回顾信号flask-scriptsqlalchemy介绍和快速使用创建操作数据表
Posted 人生苦短,我用python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回顾信号flask-scriptsqlalchemy介绍和快速使用创建操作数据表相关的知识,希望对你有一定的参考价值。
回顾
# 3 local对象
-并发编程中的一个对象,它可以保证多线程并发访问数据安全
-本质原理是:不同的线程,操作的是自己的数据
-不支持协程
# 4 自己定义local,支持线程和协程
# 注意点一:
try:
# 只要解释器没有装greenlet,这句话就会报错
# 一旦装了,有两种情况,使用了协程和没用协程,无论使用不使用,用getcurrent都能拿到协程id号
from greenlet import getcurrent as get_ident
except Exception as e:
from threading import get_ident
# 注意点二:重写类的 __setattr__和__getattr__
对象.属性 取值 不存在会触发 __getattr__
对象.属性 设置值 不存在时会触发 __setattr__
# 注意点三:由于重写了__setattr__和__getattr__
类内部使用 self.storage 会递归
使用类调用对象的方法,它就是普通函数,有几个值传几个值
object.__setattr__(self, \'storage\', )
等同于:self.storage=
等价于:setattr(self,\'storage\', ) 会递归
# 5 flask是如何实现这个local类的
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = name: value
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __getattr__(self, k):
ident = get_ident()
return self.storage[ident][k]
def __setattr__(self, k, v):
ident = get_ident() #如果用协程,这就是协程号,如果是线程,这就是线程号
if ident in self.storage: #\'协程id号\':arg:1,\'协程id号\':arg:2,\'协程id号\':arg:3
self.storage[ident][k] = v
else:
self.storage[ident] = k: v
# 6 偏函数 :提前传值,返回一个对象,后期可以调用这个对象,传入后续的值
# 7 请求上下文源码分析(ctx 对象),整个flask的执行流程
-一旦请求来了----》会执行 Flask类的对象app()---》触发Flask __call__--->self.wsgi_app(environ, start_response)
-Flask类wsgi_app 方法 大约 2417行
def wsgi_app(self, environ, start_response):
#1 返回了一个ctx,请求上下文对象,RequestContext 的对象,里面有session,request
ctx = self.request_context(environ)
try:
try:
# 2 ctx.push---->RequestContext的push---》382行
# _request_ctx_stack.push(self)--self是ctx---》是全局变量
# 是LocalStack()的对象
ctx.push()
# 匹配路由执行视图函数,请求扩展
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except: # noqa: B001
error = sys.exc_info()[1]
raise
# 把结果返回给wsgi服务器
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
# 把当前放进去的ctx剔除,当次请求结束了
ctx.auto_pop(error)
-是LocalStack()的对象 的push ,传入了ctx
def push(self, obj):
# self._local是 Flask自己定义的兼容线程和协程的Local
#self._local中反射 stack,会根据不同线程或协程,返回不同线程的stack
#rv是None的
rv = getattr(self._local, "stack", None)
if rv is None:
# rv=[]
# self._local.stack=rv
#self._local=\'协程id号1\':stack:[],\'协程id号2\':stack:[]
self._local.stack = rv = []
rv.append(obj)
#self._local=\'协程id号1\':stack:[ctx,],\'协程id号2\':stack:[]
return rv
在视图函数中:request = LocalProxy(partial(_lookup_req_object, "request"))
print(request.method) # 执行requets对象的 __getattr__
LocalProxy的__getattr__-->核心:
return getattr(self._get_current_object(), name)
self._get_current_object() 是 ctx中的真正request对象,那method,自如就拿到当次请求的method
def _get_current_object(self):
if not hasattr(self.__local, "__release_local__"):
#object.__setattr__(self, "_LocalProxy__local", local),初始化传入的
# local 是 partial(_lookup_req_object, "request")
#
# getattr(_lookup_req_object(\'request\'), \'method\')
# getattr(当次请求的reuqest, \'method\')
return self.__local() # self中的 __local,隐藏属性
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError("no object bound to %s" % self.__name__)
def _lookup_req_object(name):
