详解 Flink Catalog 在 ChunJun 中的实践之路
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解 Flink Catalog 在 ChunJun 中的实践之路相关的知识,希望对你有一定的参考价值。
我们知道 Flink 有Table(表)、View(视图)、Function(函数/算子)、Database(数据库)的概念,相对于这些耳熟能详的概念,Flink 里还有一个 Catalog(目录) 的概念。
本文将为大家带来 Flink Catalog 的介绍以及 Flink Catalog 在 ChunJun 中的实践之路。
Flink Catalog 简介
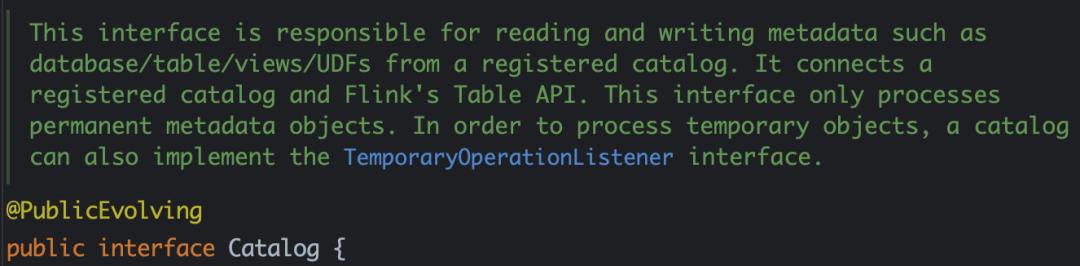
Catalog 提供元数据,如数据库、表、分区、视图,以及访问存储在数据库或其他外部系统中的数据所需的函数和信息。
Flink Catalog 作用
数据处理中最关键的一个方面是管理元数据:
· 可能是暂时性的元数据,如临时表,或针对表环境注册的 UDFs;
· 或者是永久性的元数据,比如 Hive 元存储中的元数据。
Catalog 提供了一个统一的 API 来管理元数据,并使其可以从表 API 和 SQL 查询语句中来访问。
Catalog 使用户能够引用他们数据系统中的现有元数据,并自动将它们映射到 Flink 的相应元数据。例如,Flink 可以将 JDBC 表自动映射到 Flink 表,用户不必在 Flink 中手动重写 DDL。Catalog 大大简化了用户现有系统开始使用 Flink 所需的步骤,并增强了用户体验。
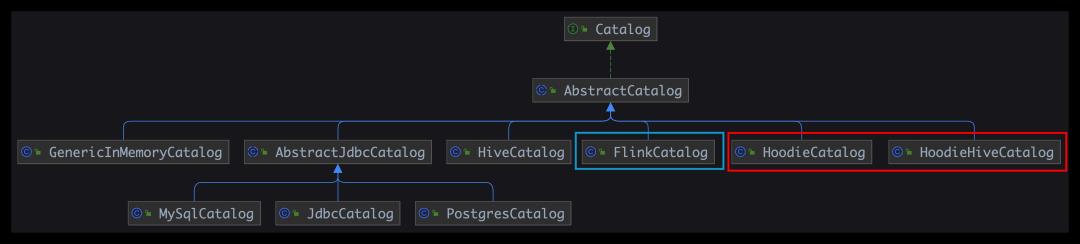
Flink Catalog 的结构
● Flink Catalog 原生结构
• GenericInMemoryCatalog:基于内存实现的 Catalog
• Jdbc Catalog:可以将 Flink 通过 JDBC 协议连接到关系数据库,目前 Flink 在1.12和1.13中有不同的实现,包括 MySql Catalog 和 Postgres Catalog
• Hive Catalog:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口
● Flink Iceberg Catalog
● Flink Hudi Catalog
HoodieCatalog、HoodieHiveCatalog
Flink Catalog 详解
GenericInMemoryCatalog
final CatalogManager catalogManager =
CatalogManager.newBuilder()
.classLoader(userClassLoader)
.config(tableConfig)
.defaultCatalog(
settings.getBuiltInCatalogName(),
new GenericInMemoryCatalog(
settings.getBuiltInCatalogName(),
settings.getBuiltInDatabaseName()))
.build();
defaultCatalog =
new GenericInMemoryCatalog(
defaultCatalogName, settings.getBuiltInDatabaseName());
