Python 数据分析1
Posted Dandy Zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 数据分析1相关的知识,希望对你有一定的参考价值。
本节概要
基础环境
ipython基础
前言
这是18年的第一篇blog,因为boss对于我的工作上的一些期望,需要着手做一些数据分析的工作,所以开始撰写这个系列的blog。分类的内的主要内容基本都是楼主鉴于阅读《利用python进行数据分析》一书所写的基本要点。
首先大环境就不需要多说了,为什么要用python做这些事,为什么要选择numpy跟pandas来进行数据处理分析?如果真的是小巨白,那就耐心开完所有内容吧,到时候就会发现,哇哦,很多用代码都很难写的东西,为什么这些模块处理起来贼简单。楼主反正是惊讶地合不拢嘴的状态研究这本书的。另外此分类的blog需要python基础,如果没有的话,简易先看完python基础分类章节。
希望世界和平,希望我跟某天看见这篇blog的所有的读者都可以通过自己的努力,实现一个个小目标,走向成功。大家加油。
环境问题
首先解决一个我花了2天一直百度都没有找到准确解答方案的问题。业务需求是这样的,楼主所在公司是用的sql server数据库,一切的数据分析的基础都是基于数据,而楼主刚好遇到一个很不巧的问题,就是windows直接装pymssql模块报错的问题,具体我也说不清为什么用
pip install pymssql 或者 pip3 install pymssql
就是安装不了,总是报错。就像下图,报错说少sqlfront.h文件。
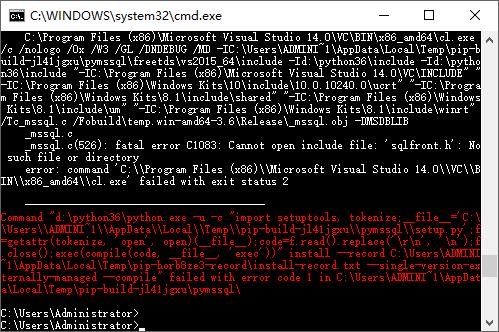
去百度搜索freetds-dev;

楼主电脑是window * 64位,python版本是3.6;(可以这样查询python版本,有基础的,这个不知道,就真的是瓜皮了)
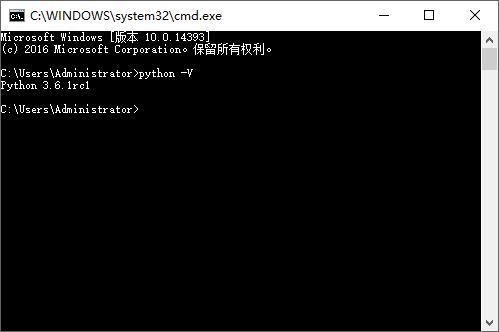
所以选择X86_64_vs2015,并下载。
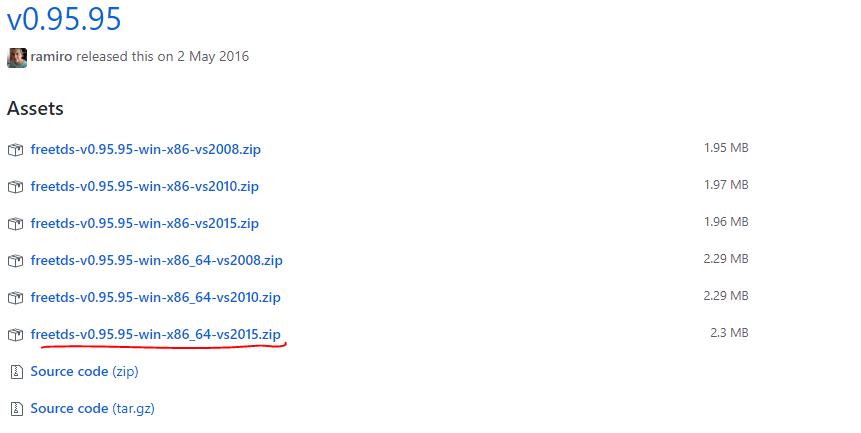
下载好,解压,在里面include文件夹下会找到那个报错文件sqlfront.h文件,一共需要好几个文件。不介意的话可以把全部文件copy到python根目录的include文件夹里面;追求完美的可以先copy这个文件过去,继续pip 看缺少什么文件,一个个拖拽过去。
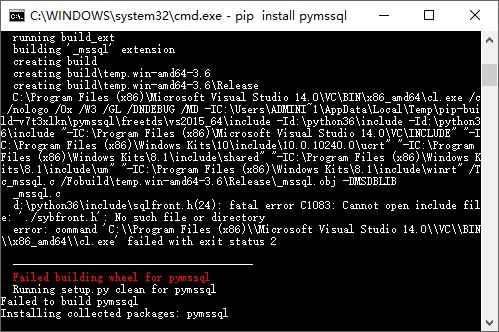
就这样。。。。
就不一一试了。再一次pip install pymssql 会发现下面的报错。
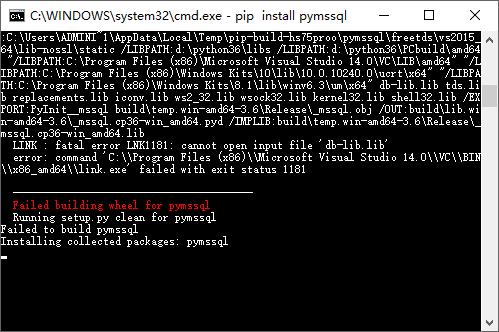
?????WHF????
