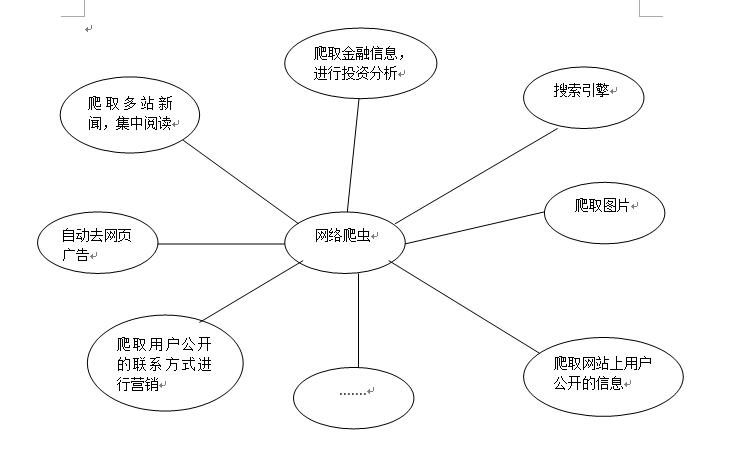
网络爬虫技能总览
网络爬虫技能总览图
搜索引擎核心
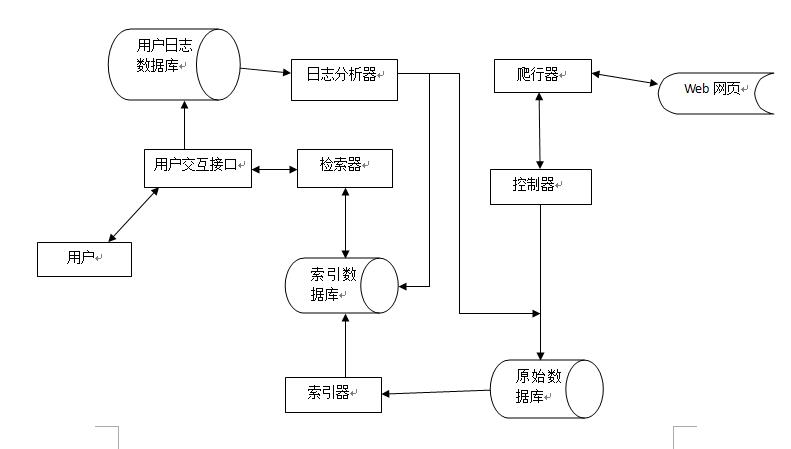
首先,搜索引擎会利用爬虫模块去爬取互联网中的网页,然后将爬取到的网页存储在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并存储到索引数据库中。
当用户检索信息的时候,会通过用户交互接口输入对应的信息,用户交互皆苦相当于搜索引擎的输入框,输入完成之后,有所引起进行分词等操作,检索器会索引数据库中获取数据进行相应的检索处理。
用户输入对应的信息的同时,会将用户的行为存储到用户日志数据库中,比如用户的IP地址、用户输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志分析器会根据大量的用户数据去调整原始数据库和索引数据库,改变排名结果或进行其他操作。
索引和检索的区分
检索是一种行为,索引是一种属性。比如一家超市,对商品的分组,分类就是索引,而查找商品的过程就是检索。有一个好的索引可以提升效率。