Python 分词及词云绘图
Posted KK——数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 分词及词云绘图相关的知识,希望对你有一定的参考价值。
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
关键词:HMM 隐马尔可夫模型
三种分词模式:
# -*- coding: utf-8 -*- import jieba #jieba.initialize() seg_list = jieba.cut("中华人民共和国万岁!", cut_all=False) #精确模式(默认) print(" | ".join(seg_list)) seg_list = jieba.cut("中华人民共和国万岁!", cut_all=True) #全模式 print(" | ".join(seg_list)) seg_list = jieba.cut_for_search("中华人民共和国万岁!") #搜索引擎模式 print(" | ".join(seg_list))
结果:
中华人民共和国 | 万岁 | !
中华 | 中华人民 | 中华人民共和国 | 华人 | 人民 | 人民共和国 | 共和 | 共和国 | 万岁 | |
中华 | 华人 | 人民 | 共和 | 共和国 | 中华人民共和国 | 万岁 | !
结果可以直接保持为 list
seg_list = jieba.cut("中华人民共和国万岁!") #默认精确模式 print(seg_list) #此返回生成器 seg_list = jieba.lcut("中华人民共和国万岁!") print(seg_list) seg_list = jieba.lcut_for_search ("中华人民共和国万岁!") print(seg_list)
结果:
<generator object Tokenizer.cut at 0x0000000003972150>
[\'中华人民共和国\', \'万岁\', \'!\']
[\'中华\', \'华人\', \'人民\', \'共和\', \'共和国\', \'中华人民共和国\', \'万岁\', \'!\']
【自定义分词字典(属额外添加)】
默认分词器为 jieba.dt。可使用自定义字典,添加词库中没有的词,文本必须为 UTF-8 编码。词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开。
测试文件 dict.txt 中,我只添加一个单词 "和国":
jieba.load_userdict("C:/Users/huangzecheng/Desktop/dict.txt") seg_list = jieba.cut("中华人民共和国万岁!", cut_all=True)#如全模式 print(" | ".join(seg_list))
结果:
中华 | 中华人民 | 中华人民共和国 | 华人 | 人民 | 人民共和国 | 共和 | 共和国 | 和国 | 万岁 | |
【添加删除分词】
加载的自定义词典,是与默认的一起定义分词的。也可以使用几个函数添加、删除、禁止某个词被划分。
add_word(word, freq=None, tag=None)
del_word(word)
suggest_freq(segment, tune=True)
jieba.add_word(\'中华人\') print(" | ".join(jieba.cut("中华人民共和国万岁!", cut_all=True))) 结果:中华 | 中华人 | 中华人民 | 中华人民共和国 | 华人 | 人民 | 人民共和国 | 共和 | 共和国 | 和国 | 万岁 | | jieba.del_word(\'共和\') print(" | ".join(jieba.cut("中华人民共和国万岁!", cut_all=True))) 结果:中华 | 中华人 | 中华人民 | 中华人民共和国 | 华人 | 人民 | 人民共和国 | 共和国 | 和国 | 万岁 | | jieba.add_word(\'共和\') jieba.suggest_freq(\'国万岁\', tune=True) print(" | ".join(jieba.cut("中华人民共和国万岁!", cut_all=True))) 结果:中华 | 中华人 | 中华人民 | 中华人民共和国 | 华人 | 人民 | 人民共和国 | 共和国 | 和国 | 国万岁 | 万岁 | |
【使用最多的分词】
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence :为待提取的文本
topK :为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight :为是否一并返回关键词权重值,默认值为 False
allowPOS :仅包括指定词性的词,默认值为空,即不筛选
测试:去文本中出现次数最多的前5个字符