楼主就是卡在这个点,一直解决不了。最后在整整2天后,试出来一个有效的方法。
百度一下pymssql-2.1.3.tar.gz这个文件。
或者使用这个网址https://pypi.python.org/pypi/pymssql/2.1.3,拉到最后,下载匹配的版本
这里又不知道是什么版本了????
其实这个我也不会,都是百度到的,所以说百度真的是很好的老师。别跟我说,为什么直接输入python没出来下面的图。。去添加环境变量去,pip也加一下
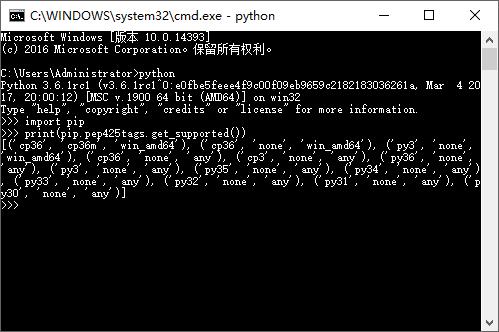
执行上面截图的语句,就可以查询出需要安装的wheel的版本了。
下载匹配的版本。
cmd到下载目录,解压好文件并用pip安装
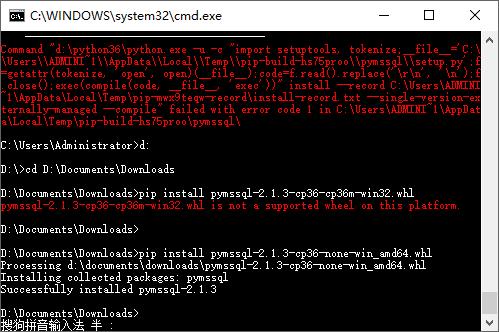
这时候去到python根目录的site-packages就可以找到wheel文件装好的文件夹了。
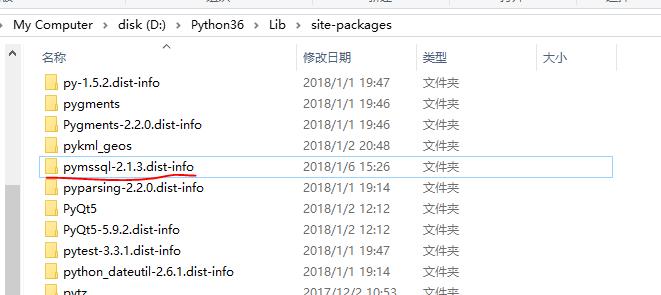
这时候再下载一份之前网页里面最后一个pymssql主文件。解压
解压好文件,把文件夹改名为
然后copy到python根目录的site-package文件夹。别问为什么,我也不知道。看一下里面的文件名大概能猜到。(只可意会,不可言传)
这时候就好了,真的。。。。我反正就是这么试出来的,如果还是不可以,那就对不起,打扰了。、。。。
安装模块
直接pip安装numpy,matplotlib,pandas,ipython模块.
