Java 并发JUC数据结构CopyOnWriteArrayList原理
Posted 酷酷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 并发JUC数据结构CopyOnWriteArrayList原理相关的知识,希望对你有一定的参考价值。
1 前言
我们前面看过了volatile、synchronized以及AQS的底层原理,以及基于AQS之上构建的各种并发工具,ReentrantLock、CountDownLatch、Semaphore、CyclicBarrier,那么我们这节该看什么了,是不是要看运用了。在日常的业务编程中经常使用到的内存数据结构有:Map、Set、List、Queue系列的数据结构,对应非线程安全的数据结构有,HashMap、HashSet、ArrayList、LinkedList、ArrayDeque等。这些内存的数据结构在多线程同时进行读写操作下并不是线程安全的,而JUC包下为我们提供了很多线程安全的Map、Set、List、Queue类型的数据结构。包括CopyOnWriteArrayList、ConcurrentLinkedQueue、ConcurrentHashMap、LinkedBlockingQueue、ArrayBlockingQueue、DelayQueue、SynchronousQueue等。这些并发安全的数据结构,就是我们接下来要看的。
这节我们就来看看CopyOnWriteArrayList的原理。
2 内部属性
先来看看CopyOnWriteArrayList,内部有哪些属性:
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable private static final long serialVersionUID = 8673264195747942595L; // 这个互斥可重入锁,用来保证多线程并发修改时候的线程安全 final transient ReentrantLock lock = new ReentrantLock(); // 使用volatile修饰的Object数组,数组是用来保存数据的 // 而volatile可以保证可见性和有序性,一旦array这个引用发生改变,其它线程立即可见 private transient volatile Object[] array; // 获取保存数据的底层数组引用 final Object[] getArray() return array; // 设置保存数据的底层数组 final void setArray(Object[] a) array = a;
上面就是CopyOnWriteArrayList 这个数据结构内部的属性,只有一个保存数据的Object数组,还有一个保证线程安全的ReentrantLock锁。接下来我们看看具体的方法动作是如何来保证并发的。
3 set方法
我们首先看一下set方法的内部实现,看看是怎么保证线程安全的。具体源码如下图所示:
public E set(int index, E element) // 这里首先获取内部的一个互斥锁 final ReentrantLock lock = this.lock; // 然后对互斥锁进行加锁,保证同一时间只有一个线程能对数据进行修改 lock.lock(); try // 获取内部保存数据的数组 Object[] elements = getArray(); // 根据index索引,获取修改前这个数组下标保存的旧值 E oldValue = get(elements, index); // 对比当前值和要修改后的值,如果不等则需要进行修改。 if (oldValue != element) // 获取当前数组的长度 int len = elements.length; // 注意这里,新复制一个新的数组newElements,数组内元素的值跟elements一样,长度一样。 Object[] newElements = Arrays.copyOf(elements, len); // 为新数组的index进行赋值,修改为新的值 newElements[index] = element; // 注意:这里将新的newElements数组赋值给CopyOnWriteArrayList内的array引用 // 由于使用了volatile修饰,保证可见性,所以这里一旦赋值成功,其它线程立马可见 setArray(newElements); else // 不做任何变化,还是赋值回原来的数组 setArray(elements); // 返回修改前的旧值 return oldValue; finally // 释放锁,让其它线程可以操作 lock.unlock();
上面的图的关键逻辑可以总结为以下几步:
(1)每次修改前都需要进行加锁,调用ReentrantLock.lock方法进行加锁,保证同一时间只有一个线程能进行修改操作
(2)获取内部保存数据的数组elements,直接根据要修改第几个元素获取到当前值oldValue;对比当前的值oldValue和要修改后的值element;如果oldValue == element,说明修改前后的值一样,无需进行修改了
(3)如果oldValue != element,这个时候则调用Arrays.of 方法复制一份一模一样的数据出来,修改新的数组的index位置的值为element(假如此时有别的线程在读取旧的数组元素,则是不影响的)
(4)修改完成之后,将新数组newElements赋值给引用array,由于array引用使用了volatile修饰,保证了可见性。所以一旦array引用指向的内存地址发生了改变,其它线程立马可见,之后使用的都是新的数组。
我们画个图来理解一下:
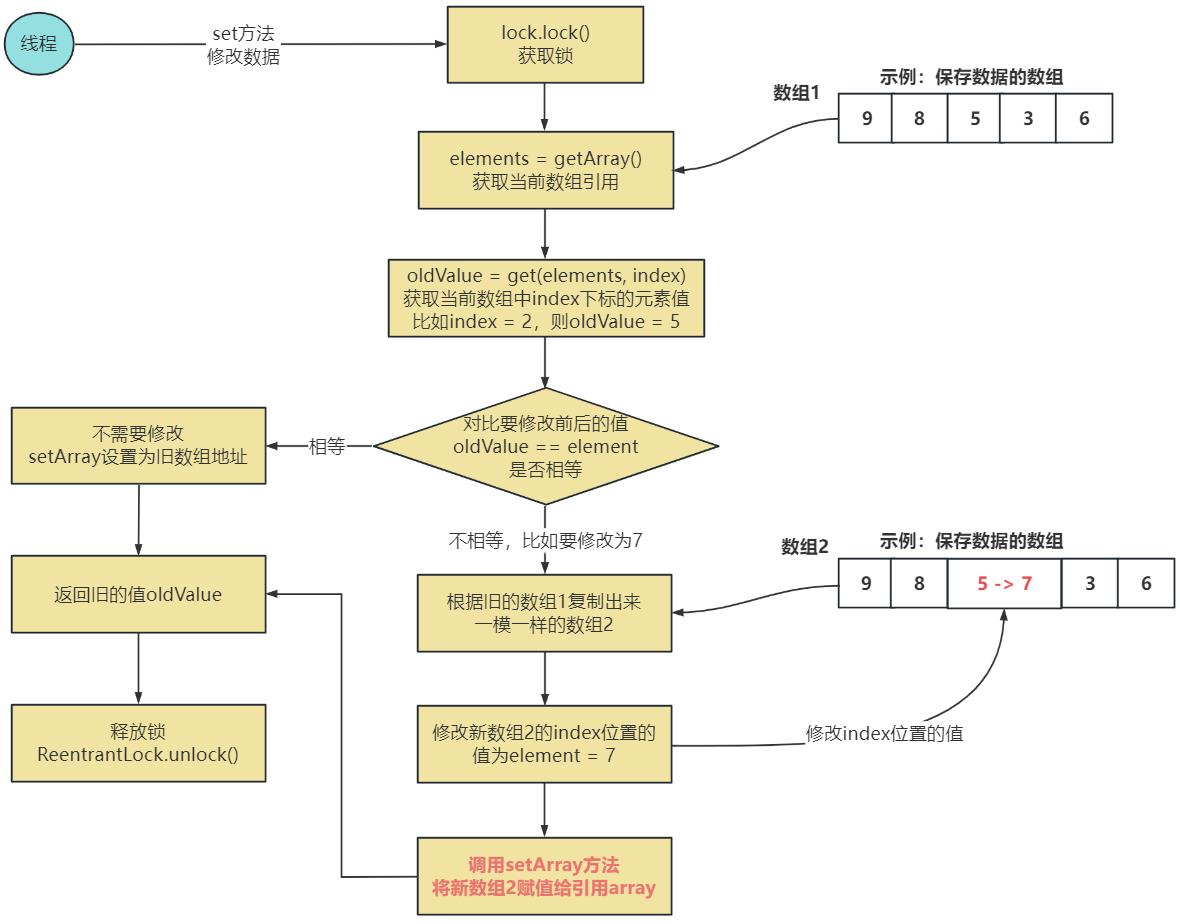
大致意思就是进行修改操作的时候:
(1)先进行加锁,如果修改的不相等然后复制一份一模一样的数据出来,此时内存里面就存在两份快照数据;这个时候要对新的数组元素进行修改,旧的不改变。
