python:requests模块
Posted 112226
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python:requests模块相关的知识,希望对你有一定的参考价值。
requests模块是我在学习爬虫时学到的一个模块,它的api比较简单好用,这里简介下使用方法。
其实这个很好使用,几行代码就可以获取一个网页的内容:
import requests url = \'http://www.juzimi.com/ju/252304\' response = requests.get(url) print (response.text)
它支持很多http请求类型:get,post,put,delete,head,options
其中获取的响应内容有2中显示方法
.content 以字节的方式显示,中文显示为字符
.text 以文本的方式显示,放两张图就能明白了
这是content

这是text
Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。
可以通过.encoding 查看requests使用了什么编码
也可以手动改变其使用的编码r.encoding= ‘gbk2312’
Get请求可以传递参数
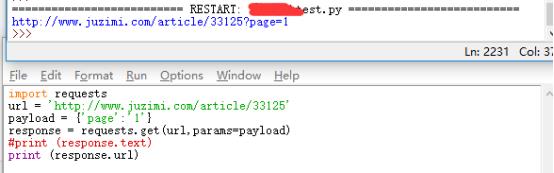
import requests
url = \'http://www.juzimi.com/article/33125\'
payload = {\'page\':\'1\'}
response = requests.get(url,params=payload)
print (response.text)
可以打印.url,查看构造后的url
定制请求头部
传一个dict给heads参数
headers = {\'user-agent\': \'my-app/0.0.1\'}
r = requests.get(url, headers=headers)
发送post请求
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
r = requests.post("http://httpbin.org/post", data=payload)
get方法还有一个cookies参数
timeout参数
访问代理
proxies = { "http": "http://10.10.10.10:8888", "https": "http://10.10.10.100:4444", } r = requests.get(\'http://m.ctrip.com\', proxies=proxies)
以上是关于python:requests模块的主要内容,如果未能解决你的问题,请参考以下文章