查了下,很多人说,anaconda用来做数据分析比较好,可是楼主习惯了用pycharm,因为之前一直用,而且pycharm做django项目很强大,所以就继续用pycharm了,只需要安装一个jupyter note book 就好了。
另外一些常用习惯,语法:
import numpy as np import pandas as pd import matplotlib.pyplot as plt
后面会一直延用这样的语法习惯,撰写内容。
另外不建议直接导入类似numpy这种大型库。(from numpy inport *)
ipython基础
其实有python基础的,这些内容不是很大的问题。
启动ipython解释器跟启动python解释器差不多。只是把命令改成ipython就可以了,另外添加环境变量。。

可以输入任何的python语句。
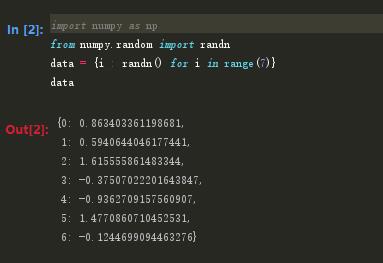
tab键自动完成
用来提示,用pycharm这个就不重要了。。
tab键不仅可以用于搜索命名空间,对象和模块属性。当你输入热河看上去像文件路径的东西时(即使是在一个Python字符串中),按下tab键即可找出电脑文件系统中与之匹配的东西
内省
在变量前面或后面加一个问号(?)就可以将有关该对象的一些通用信息显示出来。如果对象时一个函数或者实例方法,那么其docstring也会被显示出来。使用双问号可以显示该函数的源代码,如果可能的话。
另外还有一点很强大的是,如果我们用上通配符*,比如np.*load*即可线输出所有与该通配符表达式相匹配的名称。
%run命令
在python里面,我们可以直接用python + *.py文件,直接运行文件。
在ipython环境下,可以用%run *.py来运行。
脚本是在一个空的命名空间中运行的(没有任何import,也没用定义任何其他的变量,我觉得应该都知道)
中断代码执行
ctrl + c
异常和跟踪
%run执行脚本发成异常时,ipython会默认输出整个调用栈的跟踪还附上调用栈附近的几行代码作为上下文参考。
魔术命令
ipython有一些特殊命令被称为魔术命令,他们有的为常见任务提供便利,有些使你能够轻松控制Ipython系统的行为。
魔术命令是以百分号为前缀。例如可以用 %timeit这个魔术命令检测任意python语句的执行时间(如矩阵算法)
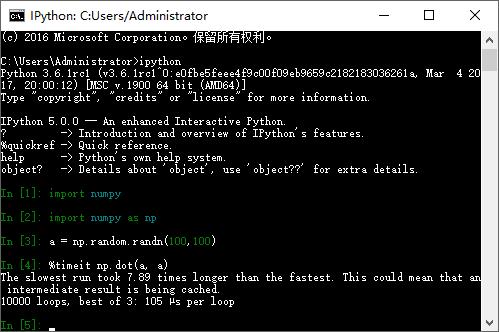
魔术命令默认是可以不带百分号使用的,只要没有与其同名的变量即可。这个技术叫做automatic,可以通过%automatic 打开或者关闭。
可以在ipython中直接访问它的文档,建议大家浏览一下所以特殊的命令(输入%quickref或者magic即可,反正我还没时间看)
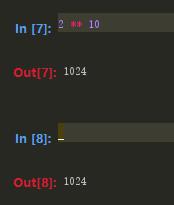
输入的文本被保存在名为_iX变量中,其中X是输入航的行号。每一个输入变量都对应输出变量_X.
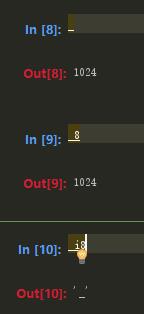
由于输入变量是字符串。因此可以用python 的exec关键字直接执行(一开始就说了,可以python的语法都可以执行)
记录输出和输入
Ipython能够记录整个控制台会话,包括输入和输出。执行%logstart即可开始记录日志。
shell命令和别名
在Ipython中,以感叹号(!)开头的命令行表示其后的所有内容需要在系统shell中执行。也就是说,你可以删除文件,修改目录或执行任意其他处理过程。甚至可以启动一些能将控制权从Ipython手中夺走的进程。
此外,还可以将shell命令的控制台输出存放到变量中,只需将!开头的表达式赋值给变量即可。
ip_info = !ifconfig eth0 | grep "inet" ip_info[0].strip()
使用!时,Ipython还允许使用当前环境中定义的Python值。只需在变量名前加上美元符$
foo = \'test*\' ! ls $foo # 会将所有的 匹配文件全部抓取出来
%alias可以为shell命令定义简称。
%alias 11 ls -l 11/user
如果一次执行多条命令,只需将它们写在一行并以分好隔开即可:
%alias test_alias(cd ch08; ls; cd.....) test
Ipython会在会话结束时立即忘记你所定义的一切别名。
目录书签
Ipython有一个简单的目录系统,它能保存常用的目录的别名以便实现快速跳转。
%bookmark bookmark1 /home/wes/xxx cd bookmark1 ==> 转到/home/wes/xxx目录
如果书签名与当前工作目录中的某个目录名冲突,可以通过-b标记(其作用是覆写,使用书签目录)。%bookmark -l选项的作用是列出所有书签:
%bookmark -l
书签跟别名的区别是,书签会被自动持久化。
交互式调试器
调试代码的最佳时机之一就是错误刚刚发生那会儿。%debug命令将会调用那个事后调试器,并直接跳转到引发异常的那个栈帧。