# 这里把当前线程下 的ctx取出来了
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name) # 去ctx中反射request,返回的就是当次请求的requets
# django flask 同步框架,部署的时候,使用uwsgi部署,uwsgi是进程线程架构,并发量不高
# 可以通过uwsgi+gevent,部署成异步程序
信号
# Flask框架中的信号基于blinker(安装这个模块),其主要就是让开发者可是在flask请求过程中定制一些用户行为 flask 和django都有
#观察者模式,又叫发布-订阅(Publish/Subscribe) 23 种设计模式之一
pip3.8 install blinker
# 信号:signial 翻译过来的,并发编程中学过 信号量Semaphore
# 比如:用户表新增一条记录,就记录一下日志
方案一:在每个增加后,都写一行代码 ---》后期要删除,比较麻烦
方案二:使用信号,写一个函数,绑定内置信号,只要程序执行到这,就会执行这个函数
# 内置信号:flask少一些,django多一些
request_started = _signals.signal(\'request-started\') # 请求到来前执行
request_finished = _signals.signal(\'request-finished\') # 请求结束后执行
before_render_template = _signals.signal(\'before-render-template\') # 模板渲染前执行
template_rendered = _signals.signal(\'template-rendered\') # 模板渲染后执行
got_request_exception = _signals.signal(\'got-request-exception\') # 请求执行出现异常时执行
request_tearing_down = _signals.signal(\'request-tearing-down\') # 请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal(\'appcontext-tearing-down\')# 应用上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal(\'appcontext-pushed\') # 应用上下文push时执行
appcontext_popped = _signals.signal(\'appcontext-popped\') # 应用上下文pop时执行
message_flashed = _signals.signal(\'message-flashed\') # 调用flask在其中添加数据时,自动触发
# 使用内置信号的步骤
1 写一个函数
2 绑定内置信号
3 等待被触发
from flask import Flask, render_template,signals,session
from flask.signals import _signals
app = Flask(__name__)
app.debug = True
app.secret_key = \'SSSSSSSSSSSSS\'
# 定义信号
session_set = _signals.signal(\'session_set\')
# 写一个函数
def test1(*args,**kwargs):
print(args)
print(kwargs)
print(\'session设置了\')
# 绑定自定义的信号
session_set.connect(test1)
@app.route(\'/\')
def hhhh():
session[\'lqz\'] = \'lqz\'
session_set.send(\'lqz\') # 触发信号执行
return \'hello world\'
@app.route(\'/index\')
def index():
return render_template(\'index.html\', name=\'lqz\')
if __name__ == \'__main__\':
app.run()
# django中使用信号
https://www.cnblogs.com/liuqingzheng/articles/9803403.html
django中信号
Model signals
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
pre_delete # django的modal对象删除前,自动触发
post_delete # django的modal对象删除后,自动触发
m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发
class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发
Management signals
pre_migrate # 执行migrate命令前,自动触发
post_migrate # 执行migrate命令后,自动触发
Request/response signals
request_started # 请求到来前,自动触发
request_finished # 请求结束后,自动触发
got_request_exception # 请求异常后,自动触发
Database Wrappers
connection_created # 创建数据库连接时,自动触发
# django中使用内置信号
1 写一个函数
def callBack(*args, **kwargs):
print(args)
print(kwargs)
2 绑定信号
#方式一
post_save.connect(callBack)
# 方式二
from django.db.models.signals import pre_save
from django.dispatch import receiver
@receiver(pre_save)
def my_callback(sender, **kwargs):
print("对象创建成功")
print(sender)
print(kwargs)
3 等待触发
flask-script
# django中,有命令
python manage.py runserver
#flask启动项目,像djagno一样,通过命令启动(版本必须匹配)
Flask==2.2.2
Flask_Script==2.0.3
#借助于:flask-script 实现
安装:pip3.8 install flask-script
修改代码:
from flask_script import Manager
manager=Manager(app)
manager.run()
用命令启动
