gpu使用率一直是0?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gpu使用率一直是0?相关的知识,希望对你有一定的参考价值。
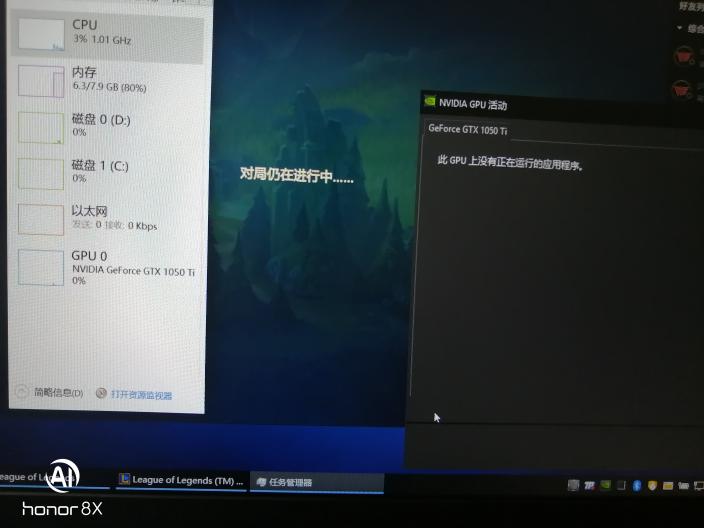
无论是打游戏还是跑分gpu使用率一直是0,驱动是官网下的,图三全局高性能已经开了还是没有用,谢谢大佬了
1、WIN7出问题认机器,解决办法从做系统;
2、可能由于病毒引起,解决办法下载杀毒软件,进行杀毒;
3、硬盘灯在亮,如果是就是虚拟内存设置太高了;
4、内存松动,重装内存条;
5、硬盘坏道太多,造成在电脑读写程序时,速度很慢,建议将硬盘低格,或者是主板坏了;
6、从新安装显卡,建议使用微软认证的或由官方发布的驱动,并且严格核对型号、版本;
CPU使用率其实就是你运行的程序占用的CPU资源,表示你的机器在某个时间点的运行程序的情况。使用率越高,说明你的机器在这个时间上运行了很多程序,反之较少。使用率的高低与你的CPU强弱有直接关系。现代分时多任务操作系统对 CPU 都是分时间片使用的:比如A进程占用10ms,然后B进程占用30ms,然后空闲60ms,再又是A进程占10ms,B进程占30ms,空闲60ms;如果在一段时间内都是如此,那么这段时间内的占用率为40%。CPU对线程的响应并不是连续的,通常会在一段时间后自动中断线程。未响应的线程增加,就会不断加大CPU的占用。cpu使用率高的原因有很多,但是一般都是由于病毒木马或开机启动项过多所致。高CPU使用率也可能表明应用程序的调整或设计不良。优化应用程序可以降低CPU的使用率。 参考技术A 回答
绝大部分的用户在正常情况下GPU使用率为0的话都是正常的现象,因为不使用的话是不会出现使用率的。但如果在使用的时候GPU的使用率一直为0的话,基本是都是驱动出现了问题,尝试重装驱动即可解决。其他因素:1、电脑在使用的途中可能受到了病毒的影响,下载杀毒软件进行杀毒即可。2、如果发现硬盘的灯再亮,就需要将虚拟内存设置的数值调低。
使用 OpenMP 将三重指针 (C) 卸载到 NVIDIA GPU
【中文标题】使用 OpenMP 将三重指针 (C) 卸载到 NVIDIA GPU【英文标题】:Perform a triple pointer (C) offloading to NVIDIA GPU with OpenMP 【发布时间】:2021-11-20 18:54:41 【问题描述】:我一直在使用传热代码。基本上,这段代码确定了立方体及其所有面的初始条件。这六个面从不同的温度开始,然后代码将计算由于它们之间的热传递而导致所有面的温度如何变化。现在,我一直在尝试使用 OpenMP 指令卸载到 NVIDIA GPU。此代码使用三重指针初始化面部条件,它是一种数组数组。读了一点关于这个问题,我开始知道 3D 架构不容易卸载到 GPU 上。所以我的问题是是否可以将这个三重指针数组卸载到 GPU,或者我是否必须使用更扁平的数组形式。
我留下代码,它仍在 CPU 上运行。代码的并行版本。
#include <omp.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 25 //This defines the number of points per dimension (Cube = N*N*N)
#define NUM_STEPS 6000 //This is the number of simulations time steps
/*writeFile: this function writes simulation results into a file.