CatalogManager catalogManager =
builder.defaultCatalog(defaultCatalogName, defaultCatalog).build();
GenericInMemoryCatalog 所有的数据都保存在 HashMap 里面,无法持久化。
JDBC Catalog
CREATE CATALOG my_catalog WITH(
\'type\' = \'jdbc\',
\'default-database\' = \'...\',
\'username\' = \'...\',
\'password\' = \'...\',
\'base-url\' = \'...\'
);
USE CATALOG my_catalog;
如果创建并使用 Postgres Catalog 或 MySQL Catalog,请配置 JDBC 连接器和相应的驱动。
JDBC Catalog 支持以下参数:
• name:必填,Catalog 的名称
• default-database:必填,默认要连接的数据库
• username:必填,Postgres/MySQL 账户的用户名
• password:必填,账户的密码
• base-url: 必填,(不应该包含数据库名)
对于 Postgres Catalog base-url 应为 "jdbc:postgresql://:" 的格式
对于 MySQL Catalog base-url 应为 "jdbc:mysql://:" 的格式
Hive Catalog
CREATE CATALOG myhive WITH (
\'type\' = \'hive\',
\'default-database\' = \'mydatabase\',
\'hive-conf-dir\' = \'/opt/hive-conf\'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;

Iceberg Catalog
● Hive Catalog 管理 Iceberg 表
(Flink) default_database.flink_table ->
(Iceberg) default_database.flink_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hive_prod\',
\'uri\'=\'thrift://localhost:9083\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
(Flink)default_database.flink_table ->
(Iceberg) hive_db.hive_iceberg_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hive_prod\',
\'catalog-database\'=\'hive_db\',
\'catalog-table\'=\'hive_iceberg_table\',
\'uri\'=\'thrift://localhost:9083\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
● Hadoop Catalog 管理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hadoop_prod\',
