -
指向常量的常量指针:必须满足指针常量和常量指针的两个内容,也就是说不可以修改指针的指向,也不可以修改指针指向地址的内容
const int *const p;
3.5 指针的引用的区别? 怎么转换
-
相同点:都是地址,引用是某块内存的别名,引用的本质是指针常量,指向对象不能变,但是指向对象的值看一遍,两者都是地址,所以都会占用内存
-
区别:
- 指针是实体,引用是别名
- 对++符号的意义不一样,指针是指地址偏移,引用的表示对应值的递增
- 引用使用的时候无需解引用,指针需要解引用
- 引用不能为空,必须是具体对象的引用,指针可以是一个空指针
- sizeof计算引用的时候得到的是指向变量的大小,而指针一般是固定的大小,在32位系统中占4个字节
#include "stdio.h" int main() int x=10; int *p = &x; //指针 int &q = x; //q 是对x的引用, printf("%d",q) 的值就是x的值,不需要解引用符号 * printf("%d %d \\n",*p,sizeof(p)); printf("%d %d \\n",q,sizeof(q));
-
转化:
- 指针转引用:把指针用 * 就可以转化为对象,可以用在引用参数当中
- 引用转指针:把引用类型的对象用&取地址就可以得到指针。
3.6 指针的危险性
long * fellow;
*fellow = 223323;
fellow确实是一个指针,但是没有给这个指针赋予一个地址,所以这个指针将会被解释为存储值为223323的地址,如果这个时候我们的自己使用的变量用到的地址恰好是这个地址,那么这个时候就会出现难以调试的bug,因此,一定要在对指针进行解除引用运算符(*运算)之前,将指针初始化为一个确定的、适当的地址。
3.7 指针的递增递减操作
① 递增递减:
- i++:先引用i的值,再进行加一,++i:先加一再引用。
② 优先级:* 、++i、–i的优先级相同,从右到左结合,i++、i–优先级比上面的三个要高
③ 运算:
-
*++p:先进行p++,指针地址往后,再使用 * 获取对应地址的值
-
++*p:先获取当前p所指向地址的值,在将指针往后加一个单位的字节内存
-
(*p)++:括号优先级max,本质:对当前地址的实际值进行加一操作
-
*p++:++优先级max,本质:取p指向地址的下一个地址的值
3.8 野指针
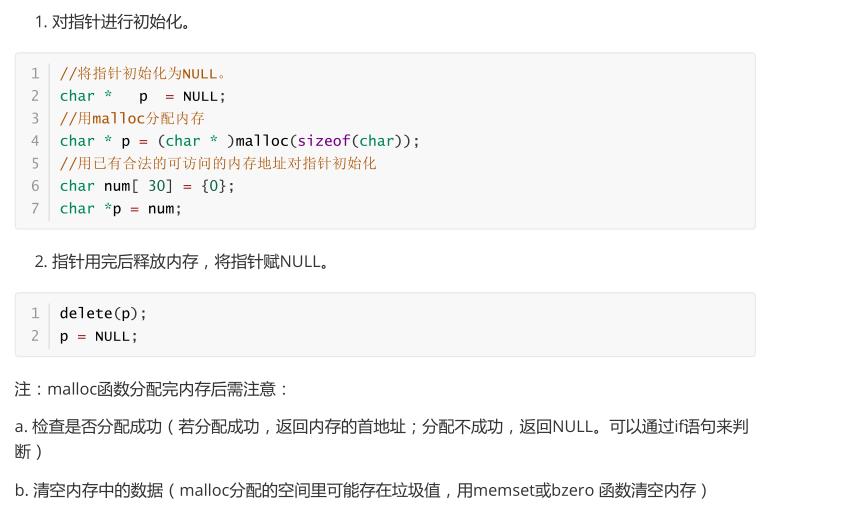
1.野指针是指向不可用内存的指针,当指针被创建时,指针不可能自动指向NULL,这时,默认值是随机的,此时的指针成为野指针。
2.当指针被free或delete释放掉时,如果没有把指针设置为NULL,则会产生野指针,因为释放掉的仅仅是指针指向的内存,并没有把指针本身释放掉。
3.第三个造成野指针的原因是指针操作超越了变量的作用范围。
避免野指针
3.9 什么是智能指针(待完成)
网络编程
1 . TCP UDP
1.1 TCP 保证可靠性
- 序列号、确认应答(ack)、超时重传(ARQ):数据到达接收方,接收方需要发出一个确认应答,表示已经收到该数据段,并且确认序号会说明了它下一次需要接收的数据序列号。如果发送发迟迟未收到确认应答,那么可能是发送的数据丢失,也可能是确认应答丢失,这时发送方在等待一定时间后会进行重传。这个时间一般是2*RTT(报文段往返时间)+一个偏差值。
- 窗口控制:TCP会利用窗口控制来提高传输速度,意思是在一个窗口大小内,不用一定要等到应答才能发送下一段数据,窗口大小就是无需等待确认而可以继续发送数据的最大值。如果不使用窗口控制,每一个没收到确认应答的数据都要重发。
使用窗口控制,如果数据段1001-2000丢失,后面数据每次传输,确认应答都会不停地发送序号为1001的应答,表示我要接收1001开始的数据,发送端如果收到3次相同应答,就会立刻进行重发;但还有种情况有可能是数据都收到了,但是有的应答丢失了,这种情况不会进行重发,因为发送端知道,如果是数据段丢失,接收端不会放过它的,会疯狂向它提醒
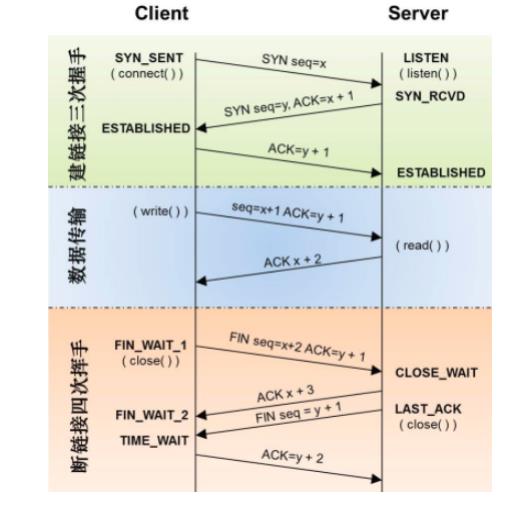
1.2 三次握手和四次挥手
-
三次握手:
-
Client将标志位SYN置为1,随机产生一个值seq=,并将该数据包发送给Server ,Client进入SYN_SENT状态,等待Server确认。
-
Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1 , ack=1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
-
Client收到确认后,检查ack是否为1,ACK是否为1,如果正确则将标志位ACK置为1 ,ack=K 1,并将该数据包发送给Server ,Server检查ack是否为K1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
-
-
四次挥手:
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭。