* A file is created for each iteration that's passed to the function
* as a parameter. It also takes the triple pointer to the simulation
* data*/
void writeFile(int iteration, double*** data)
char filename[50];
char itr[12];
sprintf(itr, "%d", iteration);
strcpy(filename, "heat_");
strcat(filename, itr);
strcat(filename, ".txt");
//printf("Filename is %s\n", filename);
FILE *fp;
fp = fopen(filename, "w");
fprintf(fp, "x,y,z,T\n");
for(int i=0; i<N; i++)
for(int j=0;j<N; j++)
for(int k=0; k<N; k++)
fprintf(fp,"%d,%d,%d,%f\n", i,j,k,data[i][j][k]);
fclose(fp);
void compute_heat_transfer(double ***arrayOld, double ***arrayNew)
int i,j,k;
/*Compute steady-state solution*/
for(int nsteps=0; nsteps < NUM_STEPS; nsteps++)
/*if(nsteps % 100 == 0)
writeFile(nsteps, arrayOld);
*/
#pragma omp parallel shared(arrayNew, arrayOld) private(i,j,k)
#pragma omp for
for(i=1; i<N-1; i++)
for(j=1; j<N-1; j++)
for(k=1;k<N-1;k++)
//This is the 6-neighbor stencil computation
arrayNew[i][j][k] = (arrayOld[i-1][j][k] + arrayOld[i+1][j][k] + arrayOld[i][j-1][k] + arrayOld[i][j+1][k] +
arrayOld[i][j][k-1] + arrayOld[i][j][k+1])/6.0;
#pragma omp for
for(i=1; i<N-1; i++)
for(j=1; j<N-1; j++)
for(k=1; k<N-1; k++)
arrayOld[i][j][k] = arrayNew[i][j][k];
int main (int argc, char *argv[])
int i,j,k,nsteps;
double mean;
double ***arrayOld; //Variable that will hold the data of the past iteration
double ***arrayNew; //Variable where newly computed data will be stored
arrayOld = (double***)malloc(N*sizeof(double**));
arrayNew = (double***)malloc(N*sizeof(double**));
if(arrayOld== NULL)
fprintf(stderr, "Out of memory");
exit(0);
for(i=0; i<N;i++)
arrayOld[i] = (double**)malloc(N*sizeof(double*));
arrayNew[i] = (double**)malloc(N*sizeof(double*));
if(arrayOld[i]==NULL)
fprintf(stderr, "Out of memory");
exit(0);
for(int j=0;j<N;j++)
arrayOld[i][j] = (double*)malloc(N*sizeof(double));
arrayNew[i][j] = (double*)malloc(N*sizeof(double));
if(arrayOld[i][j]==NULL)
fprintf(stderr,"Out of memory");
exit(0);
/*Set boundary values and compute mean boundary values*/
mean = 0.0;
for(i=0; i<N; i++)
for(j=0;j<N;j++)
arrayOld[i][j][0] = 100.0;
mean += arrayOld[i][j][0];
for(i=0; i<N; i++)
for(j=0;j<N;j++)
arrayOld[i][j][N-1] = 100.0;
mean += arrayOld[i][j][N-1];
for(j=0; j<N; j++)
for(k=0;k<N;k++)
arrayOld[0][j][k] = 100.0;
mean += arrayOld[0][j][k];
for(j=0; j<N; j++)
