网络爬虫实现原理与实现技术
网络爬虫实现原理详解
通用网络爬虫
实现原理及过程
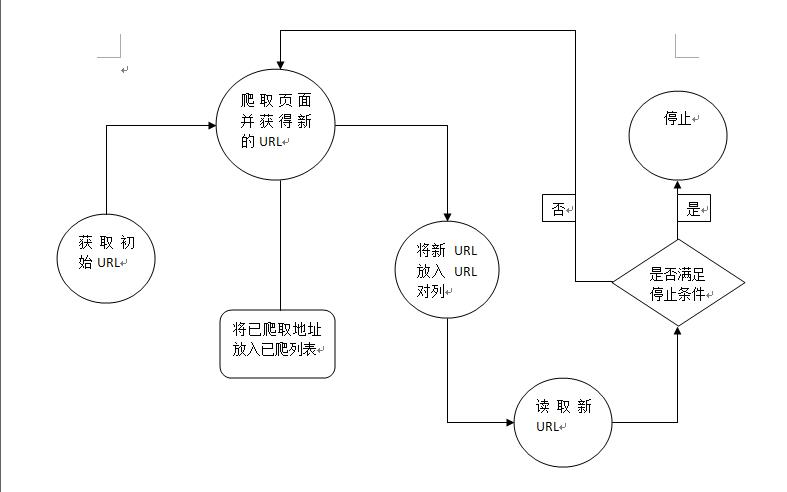
1. 获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2. 根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬行对应URL地址中的网页,爬取了对方的URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存放在一个URL列表中,用于去重及判断爬取的进程。
3. 将新的URL放到URL队列中。在第二步中,获取了下一个新的URL地址之后,会将新的URL地址放到URL队列中。
4. 从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取新的URL,并重复上述的爬取过程。
5. 满足爬虫系统设置的停止条件是,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫则会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足是停止爬取。
聚焦网络爬虫
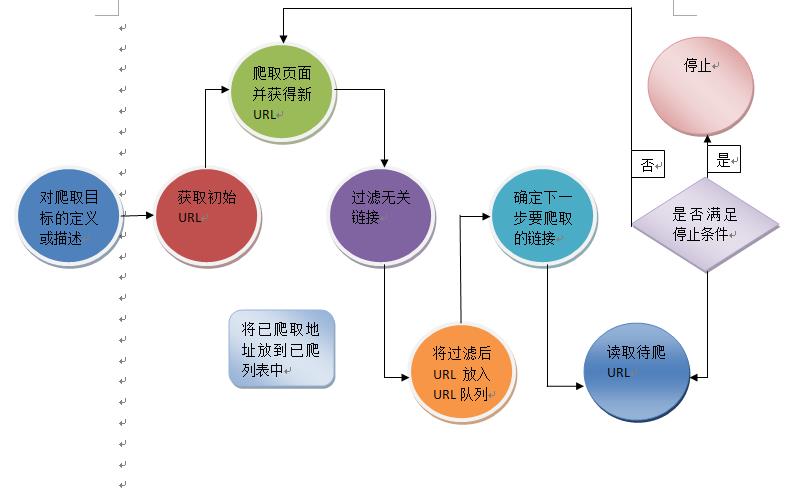
1. 对爬取目标的定义和描述。在聚焦网络爬虫中,我们首先要依据爬取需求定义该聚焦网络爬虫爬取的目标,以及进行相关的描述。
2. 获取初始的URL。
3. 根据初始的URL爬取页面,并获得新的URL
4. 从新的URL中过滤掉与爬取目标无关的链接。因为聚焦网络爬虫对网页的爬取室友目的性的,所以与目标无关的网页将会被过滤掉。同时,也需要将已爬取的URL地址存放到一个URL列表总,用于去重和判断爬取的进程。
5. 将过滤后的链接放到URL队列中。
6. 从URL队列中,根据搜索算法,确定URL的优先级,并确定下一步要爬取的URL地址。在通用网络爬虫中,下一步爬取那些URL地址,是不太重要的,但是在聚焦网络爬虫中,由于其目的性,故而下一步爬取哪些URL地址相对来说是比较重要的。对于聚焦网络爬虫来说,不同的爬取顺序,可能导致爬虫的执行效率不同,所以,我们需要依据搜索策略来确定下一步需要爬取哪些URL地址。
7. 从下一步要爬取的URL地址中,读取新的URL,然后依据新的URL地址爬取网页,并重复上述爬取过程。
8. 满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。
爬行策略
爬行策略主要有,深度优先爬行策略,广度优先爬行策略、大站优先策略、反链策略、其他爬行策略等。
深度广度很好理解。从大站优先开始。
我们可以对应网站所属的站点进行归类,如果某个网站的网页数量多,那么我们则将其称为大站,按照这种策略,网页数量越多的网站越大,然后优先爬取大站中的网页URL地址。
一个网页的反向链接数,指的是该网页被其他网页指向的次数,这个次数在一定程度张代表着该网页被其他网页的推荐次数。所以,如果按反链策略去爬行的话,那么哪个网页的反链数量越多,则哪个网页将被优先爬取。但是,在实际情况中,如果单纯按反链策略去决定一个网页的优先程度的话,那么可能会出现大量的作弊情况。比如,做一些垃圾站群,并将这些网站互相链接,如果这样的话,每个站点都将获得较高的反链,从而达到作弊的目的。作为爬虫项目方,我们当然不希望收到这种作弊行为的干扰,所以,如果采用反向链接策略去爬取的话,一般会考虑可靠的反链数。
其他爬行策略,OPIC策略,Partial PageRank策略。
网页更新策略
网页更新策略主要有3种:用户体验策略、历史数据策略、聚类分析策略等。
1. 用户体验策略