str = "topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20;" str = str + "withWeight 为是否一并返回关键词权重值,默认值为 False" str = str + "allowPOS 仅包括指定词性的词,默认值为空,即不筛选" str = str + "jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件" tags = jieba.analyse.extract_tags(str, topK=5) print(" | ".join(tags)) 结果:默认值 | TFIDF | idf | IDF | path
上面说过字典有3部分组成:词语、词频(可省略)、词性(可省略)。textrank可运行过滤不同词性。
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(\'ns\', \'n\', \'vn\', \'v\'))
tags = jieba.analyse.textrank(str, topK=5, withWeight=False, allowPOS=(\'ns\', \'n\', \'vn\', \'v\')) print(" | ".join(tags)) 结果:权重 | 关键词 | 词性 | 频率 | 新建
【取分词及词性】
words = jieba.posseg.cut("中华人民共和国万岁!") for word, flag in words: print(\'%s %s\' % (word, flag)) 结果: 中华人民共和国 ns 万岁 m ! x
【取分词及起止位置】
words = jieba.tokenize("中华人民共和国万岁!") for w in words: print("word %s\\t\\t start: %d \\t\\t end:%d" % (w[0],w[1],w[2])) 结果: word 中华人民共和国 start: 0 end:7 word 万岁 start: 7 end:9 word ! start: 9 end:10
words = jieba.tokenize("中华人民共和国万岁!", mode=\'search\') #搜索模式 for w in words: print("word %s\\t\\t start: %d \\t\\t end:%d" % (w[0],w[1],w[2])) 结果: word 中华 start: 0 end:2 word 华人 start: 1 end:3 word 人民 start: 2 end:4 word 共和 start: 4 end:6 word 共和国 start: 4 end:7 word 中华人民共和国 start: 0 end:7 word 万岁 start: 7 end:9 word ! start: 9 end:10
简单示例:从 sql server 数据库中读取某个文本字段,分词并自定义绘图
# -*- coding: utf-8 -*- import pymssql import jieba import jieba.analyse import matplotlib.pyplot as plt from wordcloud import WordCloud from scipy.misc import imread host = "localhost" user = "kk" passwd = "kk" dbname = "hzc" conn = None try: conn = pymssql.connect( host = host, user = user, password = passwd, database = dbname ) cur = conn.cursor() cur.execute("select col from jieba;") rows = cur.fetchall() tagsall=u"" #tagsall = open(\'filepath.txt\',\'r\').read() for row in rows: tags = jieba.analyse.extract_tags(row[0], topK=20) tagsjoin = u" ".join(tags) tagsall = tagsall + " " + tagsjoin #print(tagsjoin) #http://labfile.oss.aliyuncs.com/courses/756/DroidSansFallbackFull.ttf wc_cfg = WordCloud( font_path="D:/Python35/Tools/whl/DroidSansFallbackFull.ttf",#字体 mask= imread("D:/Python35/Tools/whl/bg.png"),#背景模板(只黑白图,黑的显示) background_color="white", #背景色 max_words=1000, #最大词量 mode="RGBA", #透明底色(background_color不为空).默认rgb width=500, #宽度 height=400, #高度 max_font_size=100 #字体大小 ) wc = wc_cfg.generate(tagsall) plt.imshow(wc) plt.axis("off") plt.show() finally: if conn: conn.close()
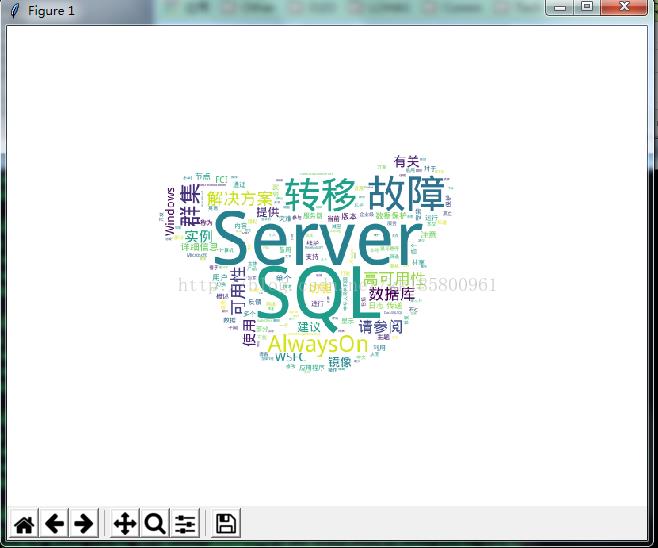
以上是关于Python 分词及词云绘图的主要内容,如果未能解决你的问题,请参考以下文章