\'catalog-type\'=\'hadoop\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
● 自定义 Catalog 管理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'custom_prod\',
\'catalog-impl\'=\'com.my.custom.CatalogImpl\',
-- More table properties for the customized catalog
\'my-additional-catalog-config\'=\'my-value\',
...
);
• connector:iceberg
• catalog-name:用户指定的目录名称,这是必须的,因为连接器没有任何默认值
• catalog-type:内置目录的 hive 或 hadoop(默认为hive),或者对于使用 catalog-impl 的自定义目录实现,不做设置
• catalog-impl:自定义目录实现的全限定类名,如果 catalog-type 没有被设置,则必须被设置,更多细节请参见自定义目录
• catalog-database: 后台目录中的 iceberg 数据库名称,默认使用当前的 Flink 数据库名称
• catalog-table: 后台目录中的冰山表名,默认使用 Flink CREATE TABLE 句子中的表名
Hudi Catalog
create catalog hudi with(
\'type\' = \'hudi\',
\'mode\' = \'hms\',
\'hive.conf.dir\'=\'/etc/hive/conf\'
);
--- 创建数据库供hudi使用
create database hudi.hudidb;
--- order表
CREATE TABLE hudi.hudidb.orders_hudi(
uuid INT,
ts INT,
num INT,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
\'connector\' = \'hudi\',
\'table.type\' = \'MERGE_ON_READ\'
);
select * from hudi.hudidb.orders_hudi;
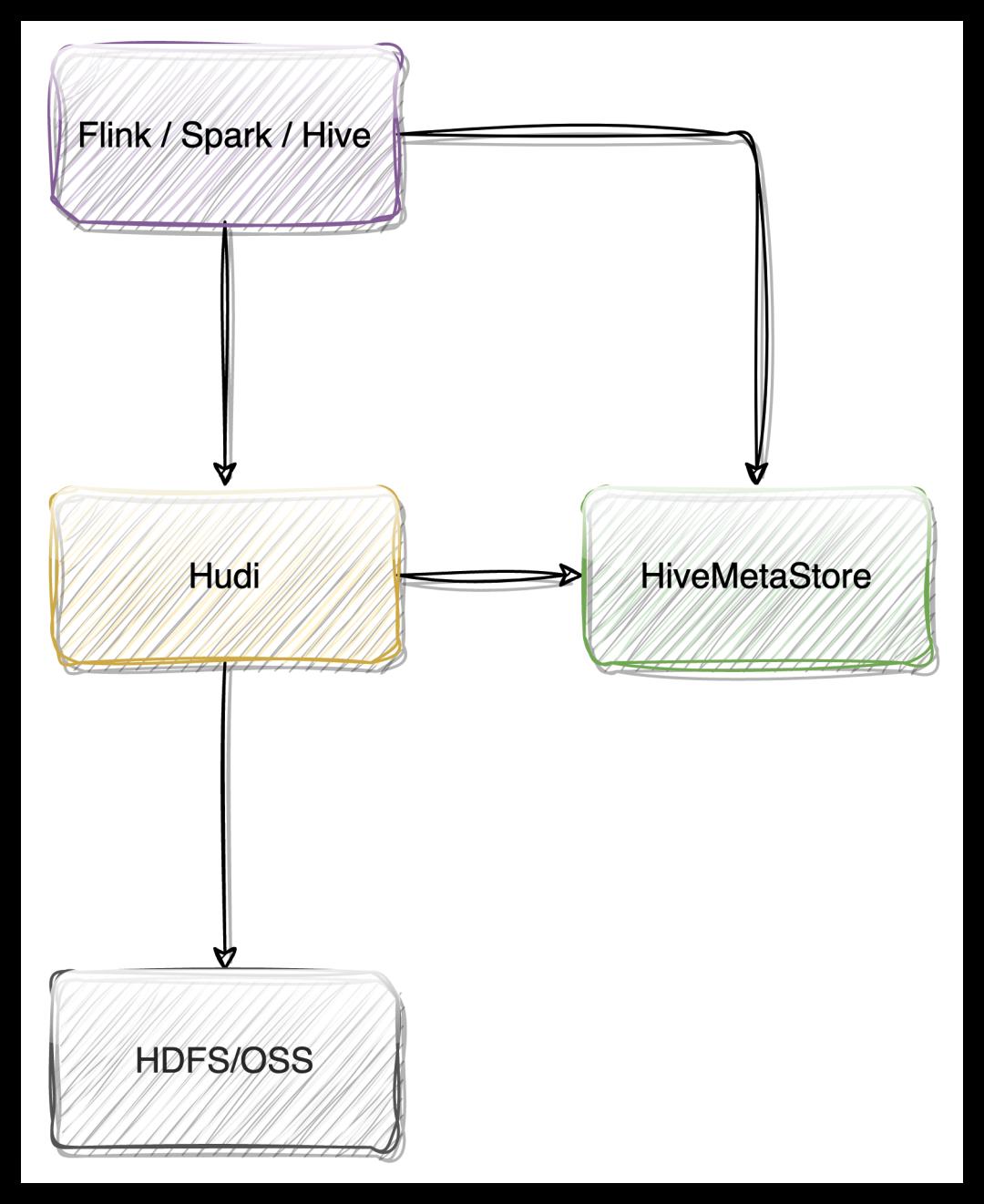

Flink Catalog 在 ChunJun 中的实践
下面将为大家介绍本文的重头戏,Flink Catalog 在 ChunJun 中的实践之路。
直接引入开源 Catalog
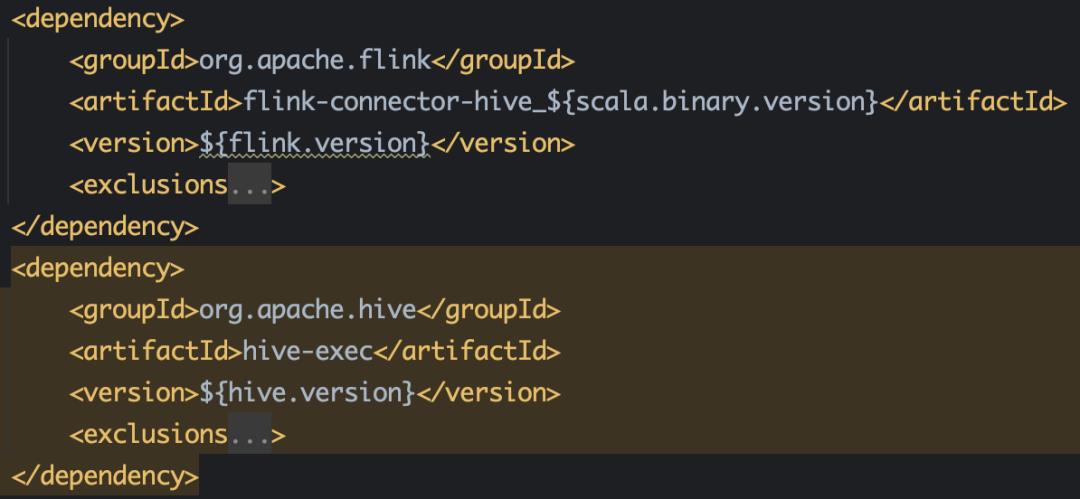
ChunJun 目前的所有 Catalog 为以下四种:

● Hive Catalog 需要的依赖
● Iceberg Catalog 需要的依赖

● JDBC Catalog
JDBC 因为 Flink 1.12 和 1.13 API 有变化,因此需要涉及源码的改动,改动一些 API 后,从源码引入。
● DT Catalog
结合内部业务,自定义的一种 Catalog ,下文将会进行详细介绍。
DT Catalog -存储元数据表设计
● 创建 mysql 元数据表 database_info
-- 创建表的 sql