在搜索引擎查询关键词时,会出现一个排名结果,通常会有大量的网页,大部分用户只关心排名靠前的网页。所以在爬虫服务器资源有限的情况下,爬虫会优先更新排名靠前的网页,这种更新策略就叫用户体验策略,爬取周期的确定,爬取中会保留对应网页的多个历史版本,并进行分析,依据多个历史版本的内容更新、搜索质量的影响、用户体验等信息,来确定对这些网页的爬取周期。
2. 历史数据策略
我们可以依据某一个网页的历史更新数据,通过泊松过程进行建模等手段,预测该网页下一次更新的时间,从而确定下一次改网页的爬取的时间,即确定更新周期。
3.聚类分析策略
聚类分析就是根据网页的共有属性进行分类
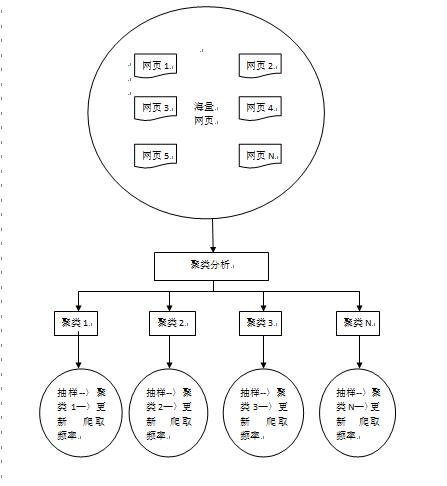
以上两种策略都需要历史数据进行分析,若一个网页为新网页,则不会有对应的历史数据。并且,如果要依据历史数据进行分析,则需要爬虫服务器保存对应网页的历史版本信息,给服务器带来更多的压力和负担。所以这时候我们就用聚类分析策略。
1. 首先,经过大量的研究发现,网页可能具有不同的内容,但是一般来说,具有类似属性的网页,其更新频率类似。这是聚类分析算法运用在爬虫网页的更新上的一个前提指导思想。
2. 有了1中的指导思想后,我们可以首先对海量的网页进行聚类分析,在聚类分析之后会形成多个类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。
3. 聚类完成后,我们可以对同一个聚类中的网页进行抽样,然后求该抽样结果的平均更新至,从而确定每个聚类的爬行频率。
网页分析算法
搜索引擎的网页分析算法主要分为3类:
1. 基于用户行为的网页分析算法
依据用户对这些网页的访问行为,对这些网页进行评价,比如,依据用户对该网页的访问频率、用户对网页的访问时长、用户的单击率等信息对网页进行综合评价。
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是依靠网页的链接关系、结构关系、已知网页或数据等对网页进行分析的一种算法。基于网络拓扑的网页分析算法,同样可以细分为3种类型:基于网页粒度的分析算法、基于网页块粒度的分析算法、基于网站粒度的分析算法。
PageRank算法是一种比较典型的基于网页粒度的分析算法。他会根据网页之间的链接关系对网页的权重进行计算,并可以依靠这些计算出来的权重,对网页进行排名。HITS算法也是基于网页粒度的分析算法。
基于网页块粒度的分析算法,也是依靠网页间链接关系进行计算的,但计算规则不同。一个网页中通常会包含多个超链接,但一般其指向的外部链接中并不是所有的链接都与网站主题有关,或者说,这些外部链接对该网页的重要程度是不一样的,所以若要基于网页块粒度进行分析,则需要对一个网页中的这些外部链接划分层次,不同层次的外部链接对于该网页来说,其重要程度不同。这种算法的分析效率和准确率,会比传统的算法好一些。
基于网站粒度的分析算法,业与PageRank算法类似,但是,如果采用基于网站粒度进行分析,相应的,会使用SiteRank算法。即此时我们会划分站点的层次和等级,而不再具体地计算站点下的各个网页的等级。所以其相对于基于网页粒度的算法来说,则更加简单高效,精度却没有网页粒度分析算法好。
3. 基于网页内容的网页分析算法
依据网页的数据、文本等网页内容特征,对网页进行相应的评价。
身份识别
正规的爬虫会告知站长其爬虫身份,网站的管理员也可以对其爬虫身份进行识别。
一般的,爬虫在爬取访问网页的时候,会通过HTTP请求中的User Agant字段告知自己的身份信息。爬虫访问网站,首先会根据站点下的Robots.txt文件来确定可爬取的网页范围,Robots协议是需要网络爬虫共同遵守的协议,对于一些禁止的URL地址,网络爬虫则不应该爬取访问。同时,如果爬虫在爬取某一个站点时陷入死循环,造成该站点的服务压力过大,如果有正确的身份设置,那么该站点的站长则可以想办法联系爬虫方,然后停止对应的爬虫程序。
当然,有些爬虫会伪装成其他爬虫或浏览器去爬取网站,以获取额外一些数据,或者有些爬虫,会无视Robots协议的限制而任意爬取。这些行为我们不提倡。