- 数据传输结束后,客户端的应用进程发出连接释放报文段,并停止发送数据,客户端进入FIN_WAIT_1状态,此时客户端依然可以接收服务器发送来的数据。
- 服务器接收到FIN后,发送一个ACK给客户端,确认序号为收到的序号1,服务器进入CLOSE_WAIT状态。客户端收到后进入FIN_WAIT_2状态。
- 当服务器没有数据要发送时,服务器发送一个FIN报文,此时服务器进入LAST_ACK状态,等待客户端的确认
- 客户端收到服务器的FIN报文后,给服务器发送一个ACK报文,确认序列号为收到的序号1。此时客户端进入TIME_WAIT状态,等待2MSL ( MSL∶报文段最大生存时间),然后关闭连接。
.1.3 TCP和UDP比较
-
1.TCP是面向连接的,UDP是面向无连接的
2.UDP程序结构较简单
3.TCP是面向字节流的,UDP是基于数据报的4.TCP保证数据正确性,UDP可能丢包
5.TCP保证数据顺序,UDP不保证 -
TCP优点:可靠,稳定TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。
-
TCP确定:慢,效率低,占用系统资源高,易被攻击TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。而且,因为TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
-
UDP优点:快,比TCP稍安全UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击。
-
UDP缺点:不可靠,不稳定因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
1.4 TCP和UDP适用场景
- TCP应用场景:效率要求相对低,但对准确性要求相对高的场景。因为传输中需要对数据确认、重发、排序等操作,相比之下效率没有UDP高。举几个例子︰文件传输(准确高要求高、但是速度可以相对慢)、接受邮件.远程登录。
- UDP应用场景:效率要求相对高,对准确性要求相对低的场景。举几个例子:QQ聊天、在线视频、网络语音电话(即时通讯,速度要求高,但是出现偶尔断续不是太大问题,并且此处完全不可以使用重发机制)、广播通信〔广福、多播).
2. socket
2.1 socket操作流程
- server: socket、bind、listen、accept
- client:socket、connect
2.2 TCP基本函数
- 创建socket,socket()
- 绑定IP、port,bind()
- 监听 listen
- 接收连接 accept
- 收发数据 send recv read和write
- close 关闭连接
2.3 UDP基本函数
1.服务器端流程
( 1 )、建立套接字文件描述符,使用函数socket(),生成套接字文件描述符。(2)、设置服务器地址和侦听端口,初始化要绑定的网络地址结构。
( 3 )、绑定侦听端口,使用bind()函数,将套接字文件描述符和一个地址类型变量进行绑定。( 4)、接收客户端的数据,使用recvfrom()函数接收客户端的网络数据。
( 5 )、向客户端发送数据,使用sendto()函数向服务器主机发送数据。(6)、关闭套接字,使用close()函数释放资源。UDP协议的客户端流程2客户端流程
( 1 )、建立套接字文件描述符,socket().
( 2)、设置服务器地址和端口,struct sockaddr。( 3)、向服务器发送数据,sendto()。
( 4)、接收服务器的数据,recvfrom().( 5)、关闭套接字,close()。
2.4 send 、recv、accept、socket
- send函数将要发送的数据从用户空间拷贝到TCP关联的内核发送缓冲区
- recv函数从TCP关联的内核接收缓冲区中取出数据到程序定义的缓冲区
- accept函数从连接队列里边儿取出已经成完成三次握手的连接
- socket函数返回一个用于网络通讯的文件描述符
ARM体系和架构
1. 通信协议
1.1 异步和同步
- 异步传输:是一种典型的基于字节的输入和输出,数据按照每一个字节进行传输,速率低
- 同步传输:需要外部时钟信号配合通信,把数据组合成帧的形式发送,速率快,全双工类型
同步异步最大得区别应该在于:同步中传输方和接受方使用同步时钟(即波特率是一样的,时序是一样的),而异步通讯允许双方使用各自不同的时钟。
1.2 SPI
SPI全称是串行外设接口,属于全双工工薪总线
- MOSI:master output,slave input,主机输出和从机输入
- MISO:master input,slave output,主机输入和从机输出
- SCLK:时钟线,由主机产生
- CS:chip select,片选脚,用于多个从机的情况下,IIC中用地址来找设备,SPI用CS来找设备

1.3 IIC
以上是关于嵌入式软件开发 C语言笔试面试题的主要内容,如果未能解决你的问题,请参考以下文章