Python爬虫下载美女图片(不同网站不同方法)
Posted Vrapile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫下载美女图片(不同网站不同方法)相关的知识,希望对你有一定的参考价值。
声明:以下代码,Python版本3.6完美运行,但因网站日新月异,下面代码可能在有些网站已不适用,读者朋友理解思路就好
一、思路介绍
不同的图片网站设有不同的反爬虫机制,根据具体网站采取对应的方法
1. 浏览器浏览分析地址变化规律
2. Python测试类获取网页内容,从而获取图片地址
3. Python测试类下载图片,保存成功则爬虫可以实现
二、豆瓣美女(难度:❤)
1. 网址:https://www.dbmeinv.com/dbgroup/show.htm
浏览器里点击后,按分类和页数得到新的地址:"https://www.dbmeinv.com/dbgroup/show.htm?cid=%s&pager_offset=%s" % (cid, index)
(其中cid:2-胸 3-腿 4-脸 5-杂 6-臀 7-袜子 index:页数)
2. 通过python调用,查看获取网页内容,以下是Test_Url.py的内容
1 from urllib import request
2 import re
3 from bs4 import BeautifulSoup
4
5
6 def get_html(url):
7 req = request.Request(url)
8 return request.urlopen(req).read()
9
10
11 if __name__ == \'__main__\':
12 url = "https://www.dbmeinv.com/dbgroup/show.htm?cid=2&pager_offset=2"
13 html = get_html(url)
14 data = BeautifulSoup(html, "lxml")
15 print(data)
16 r = r\'(https://\\S+\\.jpg)\'
17 p = re.compile(r)
18 get_list = re.findall(p, str(data))
19 print(get_list)
通过urllib.request.Request(Url)请求网站,BeautifulSoup解析返回的二进制内容,re.findall()匹配图片地址
最终print(get_list)打印出了图片地址的一个列表
3. 通过python调用,下载图片,以下是Test_Down.py的内容
1 from urllib import request
2
3
4 def get_image(url):
5 req = request.Request(url)
6 get_img = request.urlopen(req).read()
7 with open(\'E:/Python_Doc/Images/DownTest/001.jpg\', \'wb\') as fp:
8 fp.write(get_img)
9 print("Download success!")
10 return
11
12
13 if __name__ == \'__main__\':
14 url = "https://ww2.sinaimg.cn/bmiddle/0060lm7Tgy1fn1cmtxkrcj30dw09a0u3.jpg"
15 get_image(url)
通过urllib.request.Request(image_url)获取图片,然后写入本地,看到路径下多了一张图片,说明整个爬虫实现是可实现的
4. 综合上面分析,写出完整爬虫代码 douban_spider.py


1 from urllib import request 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 import os 5 import time 6 import re 7 import threading 8 9 10 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 11 # 图片地址 12 picpath = r\'E:\\Python_Doc\\Images\' 13 # 豆瓣地址 14 douban_url = "https://www.dbmeinv.com/dbgroup/show.htm?cid=%s&pager_offset=%s" 15 16 17 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 # 获取html内容 26 def get_html(url): 27 req = request.Request(url) 28 return request.urlopen(req).read() 29 30 31 # 获取图片地址 32 def get_ImageUrl(html): 33 data = BeautifulSoup(html, "lxml") 34 r = r\'(https://\\S+\\.jpg)\' 35 p = re.compile(r) 36 return re.findall(p, str(data)) 37 38 39 # 保存图片 40 def save_image(savepath, url): 41 content = urlopen(url).read() 42 # url[-11:] 表示截取原图片后面11位 43 with open(savepath + \'/\' + url[-11:], \'wb\') as code: 44 code.write(content) 45 46 47 def do_task(savepath, cid, index): 48 url = douban_url % (cid, index) 49 html = get_html(url) 50 image_list = get_ImageUrl(html) 51 # 此处判断其实意义不大,程序基本都是人手动终止的,因为图片你是下不完的 52 if not image_list: 53 print(u\'已经全部抓取完毕\') 54 return 55 # 实时查看,这个有必要 56 print("=============================================================================") 57 print(u\'开始抓取Cid= %s 第 %s 页\' % (cid, index)) 58 for image in image_list: 59 save_image(savepath, image) 60 # 抓取下一页 61 do_task(savepath, cid, index+1) 62 63 64 if __name__ == \'__main__\': 65 # 文件名 66 filename = "DouBan" 67 filepath = setpath(filename) 68 69 # 2-胸 3-腿 4-脸 5-杂 6-臀 7-袜子 70 for i in range(2, 8): 71 do_task(filepath, i, 1) 72 73 # threads = [] 74 # for i in range(2, 4): 75 # ti = threading.Thread(target=do_task, args=(filepath, i, 1, )) 76 # threads.append(ti) 77 # for t in threads: 78 # t.setDaemon(True) 79 # t.start() 80 # t.join()
运行程序,进入文件夹查看,图片已经不停的写入电脑了!