python manage.py runserver
from flask import Flask
from flask_script import Manager
app = Flask(__name__)
app.debug =True
manager = Manager(app)
@app.route(\'/\')
def index():
return \'index\'
if __name__ == \'__main__\':
# app.run()
manager.run()
# 自定制命令
#1 简单自定制命令
@manager.command
def custom(arg):
# 命令的代码,比如:初始化数据库, 有个excel表格,使用命令导入到mysql中
print(arg)
#2 复杂一些的自定制命令
@manager.option(\'-n\', \'--name\', dest=\'name\')
@manager.option(\'-u\', \'--url\', dest=\'url\')
def cmd(name, url):
# python run.py cmd -n lqz -u xxx
# python run.py cmd --name lqz --url uuu
print(name, url)
# django 中如何自定制命令
sqlalchemy快速使用
# flask 中没有orm框架,对象关系映射,方便我们快速操作数据库
# flask,fastapi中用sqlalchemy居多
# SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果
# 安装
pip3.8 install sqlalchemy
#了解
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
原生操作的快速使用
先不是orm 而是原生sql
第一步:导入
from sqlalchemy import create_engine
# 第二步:生成引擎对象
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/cnblogs",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
# 第三步:使用引擎获取连接,操作数据库
conn = engine.raw_connection()
cursor=conn.cursor()
cursor.execute(\'select * from aritcle\')
print(cursor.fetchall())
创建操作数据表
# 第一步:导入
from sqlalchemy import create_engine
import datetime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
# 第二步:执行declarative_base,得到一个类
Base = declarative_base()
# 第三步:继承生成的Base类
class User(Base):
# 第四步:写字段
id = Column(Integer, primary_key=True) # 生成一列,类型是Integer,主键
name = Column(String(32), index=True, nullable=False) # name列varchar32,索引,不可为空
email = Column(String(32), unique=True)
# datetime.datetime.now不能加括号,加了括号,以后永远是当前时间
ctime = Column(DateTime, default=datetime.datetime.now)
# extra = Column(Text, nullable=True)
# 第五步:写表名 如果不写以类名为表名
__tablename__ = \'users\' # 数据库表名称
# 第六步:建立联合索引,联合唯一
__table_args__ = (
UniqueConstraint(\'id\', \'name\', name=\'uix_id_name\'), # 联合唯一
Index(\'ix_id_name\', \'name\', \'email\'), # 索引
)
class Book(Base):
__tablename__ = \'books\'
id = Column(Integer, primary_key=True)
name = Column(String(32))
# 第七步:把表同步到数据库中
# 不会创建库,只会创建表
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/aaa",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
# 把表同步到数据库 (把被Base管理的所有表,都创建到数据库)
Base.metadata.create_all(engine)
# 把所有表删除
# Base.metadata.drop_all(engine)
JUC回顾之-Semaphore底层实现和原理
1.控制并发线程数的Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,保证合理的使用公共资源。
线程可以通过acquire()方法来获取信号量的许可,当信号量中没有可用的许可的时候,线程阻塞,直到有可用的许可为止。线程可以通过release()方法释放它持有
的信号量的许可。
2.Semaphore的方法列表:
// 创建具有给定的许可数和非公平的公平设置的 Semaphore。 Semaphore(int permits) // 创建具有给定的许可数和给定的公平设置的 Semaphore。 Semaphore(int permits, boolean fair) // 从此信号量获取一个许可,在提供一个许可前一直将线程阻塞,否则线程被中断。 void acquire() // 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞,或者线程已被中断。 void acquire(int permits) // 从此信号量中获取许可,在有可用的许可前将其阻塞。 void acquireUninterruptibly() // 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞。 void acquireUninterruptibly(int permits) // 返回此信号量中当前可用的许可数。 int availablePermits() // 获取并返回立即可用的所有许可。 int drainPermits() // 返回一个 collection,包含可能等待获取的线程。 