create table database_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT \'项目ID\',-- database id
`catalog_name` varchar(255) COMMENT \'catalog 名字\',
`database_name` varchar(255) COMMENT \'database 名字\',
`catalog_type` varchar(30) COMMENT \'catalog 类型, eg: mysql,oracle...\',
`project_id` int(11) NOT NULL COMMENT \'项目ID\',
`tenant_id` int(11) NOT NULL COMMENT \'租户ID\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创建索引
CREATE INDEX idx_catalog_name_database_name_project_id_tenant_id ON database_info (`catalog_name`, `database_name`, `project_id`, `tenant_id`);
● 创建 mysql 元数据表 table_info
-- 创建表的 sql
create table table_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT,
`database_id` bigint COMMENT \'database_info 表的 id\',
`table_name` varchar(255) COMMENT \'表名\',
`project_id` int(11) NOT NULL COMMENT \'项目ID\',
`tenant_id` int(11) NOT NULL COMMENT \'租户ID\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创建索引
CREATE INDEX idx_catalog_id_project_id_tenant_id ON table_info (`database_id`, `project_id`, `tenant_id`);
CREATE INDEX idx_database_id_table_name_project_id_tenant_id ON table_info (`database_id`, `table_name`, `project_id`, `tenant_id`);
● 创建 mysql 元数据表 properties_info
create table properties_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT ,
`table_id` bigint(20) COMMENT \'table_info 表的 id\',
`key` varchar(255) COMMENT \'表的属性 key\',
`value` varchar(255) COMMENT \'表的属性 value\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
CREATE INDEX idx_table_id ON properties_info (table_id);
● properties_info 里面存了什么?