在这个调试器中,你可以执行任意python代码并查看各个栈帧中的一切对象和数据。默认是从最低级开始的(即错误发生的地方)。输入u(或者up)和d(或者down)即可在栈跟踪的各级之间切换。
执行%pdb命令可以让Ipython在出现异常之后自动调用调试器。
此外,调试器还可以为代码开发工作提供帮助,尤其是当你想要设置断点或函数/脚本进行单步调试以查看各条语句的执行情况时。实现这个目的的方式有几个。第一,使用带-d选项的%run命令,这将会在执行脚本文件中的代码前先打开调试器。必须立即输入s才能进入脚本。
run -d ch03/ipython_bug.py s
在此之后,改文件接下来的执行方式就全凭你一句话。c(continue)使脚本一直运行下去,直到断点时为止。输入n(或next)直接执行到下一行。
注意调试器命令的优先级高于变量名。这时在变量前面加上感叹号(!)即可查看其内容。

调试器的其他使用场景
1、set_trace(穷人断点)。
def set_trace():
from Ipython.core.debugger import Pdb
Pdb(color_scheme=\'Linux\').set_trace(sys._getframe().f_back)
def debug(f, *args, **kwargs):
from Ipython.core.debugger import Pdb
pdb = Pdb(color_scheme=\'Linux\')
return pdb.runcall(f, *args, **kwargs)
第一个函数(set_trace)非常简单,可以将它放在任何希望停下来查看的地方:按下C(continue)仍然会使代码恢复执行,不受影响。
2、debug函数
debug函数可以使你直接在任意函数上使用调试器。假设有这样一个函数:
def f(a, b, c=1): temp = x + y return temp/z
现在对其进行单步调试。注意一下调试方法,我们将f当做第一个参数传给debug函数。后面再按顺序跟上各个需要传给f的关键字参数。
debug(f, 1, 1, c=4)
此外可以结合%run使用,通过%run -d执行脚本,你将会直接进入调试器,然后可以设置一些断点并启动脚本。如果再加上-b和一个行号,则调试器在启动时就会自动设置一个断点。(建议这一段最好百度一下这本书看一下)
测试代码的执行时间
用于Ipython的出发点是为了大数据分析,当然面对的是规模很大,数据量很多的数据,对于这种运行时间长的数据分析应用程序,可能我们需要测试一下各个部分的代码执行时间,来具体了解下,在整个过程中到底是哪些函数占用的时间最多。
使用内置的time模块以及time.clock和time.time 函数可以手动测试代码执行时间,但这是一件令人烦闷的时间,因为开发者或者测试者需要编写许多一模一样的了无生趣的公式化代码:
import time
start = time.time()
for i in range(iterations):
# 在这里执行代码测试
end = (time.time() - start)/iterations
由于这是一个非常有用的需求功能,Ipython开发测试代码的过程中,提供了可以轻松测试得到信息的功能。魔术函数%time 和 %timeit。%time一次执行一条语句然后报告总体执行时间。
# 假设我们有一个非常大的字符串数组,需要找出所有‘foo’开头的字符串 strings = [\'foo\', \'foo1\', \'baz\', \'python\', \'xiaoxiao\'] * 100000 method1 = [x for x in strings if x.startswith(\'foo\')] method2 = [x for x in strings if [x:3] == \'foo\']
看上去它们的性能表现应该差不多,我们来用%time验证一下。


看上去第一种方法比第二种快了很多,但这并不是一个非常精确的结果,如果你对相同的语句执行多次%time的话,也会发现其结果会变得。为了得到更为精确的结果,需要使用魔术函数%timeit,对于任何语句,会执行多次产生一个非常精确的平均执行时间。


这里需要说明的就是,我们需要关注的正是这些,事实就是,我们有必要了解python标准库,Numpy,Pandas以及书中所用到的其他库的性能特点。在大型数据分析应用程序中,这些不起眼的毫秒数是不断累积的!对于那些执行时间非常短的分析语句和函数而言。%timeit是非常有用的。虽然这些时间值小到可以忽略不计,但是同样对于数据量很大的处理,执行100w次这样的处理,所用的时间就会出现很大的偏差。对于上面的实例,其实我们可以这样比较这2个函数,了解其性能特点:

基本性能分析: %prun和%run -p
逐行分析函数性能
建议这两点看一下书,要写个py文件来测试,很烦0.0.总之用%prun(cProfile)做宏观性能分析,而用%lprun(line_profiler)做微观的性能分析。
以上是关于Python 数据分析1的主要内容,如果未能解决你的问题,请参考以下文章