5. 分析:豆瓣图片下载用比较简单的爬虫就能实现,网站唯一的控制好像只有不能频繁调用,所以豆瓣不适合用多线程调用
豆瓣还有一个地址:https://www.dbmeinv.com/dbgroup/current.htm有兴趣的读者朋友可以自己去研究
三、MM131网(难度:❤❤)
1. 网址:http://www.mm131.com
浏览器里点击后,按分类和页数得到新的地址:"http://www.mm131.com/xinggan/list_6_%s.html" % index
(如果清纯:"http://www.mm131.com/qingchun/list_1_%s.html" % index , index:页数)
2. Test_Url.py,双重循化先获取图片人物地址,在获取人物每页的图片
1 from urllib import request
2 import re
3 from bs4 import BeautifulSoup
4
5
6 def get_html(url):
7 req = request.Request(url)
8 return request.urlopen(req).read()
9
10
11 if __name__ == \'__main__\':
12 url = "http://www.mm131.com/xinggan/list_6_2.html"
13 html = get_html(url)
14 data = BeautifulSoup(html, "lxml")
15 p = r"(http://www\\S*/\\d{4}\\.html)"
16 get_list = re.findall(p, str(data))
17 # 循化人物地址
18 for i in range(20):
19 # print(get_list[i])
20 # 循环人物的N页图片
21 for j in range(200):
22 url2 = get_list[i][:-5] + "_" + str(j + 2) + ".html"
23 try:
24 html2 = get_html(url2)
25 except:
26 break
27 p = r"(http://\\S*/\\d{4}\\S*\\.jpg)"
28 get_list2 = re.findall(p, str(html2))
29 print(get_list2[0])
30 break
3. 下载图片 Test_Down.py,用豆瓣下载的方法下载,发现不论下载多少张,都是一样的下面图片

这个就有点尴尬了,妹子图片地址都有了,就是不能下载,浏览器打开的时候也是时好时坏,网上也找不到原因,当然楼主最终还是找到原因了,下面先贴上代码
1 from urllib import request
2 import requests
3
4
5 def get_image(url):
6 req = request.Request(url)
7 get_img = request.urlopen(req).read()
8 with open(\'E:/Python_Doc/Images/DownTest/123.jpg\', \'wb\') as fp:
9 fp.write(get_img)
10 print("Download success!")
11 return
12
13
14 def get_image2(url_ref, url):
15 headers = {"Referer": url_ref,
16 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 \'
17 \'(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36\'}
18 content = requests.get(url, headers=headers)
19 if content.status_code == 200:
20 with open(\'E:/Python_Doc/Images/DownTest/124.jpg\', \'wb\') as f:
21 for chunk in content:
22 f.write(chunk)
23 print("Download success!")
24
25
26 if __name__ == \'__main__\':
27 url_ref = "http://www.mm131.com/xinggan/2343_3.html"
28 url = "http://img1.mm131.me/pic/2343/3.jpg"
29 get_image2(url_ref, url)
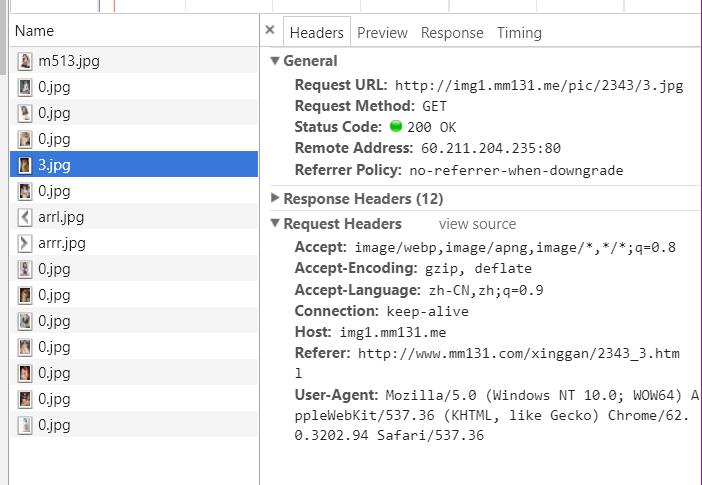
可以看到下载成功,改用requests.get方法获取图片内容,这种请求方法方便设置头文件headers(urllib.request怎么设置headers没有研究过),headers里面有个Referer参数,必须设置为此图片的进入地址,从浏览器F12代码可以看出来,如下图
4. 测试都通过了,下面是汇总的完整源码