for(k=0;k<N;k++)
arrayOld[N-1][j][k] = 100.0;
mean += arrayOld[N-1][j][k];
for(i=0; i<N; i++)
for(k=0;k<N;k++)
arrayOld[i][0][k] = 100.0;
mean += arrayOld[i][0][k];
for(i=0; i<N; i++)
for(k=0;k<N;k++)
arrayOld[i][N-1][k] = 0.0;
mean += arrayOld[i][N-1][k];
mean /= (6.0 * (N*N));
/*Initialize interior values*/
for(i=1; i<N-1; i++)
for(j=1; j<N-1; j++)
for(k=1; k<N-1;k++)
arrayOld[i][j][k] = mean;
double tdata = omp_get_wtime();
compute_heat_transfer(arrayOld, arrayNew);
tdata = omp_get_wtime()-tdata;
printf("Execution time was %f secs\n", tdata);
for(i=0; i<N;i++)
for(int j=0;j<N;j++)
free(arrayOld[i][j]);
free(arrayNew[i][j]);
free(arrayOld[i]);
free(arrayNew[i]);
free(arrayOld);
free(arrayNew);
return 0;
【问题讨论】:
【参考方案1】:使用具有动态存储的可变长度数组:
-
分配:
double (*arr)[N][N] = calloc(N, sizeof *arr);
索引。
使用旧的 arr[i][j][k] 语法
释放。
free(arr)
-
展平。
double *flat = (double*)arr;
请注意,C 标准不保证此转换能够正常工作。 尽管它很可能适用于所有能够使用 GPU 的平台。
-
传递给函数。
VLA 可以是函数的参数。
void fun(int n, double arr[n][n][n])
...
示例性用法是:
foo(N, arr);
编辑
compute_heat_transfer() 的 VLA 友好变体:
void compute_heat_transfer(int n, double arrayOld[restrict n][n][n], double arrayNew[restrict n][n][n])
int i,j,k;
/*Compute steady-state solution*/
for(int nsteps=0; nsteps < NUM_STEPS; nsteps++)
/*if(nsteps % 100 == 0)
writeFile(nsteps, arrayOld);
*/
#pragma omp parallel for collapse(3)
for(i=1; i<n-1; i++)
for(j=1; j<n-1; j++)
for(k=1; k<n-1; k++)
//This is the 6-neighbor stencil computation
arrayNew[i][j][k] = (arrayOld[i-1][j][k] + arrayOld[i+1][j][k] + arrayOld[i][j-1][k] + arrayOld[i][j+1][k] +
arrayOld[i][j][k-1] + arrayOld[i][j][k+1])/6.0;
#pragma omp parallel for collapse(3)
for(i=1; i<n-1; i++)
for(j=1; j<n-1; j++)
for(k=1; k<n-1; k++)
arrayOld[i][j][k] = arrayNew[i][j][k];
arrNew[restrict n][n][n] 中的关键字restrict 用于让编译器假定arrNew 和arrOld 没有别名。它应该让编译器使用更积极的优化。
请注意,arrNew 和 arrOld 是指向数组的指针。因此,与其将arrNew 复制到arrOld,不如简单地交换这些指针,形成一种简单的双缓冲。它应该使代码更快。
【讨论】:
感谢您的回答。所以,澄清一下,这种声明动态数组的方式将支持#pragma omp target enter data map 和#pragma omp target teams distribute parallel for,用于卸载到GPU?
@DrewHdz,以这种方式声明和分配的 3D 数组在内存中是平坦的,因此在传递给 GPU 时应该可以工作。我没有足够的经验使用 OpenMP 将工作分配到 GPU 以完全确定:/。可以将compute_heat_transfer() 的正文添加到问题中吗?
我在问题上添加了剩下的代码。这个版本的代码在 CPU 上运行,它是一个并行版本。看来这个平面数组是解决这个问题的方法。没有找到其他任何东西。
@DrewHdz,查看更新后的答案
谢谢,伙计。我将实现这一点,看看执行卸载时会发生什么。如果发生有趣的事情,我会及时通知您。以上是关于gpu使用率一直是0?的主要内容,如果未能解决你的问题,请参考以下文章