Python 卡方检验
Posted KK——数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 卡方检验相关的知识,希望对你有一定的参考价值。
卡方检验是一种用途很广的计数资料的假设检验方法。它属于非参数检验的范畴,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。(更多参考:卡方检验、卡方分布)
不讲过多理论,主要使用 python 实现卡方验证。之前对于元素/特征/属性 异常值的选择情况,可以使用直方图、箱型图、Z分数法等筛选。如 Python 探索性数据分析(Exploratory Data Analysis,EDA) ,数据探索的同时,也可以排除单个变量的异常值。而对于离散属性(或离散化)的分类,可以使用 等距分类、等频分类 等,但是这样分类不能体现出与其他属性或结果的相关性。
当前则使用卡方验证来将属性分类。如客户的婚姻情况对于贷款后是否回款还是有影响的,所以当前校验离散值怎么分类更好。现在有一组数据,客户的“婚姻情况”,更复杂点计算的话,“婚姻+年龄+性别” 相互作用还是比较强的,可同时将这几个变量计算。此处只是有 婚姻情况测试。这些数据是历史数据,有点客户已经回款,有的未回款。
但是这些数据哪些是异常值,这些异常值是删除,还是归到其他类中呢?
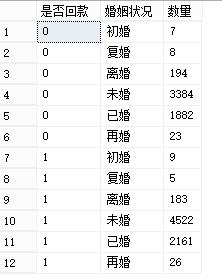
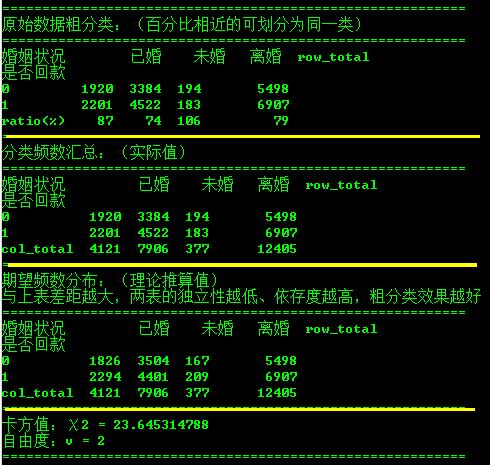
首先进行粗分类,观测他们的占比情况:
表1,基于客户婚姻情况的粗分类

比值较近的可以划分为同一类,如把 “再婚” 归为 “已婚” ,“初婚” 归为 “未婚” 。这时机器的算法,当然我们可以评经验来分类 ,“再婚”、“初婚” 、“复婚” 其实都属于“已婚”。
表2,该表格为各婚姻情况客户是否回款的频数
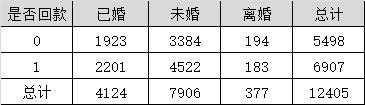
每个类别都是相互独立,没有交叉的,现在用另一种方法计算。假设是否回款的客户的分布与总体保持一致。计算“已婚未回款的客户数” = 4124x5498/12405 = 1826(以所在行列的汇总值计算),最终结果如下:
表3,该表格为各婚姻情况客户是否回款的期望频数分布(理论推算值)
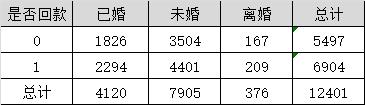
两个表的数字差距越大,两个表的独立性越强,就表示两个表的依赖度越高、粗分类结果越好。现在使用计算卡方距离:
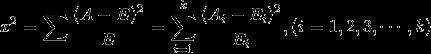
Ai为i水平的实际的观察频数,Ei为i水平的期望频数。代入公式:
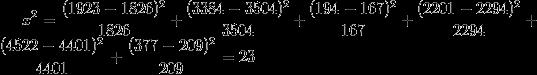
这就是卡方值,再计算卡方的 自由度 v:
v=(行数-1)(列数-1)=(2-1)(3-1) = 2
表4,卡方临界值表部分数据

卡方临界值 为 (一般取 p=0.05):
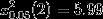
该临界值小于实验中的卡方值 23,差异明显,拒绝0假设。
克雷姆值(Cramer\'sV):
克雷姆值是通过卡方值计算出来的公式如下:
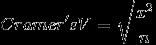
其中,n 是数据集中的观测值个数,克雷姆值总是在区间 [0,1]中,值越大表示变量的预测能力越高。根据经验,通常去克雷姆值大于 0.1 的变量,或者取前 10% 的变量。 对于相同的特征属性, IV值和克雷姆值的判别结果通常是一致的。(参考 WOE、VI 分类变量预测能力)
卡方值验证,使用 python 脚本实现:
# -*- coding: UTF-8 -*- # python 3.5.0 # 卡方计算 __author__ = \'HZC\' import math import sqlalchemy import numpy as np import pandas as pd class CHISQUARE: def __init__(self,d): self.engine = sqlalchemy.create_engine("mssql+pymssql://%s:%s@%s/%s" %(d[\'user\'],d[\'pwd\'],d[\'ins\'],d[\'db\'])) def get_df_from_query(self,sql): df = pd.read_sql_query(sql, self.engine) return df def get_variance(self,df): row_count = df.shape[0]-1 col_count = df.shape[1]-1 v = (row_count-1)*(col_count-1) return v #转为矩阵求卡方距离 def get_chi_square_value(self,df1,df2): df1 = df1.drop([\'col_total\']) df2 = df2.drop([\'col_total\']) del df1[\'row_total\'] del df2[\'row_total\'] mtr1 = df1.astype(int).as_matrix() mtr2 = df2.astype(int).as_matrix() mtr = ((mtr1-mtr2)**2)/mtr2 return mtr.sum() #分类频数 def get_classification(self,table_name,col_result,col_pred): sql = "select %s,%s from %s" % (col_result,col_pred,table_name) df = self.get_df_from_query(sql) df = df.groupby([col_result,col_pred]).agg({col_result:[\'count\']}) df = df.reset_index() df.columns = [col_result,col_pred, \'count\'] df = pd.pivot_table(df, values = \'count\', index=col_result, columns = col_pred).reset_index() df[\'row_total\'] = df.sum(axis=1) df.set_index(col_result, inplace=True) df.loc[\'ratio(%)\'] = df.loc[0]*100/df.loc[1] print("==========================================================") print("原始数据粗分类:(百分比相近的可划分为同一类)") print("==========================================================") print(df.astype(int)) df = df.drop([\'ratio(%)\']) df.loc[\'col_total\']=df.sum(axis=0) print("==========================================================") print("分类频数汇总:(实际值)") print("==========================================================") print(df.astype(int)) df2 = df.copy() total = df2[[\'row_total\']].loc[[\'col_total\']].values[0][0] for col in df2: df2[col] = df2[[col]].loc[[\'col_total\']].values[0][0] * df2[\'row_total\']/total df2 = df2.drop([\'col_total\']) df2.loc[\'col_total\']=df2.sum(axis=0) print("==========================================================") print("期望频数分布:(理论推算值)") print("与上表差距越大,两表的独立性越低、依存度越高,粗分类效果越好") print("==========================================================") print(df2.astype(int)) print("==========================================================") x = self.get_chi_square_value(df,df2)#顺序:(实际df,推算df) v = self.get_variance(df2) # v=(行数-1)(列数-1) print("卡方值:χ2 = %s" % x) print("自由度:v = %s" % v) print("==========================================================") if __name__ == "__main__": conn = {\'user\':\'用户名\',\'pwd\':\'密码\',\'ins\':\'实例\',\'db\':\'数据库\'} cs = CHISQUARE(conn) cs.get_classification("V_ClientInfoAll","是否回款","婚姻状况") #cs.get_classification(表或视图,回归只/判断值,"分类元素")
只可分析两个变量之间的关系值,输出结果如下:
以上是关于Python 卡方检验的主要内容,如果未能解决你的问题,请参考以下文章