1 from urllib import request 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 import os 5 import time 6 import re 7 import requests 8 9 10 # 全局声明的可以写到配置文件,这里为了读者方便看,故只写在一个文件里面 11 # 图片地址 12 picpath = r\'E:\\Python_Doc\\Images\' 13 # mm131地址 14 mm_url = "http://www.mm131.com/xinggan/list_6_%s.html" 15 16 17 # 保存路径的文件夹,没有则自己创建文件夹,不能创建上级文件夹 18 def setpath(name): 19 path = os.path.join(picpath, name) 20 if not os.path.isdir(path): 21 os.mkdir(path) 22 return path 23 24 25 # 获取html内容 26 def get_html(url): 27 req = request.Request(url) 28 return request.urlopen(req).read() 29 30 31 def save_image2(path, url_ref, url): 32 headers = {"Referer": url_ref, 33 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 \' 34 \'(KHTML, like Gecko)Chrome/62.0.3202.94 Safari/537.36\'} 35 content = requests.get(url, headers=headers) 36 if content.status_code == 200: 37 with open(path + \'/\' + str(time.time()) + \'.jpg\', \'wb\') as f: 38 for chunk in content: 39 f.write(chunk) 40 41 42 def do_task(path, url): 43 html = get_html(url) 44 data = BeautifulSoup(html, "lxml") 45 p = r"(http://www\\S*/\\d{1,5}\\.html)" 46 get_list = re.findall(p, str(data)) 47 # print(data) 48 # 循化人物地址 每页20个 49 for i in range(20): 50 try: 51 print(get_list[i]) 52 except: 53 break 54 # 循环人物的N页图片 55 for j in range(200): 56 url2 = get_list[i][:-5] + "_" + str(3*j + 2) + ".html" 57 try: 58 html2 = get_html(url2) 59 except: 60 break 61 p = r"(http://\\S*/\\d{1,4}\\S*\\.jpg)" 62 get_list2 = re.findall(p, str(html2)) 63 save_image2(path, get_list[i], get_list2[0]) 64 65 66 if __name__ == \'__main__\': 67 # 文件名 68 filename = "MM131_XG" 69 filepath = setpath(filename) 70 71 for i in range(2, 100): 72 print("正在List_6_%s " % i) 73 url = mm_url % i 74 do_task(filepath, url)
运行程序后,图片将源源不断的写入电脑
5. 分析:MM131图片下载主要问题是保存图片的时候需要用headers设置Referer
四、煎蛋网(难度:❤❤❤)
1. 网址:http://jandan.net/ooxx
浏览器里点击后,按分类和页数得到新的地址:http://jandan.net/ooxx/page-%s#comments % index
(index:页数)
2. Test_Url.py,由于通过urllib.request.Request会被拒绝
通过requests添加headers,返回的html文本如下
1 ......
2 <div class="text">
3 <span class="righttext">
4 <a href="//jandan.net/ooxx/page-2#comment-3535967">3535967</a>
5 </span>
6 <p>
7 <img src="//img.jandan.net/img/blank.gif" onload="jandan_load_img(this)" />
8 <span class="img-hash">d0c4TroufRLv8KcPl0CZWwEuhv3ZTfJrTVr02gQHSmnFyf0tWbjze3F+DoWRsMEJFYpWSXTd5YfOrmma+1CKquxniG2C19Gzh81OF3wz84m8TSGr1pXRIA</span>
9 </p>
10 </div>
11 ......