(2)当新的内存快照数据修改完成之后,就把调用setArray()方法,将数组的引用指向新的内存快照,由于使用了volatile修饰,一旦引用发生改变,其它线程立即可见,操作的就是新的数组了。
4 get方法
接下来我们继续,看一下get()方法的内部源码:
public E get(int index) return get(getArray(), index); // 直接根据返回的数组,以及获取数组元素的下标,直接取出 private E get(Object[] a, int index) return (E) a[index];
上面就是get方法的流程,与set方法不一样的是,这里get的时候无需进行加锁,就是直接取出数组某个位置的元素即可。
接下来,我们以4个线程为例(2个写2个读),画个图分析一下set和get多线程并发的场景,分析一下内部是怎么读取数据和修改数据的,图中的数字序号就表示发生的先后顺序。
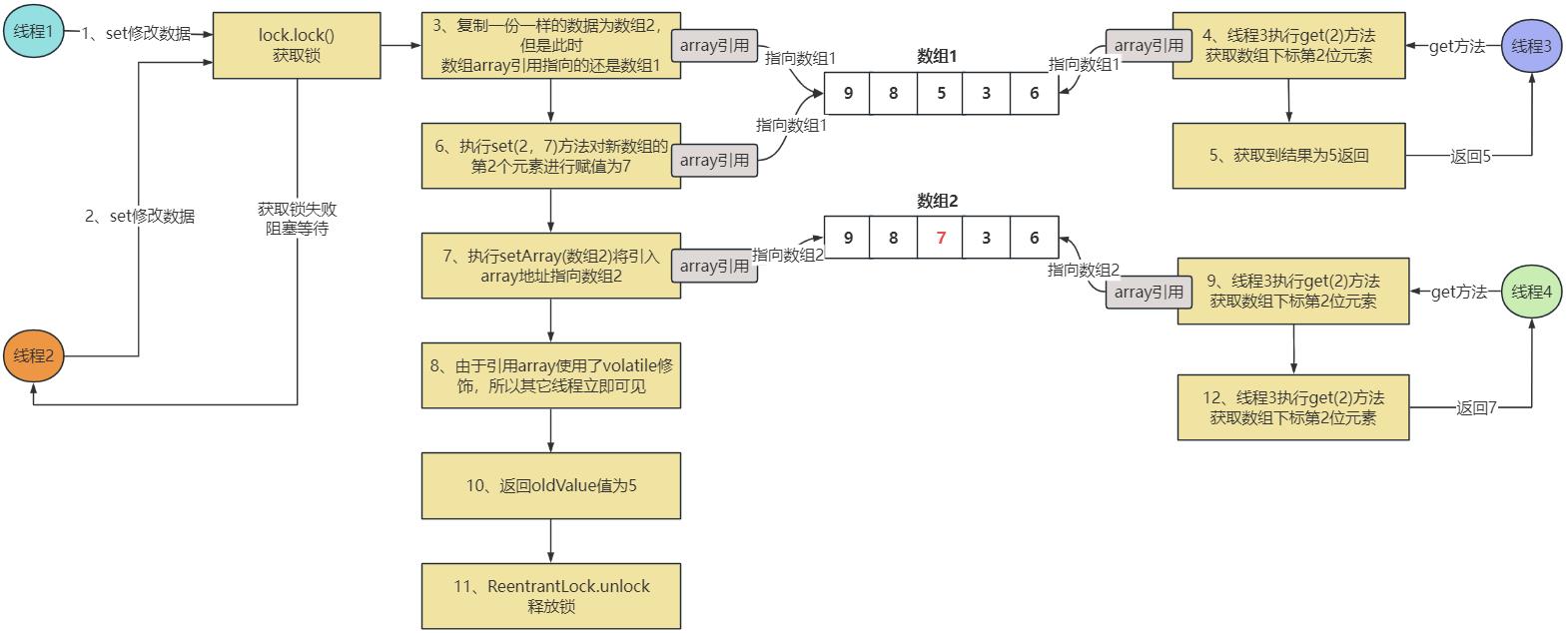
(1)线程1执行set方法,先调用ReentrantLock.lock方法进行加锁,这个时候线程2也调用ReentrantLock.lock方法,但是发现别人已经加锁了,这个时候线程2就会被阻塞住。
(2)线程1执行set(2,7)方法,要修改第二位的元素数据为7,复制出一个新的数组。但是同时线程3执行get(2)方法,由于数组的引用array指向的还是数组1,所以此时得到的值是5。
(3)线程1对复制出来的新数组进行修改,设置第2个元素的值为7,同时setArray(数组2)方法,将数组的引用array指向数组2。
(4)此时线程4执行get(2)方法,由于此时array引用已经指向了数组2,所以获取的是数组2的第2个元素,返回7
(5)线程1释放锁,返回结果
我们可以看到线程1在修改数据期间,线程3、线程4读取到的数据不一样,这样有问题吗?这个就是CopyOnWrite类型数据结构的特点了,这种数据结构其实就是牺牲了数据的强一致性,来换取读高并发。
每次修改的时候,都需要进行加锁,然后复制出一个副本出来进行修改,同时读数据操作不需要进行加锁,不会有任何阻塞;
一旦修改完成,将新的副本赋值给引用的时候,别的线程读取的时候就会立即读到新的副本内容,相当于是数据弱一致性的,牺牲了强一致性来换取读取的并发能力。
同时由于每次修改都要复制出来一份新的数据,空间开销很大;这种数据结构只适合在读多写少,同时要保证线程安全,不追求强一致性的情况。
它本身就是这么设计的,牺牲了内存空间、牺牲了数据的强一致性,来换取读取的并发提升。
5 add方法
接下来我们继续,看一下add()方法的内部源码:
public boolean add(E e) final ReentrantLock lock = this.lock; // 加锁 lock.lock(); try // 获取旧数组的引用 Object[] elements = getArray(); // 获取旧数组的长度 int len = elements.length; // 注意这里复制出一个新数组,新数组长度为旧数组长度 + 1 // 同时把旧数组0~length-1位的元素复制到新数组 Object[] newElements = Arrays.copyOf(elements, len + 1); // 新数组的length位元素存储新增的值e newElements[len] = e; // 新数组地址赋值给引用array setArray(newElements); return true; finally // 释放锁 lock.unlock();
6 remove方法
接下来我们继续,看一下remove()方法的内部源码:
public E remove(int index) final ReentrantLock lock = this.lock; // 加锁 lock.lock(); try // 获取旧数组的引用 Object[] elements = getArray(); // 获取旧数组长度 int len = elements.length; // 获取要删除的元素的值 E oldValue = get(elements, index); // 要移动的元素的个数 int numMoved = len - index - 1; // 如果numMove为0,表示要删除的元素在数组的最后一位 if (numMoved == 0) // 要删除的元素在数组的最后一位,直接将0~len-2位复制跟新数组即可 setArray(Arrays.copyOf(elements, len - 1)); else // 新数组长度为len-1 Object[] newElements = new Object[len - 1]; // 旧数组的0~index-1位元素复制给新数组 System.arraycopy(elements, 0, newElements, 0, index); // 旧数组的index + 1 ~ len -1 位元素复制给新数组 System.arraycopy(elements, index + 1, newElements, index, numMoved); // 将新数组的地址赋值给引用 setArray(newElements); return oldValue; finally // 释放锁 lock.unlock();
上面的两个add、remove方法跟之前画图讲解的set方法源码原理基本是一样的,都是修改数据前进行加锁、然后复制出一个新的数组进行操作。不同的只是复制的元素长度不一样而已,这里就不再画图讲解了。
add方法只是复制出一个新的数组,长度比旧数组多1,然后在数组末尾放入这个新的元素。
remove方法这里就是将0~index -1、index + 1 ~ len -1 位置的元素复制给新数组而已。
7 小结
好了,本节我们CopyOnWriteArrayList就了解到这里就结束了哈,有理解不对的地方欢迎指正哈。
Java并发编程系列之三JUC概述
以上是关于Java 并发JUC数据结构CopyOnWriteArrayList原理的主要内容,如果未能解决你的问题,请参考以下文章