protected Collection<Thread> getQueuedThreads() // 返回正在等待获取的线程的估计数目。 int getQueueLength() // 查询是否有线程正在等待获取。 boolean hasQueuedThreads() // 如果此信号量的公平设置为 true,则返回 true。 boolean isFair() // 根据指定的缩减量减小可用许可的数目。 protected void reducePermits(int reduction) // 释放一个许可,将其返回给信号量。 void release() // 释放给定数目的许可,将其返回到信号量。 void release(int permits) // 返回标识此信号量的字符串,以及信号量的状态。 String toString() // 仅在调用时此信号量存在一个可用许可,才从信号量获取许可。 boolean tryAcquire() // 仅在调用时此信号量中有给定数目的许可时,才从此信号量中获取这些许可。 boolean tryAcquire(int permits) // 如果在给定的等待时间内此信号量有可用的所有许可,并且当前线程未被中断,则从此信号量获取给定数目的许可。 boolean tryAcquire(int permits, long timeout, TimeUnit unit) // 如果在给定的等待时间内,此信号量有可用的许可并且当前线程未被中断,则从此信号量获取一个许可。 boolean tryAcquire(long timeout, TimeUnit unit)
3.Semaphore的内部结构
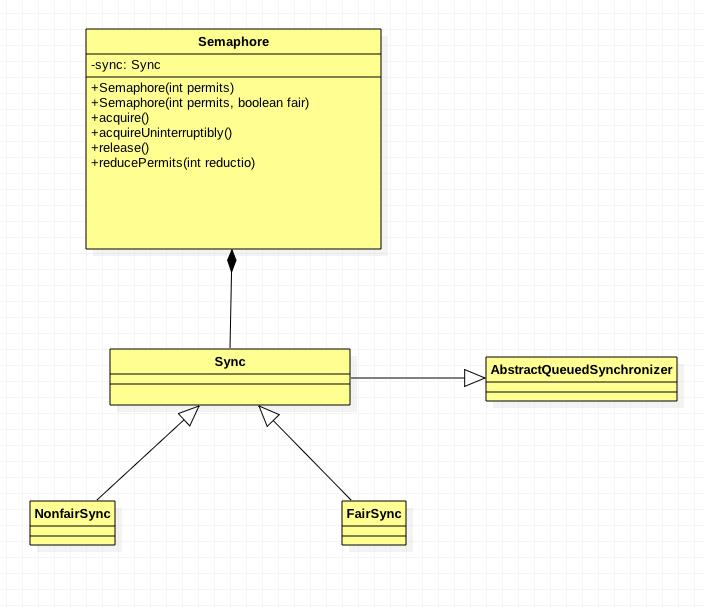
4.Semaphore的源码:
"公平信号量"和"非公平信号量"的区别
"公平信号量"和"非公平信号量"的释放信号量的机制是一样的!不同的是它们获取信号量的机制:线程在尝试获取信号量许可时,对于公平信号量而言,如果当前线程不在CLH队列的头部,则排队等候;而对于非公平信号量而言,无论当前线程是不是在CLH队列的头部,它都会直接获取信号量。该差异具体的体现在,它们的tryAcquireShared()函数的实现不同。
公平信号量tryAcquireShared源码如下:
/** * Fair version */ static final class FairSync extends Sync { private static final long serialVersionUID = 2014338818796000944L; FairSync(int permits) { super(permits); } protected int tryAcquireShared(int acquires) { for (;;) { if (hasQueuedPredecessors()) return -1; int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } } }
非公平信号量tryAcquireShared源码如下:
/** * NonFair version */ static final class NonfairSync extends Sync { private static final long serialVersionUID = -2694183684443567898L; NonfairSync(int permits) { super(permits); } protected int tryAcquireShared(int acquires) { return nonfairTryAcquireShared(acquires); } }
实例:
public class SemaphoreTest { private static final int THREAD_COUNT = 10;
private static ExecutorService executorService = Executors.newFixedThreadPool(THREAD_COUNT); // 创建5个许可,允许5个并发执行 private static Semaphore s = new Semaphore(5); public static void main(String[] args) {
//创建10个线程执行任务 for (int i = 0; i < THREAD_COUNT; i++) { executorService.execute(new Runnable() { @Override public void run() { try {
//同时只能有5个线程并发执行保存数据的任务 s.acquire(); System.out.println("线程" + Thread.currentThread().getName() + " 保存数据"); Thread.sleep(2000);
//5个线程保存完数据,释放1个许可,其他的线程才能获取许可,继续执行保存数据的任务 s.release(); System.out.println("线程" + Thread.currentThread().getName() + " 释放许可"); } catch (InterruptedException e) { e.printStackTrace(); } } }); } executorService.shutdown(); } }
结果:10个线程保存数据,但是只允许5个线程并发的执行,当5个线程都保存完数据以后,释放许可,其他线程才能拿到许可继续保存数据,直到10个线程都保存完数据释放许可为止。
线程pool-1-thread-2 保存数据 线程pool-1-thread-3 保存数据 线程pool-1-thread-1 保存数据 线程pool-1-thread-4 保存数据 线程pool-1-thread-5 保存数据 线程pool-1-thread-2 释放许可 线程pool-1-thread-6 保存数据 线程pool-1-thread-1 释放许可 线程pool-1-thread-3 释放许可 线程pool-1-thread-4 释放许可 线程pool-1-thread-9 保存数据 线程pool-1-thread-10 保存数据 线程pool-1-thread-5 释放许可 线程pool-1-thread-8 保存数据 线程pool-1-thread-7 保存数据 线程pool-1-thread-10 释放许可 线程pool-1-thread-9 释放许可 线程pool-1-thread-6 释放许可 线程pool-1-thread-8 释放许可 线程pool-1-thread-7 释放许可
以上是关于回顾信号flask-scriptsqlalchemy介绍和快速使用创建操作数据表的主要内容,如果未能解决你的问题,请参考以下文章