从上面关键结果可以看到,<span class="img-hash">后面的一长串哈希字符才是图片地址,网站打开时候动态转换为图片地址显示的,不过上有政策,下有对策,那就把这些hash字符串转为图片地址了,怎么转呢? 以下提供两种方案
(1)通过Python的execjs模块直接调用JS里面的函数,将这个hash转为图片地址,具体实现就是把当前网页保存下来,然后找到里面的js转换方法函数,单独拎出来写在一个JS里面
调用的JS和方法如下:OOXX1.js CallJS.python
1 function OOXX1(a,b) {
2 return md5(a)
3 }
4 function md5(a) {
5 return "Success" + a
6 }
1 import execjs
2
3
4 # 执行本地的js
5 def get_js():
6 f = open("OOXX1.js", \'r\', encoding=\'UTF-8\')
7 line = f.readline()
8 htmlstr = \'\'
9 while line:
10 htmlstr = htmlstr + line
11 line = f.readline()
12 return htmlstr
13
14
15 js = get_js()
16 ctx = execjs.compile(js)
17 ss = "SS"
18 cc = "CC"
19 print(ctx.call("OOXX1", ss, cc))
此种方法只提供思路,楼主找到的JS如下 OOXX.js,实际调用报错了,这个方法应该会比方法二速度快很多,所以还是贴上未完成代码供读者朋友参阅研究
1 function time() { 2 var a = new Date().getTime(); 3 return parseInt(a / 1000) 4 } 5 function microtime(b) { 6 var a = new Date().getTime(); 7 var c = parseInt(a / 1000); 8 return b ? (a / 1000) : (a - (c * 1000)) / 1000 + " " + c 9 } 10 function chr(a) { 11 return String.fromCharCode(a) 12 } 13 function ord(a) { 14 return a.charCodeAt() 15 } 16 function md5(a) { 17 return hex_md5(a) 18 } 19 function base64_encode(a) { 20 return btoa(a) 21 } 22 function base64_decode(a) { 23 return atob(a) 24 } (function(g) { 25 function o(u, z) { 26 var w = (u & 65535) + (z & 65535), 27 v = (u >> 16) + (z >> 16) + (w >> 16); 28 return (v << 16) | (w & 65535) 29 } 30 function s(u, v) { 31 return (u << v) | (u >>> (32 - v)) 32 } 33 function c(A, w, v, u, z, y) { 34 return o(s(o(o(w, A), o(u, y)), z), v) 35 } 36 function b(w, v, B, A, u, z, y) { 37 return c((v & B) | ((~v) & A), w, v, u, z, y) 38 } 39 function i(w, v, B, A, u, z, y) { 40 return c((v & A) | (B & (~A)), w, v, u, z, y) 41 } 42 function n(w, v, B, A, u, z, y) { 43 return c(v ^ B ^ A, w, v, u, z, y) 44 } 45 function a(w, v, B, A, u, z, y) { 46 return c(B ^ (v | (~A)), w, v, u, z, y) 47 } 48 function d(F, A) { 49 F[A >> 5] |= 128 << (A % 32); 50 F[(((A + 64) >>> 9) << 4) + 14] = A; 51 var w, z, y, v, u, E = 1732584193, 52 D = -271733879, 53 C = -1732584194, 54 B = 271733878; 55 for (w = 0; w < F.length; w += 16) { 56 z = E; 57 y = D; 58 v = C; 59 u = B; 60 E = b(E, D, C, B, F[w], 7, -680876936); 61 B = b(B, E, D, C, F[w + 1], 12, -389564586); 62 C = b(C, B, E, D, F[w + 2], 17, 606105819); 63 D = b(D, C, B, E, F[w + 3], 22, -1044525330); 64 E = b(E, D, C, B, F[w + 4], 7, -176418897); 65 B = b(B, E, D, C, F[w + 5], 12, 1200080426); 66 C = b(C, B, E, D, F[w + 6], 17, -1473231341); 67 D = b(D, C, B, E, F[w + 7], 22, -45705983); 68 E = b(E, D, C, B, F[w + 8], 7, 1770035416); 69 B = b(B, E, D, C, F[w + 9], 12, -1958414417); 70 C = b(C, B, E, D, F[w + 10], 17, -42063); 71 D = b(D, C, B, E, F[w + 11], 22, -1990404162); 72 E = b(E, D, C, B, F[w + 12], 7, 1804603682); 73 B = b(B, E, D, C, F[w + 13], 12, -40341101); 74 C = b(C, B, E, D, F[w + 14], 17, -1502002290); 75 D = b(D, C, B, E, F[w + 15], 22, 1236535329); 76 E = i(E, D, C, B, F[w + 1], 5, -165796510); 77 B = i(B, E, D, C, F[w + 6], 9, -1069501632); 78 C = i(C, B, E, D, F[w + 11], 14, 643717713); 79 D = i(D, C, B, E, F[w], 20, -373897302); 80 E = i(E, D, C, B, F[w + 5], 5, -701558691); 81 B = i(B, E, D, C, F[w + 10], 9, 38016083); 82 C = i(C, B, E, D, F[w + 15], 14, -660478335); 83 D = i(D, C, B, E, F[w + 4], 