python:re模块
Posted 112226
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python:re模块相关的知识,希望对你有一定的参考价值。
主要是学习re模块的使用,正则表达式的学习...我都看了,就是运用少,所以没记住什么,用到的时候,还得翻我手工记录的正则笔记.....如果是爬取网页,可以用bs4模块,这个更方便,只是正则很强大(~ ̄▽ ̄)~
看的下面这个文章做得笔记
re.compile(pattern[, flag])
功能:生成一个正则表达式对象
pattern为要编译的正则表达式,flag为下图中的标志位。
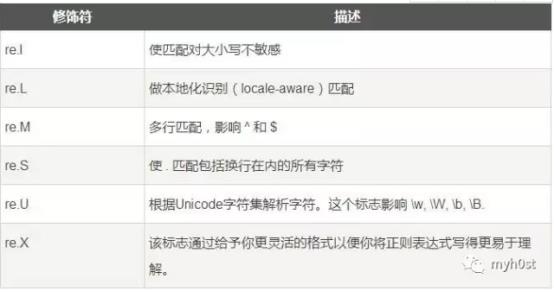
match(string[, pos[, endpos]])
参数解释:string为匹配用的原始字符串,pos为文本中正则表达式开始搜索的索引,endpos文本中正则表达式结束搜索的索引
使用match函数成功后会返回一个对象,该对象包含一下功能:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
>>> str = "qwe123asd" >>> import re >>> pattern = re.compile(\'[a-z]+\') >>> obj = pattern.match(str)
search(string[, pos[, endpos]])
为一次匹配,如果匹配成功返回一个match对象,如果不成功则返回None
findall(string[, pos[, endpos]])
参数解释:string为匹配用的原始字符串,pos为文本中正则表达式开始搜索的索引,endpos文本中正则表达式结束搜索的索引
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
finditer(string[, pos[, endpos]])
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回的是一个match的对象。
split(string[, maxsplit])
maxsplit 用于指定最大分割次数,不指定将全部分割。(python有个内置方法也是split)
sub(repl, string[, count])
repl可以是字符串也可以是函数,string为匹配用的原始字符串, count 用于指定最多替换次数,不指定时全部替换。
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
sub函数返回替换后的字符串。
主要是repl为函数需要注意
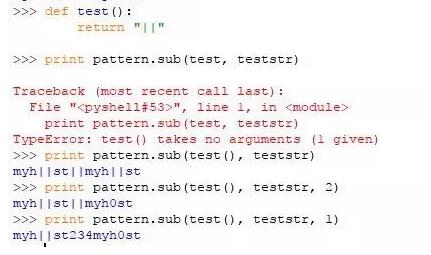
subn(repl, string[, count])
参数与sub的参数一致
subn返回一个元组,第一个元素是使用sub方法的结果,一个是替换的次数
在不使用compile的时候,只需要将函数前面加re.以及第一个参数为正则表达式即可,例如:re.search("\\d", "myh0st")
以上是关于python:re模块的主要内容,如果未能解决你的问题,请参考以下文章