20, -405537848); 84 E = i(E, D, C, B, F[w + 9], 5, 568446438); 85 B = i(B, E, D, C, F[w + 14], 9, -1019803690); 86 C = i(C, B, E, D, F[w + 3], 14, -187363961); 87 D = i(D, C, B, E, F[w + 8], 20, 1163531501); 88 E = i(E, D, C, B, F[w + 13], 5, -1444681467); 89 B = i(B, E, D, C, F[w + 2], 9, -51403784); 90 C = i(C, B, E, D, F[w + 7], 14, 1735328473); 91 D = i(D, C, B, E, F[w + 12], 20, -1926607734); 92 E = n(E, D, C, B, F[w + 5], 4, -378558); 93 B = n(B, E, D, C, F[w + 8], 11, -2022574463); 94 C = n(C, B, E, D, F[w + 11], 16, 1839030562); 95 D = n(D, C, B, E, F[w + 14], 23, -35309556); 96 E = n(E, D, C, B, F[w + 1], 4, -1530992060); 97 B = n(B, E, D, C, F[w + 4], 11, 1272893353); 98 C = n(C, B, E, D, F[w + 7], 16, -155497632); 99 D = n(D, C, B, E, F[w + 10], 23, -1094730640); 100 E = n(E, D, C, B, F[w + 13], 4, 681279174); 101 B = n(B, E, D, C, F[w], 11, -358537222); 102 C = n(C, B, E, D, F[w + 3], 16, -722521979); 103 D = n(D, C, B, E, F[w + 6], 23, 76029189); 104 E = n(E, D, C, B, F[w + 9], 4, -640364487); 105 B = n(B, E, D, C, F[w + 12], 11, -421815835); 106 C = n(C, B, E, D, F[w + 15], 16, 530742520); 107 D = n(D, C, B, E, F[w + 2], 23, -995338651); 108 E = a(E, D, C, B, F[w], 6, -198630844); 109 B = a(B, E, D, C, F[w + 7], 10, 1126891415); 110 C = a(C, B, E, D, F[w + 14], 15, -1416354905); 111 D = a(D, C, B, E, F[w + 5], 21, -57434055); 112 E = a(E, D, C, B, F[w + 12], 6, 1700485571); 113 B = a(B, E, D, C, F[w + 3], 10, -1894986606); 114 C = a(C, B, E, D, F[w + 10], 15, -1051523); 115 D = a(D, C, B, E, F[w + 1], 21, -2054922799); 116 E = a(E, D, C, B, F[w + 8], 6, 1873313359); 117 B = a(B, E, D, C, F[w + 15], 10, -30611744); 118 C = a(C, B, E, D, F[w + 6], 15, -1560198380); 119 D = a(D, C, B, E, F[w + 13], 21, 1309151649); 120 E = a(E, D, C, B, F[w + 4], 6, -145523070); 121 B = a(B, E, D, C, F[w + 11], 10, -1120210379); 122 C = a(C, B, E, D, F[w + 2], 15, 718787259); 123 D = a(D, C, B, E, F[w + 9], 21, -343485551); 124 E = o(E, z); 125 D = o(D, y); 126 C = o(C, v); 127 B = o(B, u) 128 } 129 return [E, D, C, B] 130 } 131 function p(v) { 132 var w, u = ""; 133 for (w = 0; w < v.length * 32; w += 8) { 134 u += String.fromCharCode((v[w >> 5] >>> (w % 32)) & 255) 135 } 136 return u 137 } 138 function j(v) { 139 var w, u = []; 140 u[(v.length >> 2) - 1] = undefined; 141 for (w = 0; w < u.length; w += 1) { 142 u[w] = 0 143 } 144 for (w = 0; w < v.length * 8; w += 8) { 145 u[w >> 5] |= (v.charCodeAt(w / 8) & 255) << (w % 32) 146 } 147 return u 148 } 149 function k(u) { 150 return p(d(j(u), u.length * 8)) 151 } 152 function e(w, z) { 153 var v, y = j(w), 154 u = [], 155 x = [], 156 A; 157 u[15] = x[15] = undefined; 158 if (y.length > 16) { 159 y = d(y, w.length * 8) 160 } 161 for (v = 0; v < 16; v += 1) { 162 u[v] = y[v] ^ 909522486; 163 x[v] = y[v] ^ 1549556828 164 } 165 A = d(u.concat(j(z)), 512 + z.length * 8); 166 return p(d(x.concat(A), 512 + 128)) 167 } 168 function t(w) { 169 var z = "0123456789abcdef", 170 v = "", 171 u, y; 172 for (y = 0; y < w.length; y += 1) { 173 u = w.charCodeAt(y); 174 v += z.charAt((u >>> 4) & 15) + z.charAt(u & 15) 175 } 176 return v 177 } 178 function m(u) { 179 return unescape(encodeURIComponent(u)) 180 } 181 function q(u) { 182 return k(m(u)) 183以上是关于Python爬虫下载美女图片(不同网站不同方法)的主要内容,如果未能解决你的问题,请参考以下文章