schema.0.name=id,
schema.0.data-type=INT NOT NULL,
schema.1.name=name,
schema.1.data-type=VARCHAR(2147483647)
schema.2.name=age,
schema.2.data-type=BIGINT,
schema.primary-key.name=PK_3386,
schema.primary-key.columns=id,
connector=jdbc,
url=jdbc:mysql: //172.16.83.218:3306/wujuan?useSSL=false,
username=drpeco,
password=DT@Stack#123,
comment=,
scan.auto-commit=true,
lookup.cache.max-rows=20000,
scan.fetch-size=10,
lookup.cache.ttl=700000
table-name=t2,
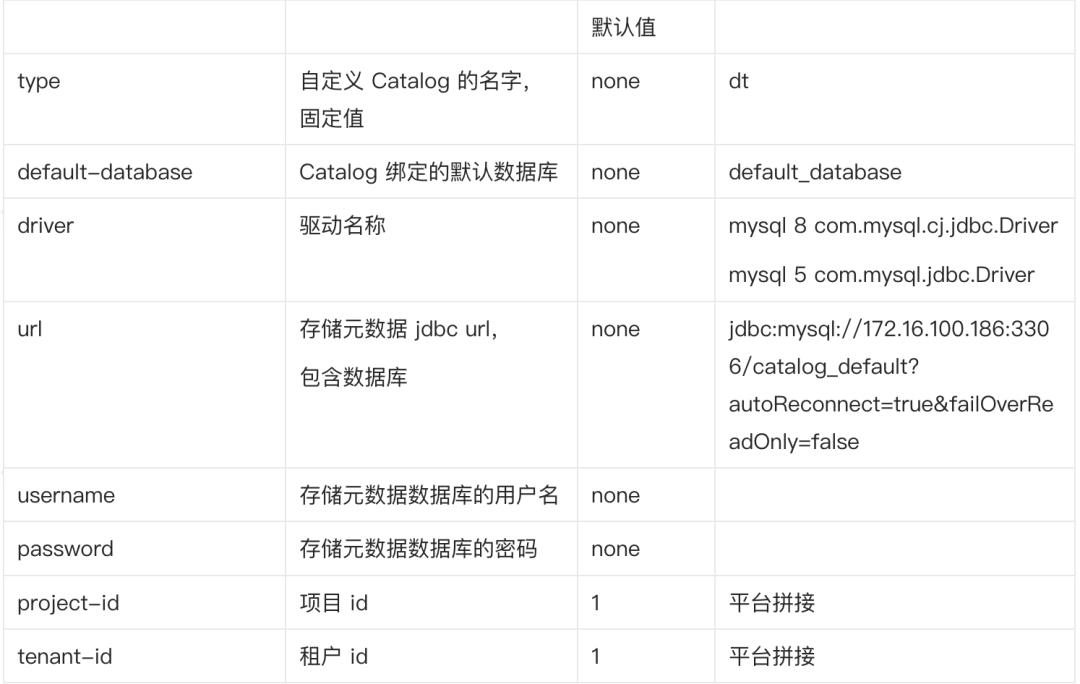
使用 DT Catalog
● 创建 DT Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://xxx:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
● 创建 Database
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
Drop a database with the given database name. If the database to drop does not exist, an exception is thrown.
IF EXISTS
If the database does not exist, nothing happens.
RESTRICT
Dropping a non-empty database triggers an exception. Enabled by default.
CASCADE
Dropping a non-empty database also drops all associated tables and functions.
create database if not exists catalog1.database1
drop database if exists catalog1.database1
-- 删除非空数据库,连通数据库中的所有表也一起删除
drop database if exists catalog1.database1 CASCADE
● 创建 Table
1)Rename Table
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
Rename the given table name to another new table name
2)Set or Alter Table Properties
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
Set one or more properties in the specified table. If a particular property is already set in the table, override the old value with the new one.
-- 创建表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
-- 删除表
drop table if exists mysql_catalog2.wujuan_database2.wujuan_table
-- 重命名表名
ALTER TABLE catalog1.default_database.table1 RENAME TO table2;
-- 设置表属性
ALTER TABLE catalog1.default_database.table1
SET (
\'tablename\'=\'t2\',
\'url\'=\'dbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\'
)
使用 DTCatalog 的具体场景和实现原理
● 全部是 DDL,只有 Catalog 的创建
CREATE CATALOG catalog1
WITH (
\'type\' = \'DT\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default?autoReconnect=true&failOverReadOnly=false\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
```
· 可以执行,但是没有意义,ChunJun 不会存储 Catalog 信息,只有平台存储;
· 不支持语法校验。
● 全部是 DDL,包含 Catalog、Database、Table 的创建
-- 初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
-- 创建数据库
create database if not exists database1
-- 创建表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
· 无论创建数据库、表,删除数据库、表,必须包含 create catalog 语句;
· 可以执行,可以创建数据库和表;
· 不支持语法校验。
// 抛出异常的逻辑
StatementSet statementSet = SqlParser.parseSql(job, jarUrlList, tEnv);
TableResult execute = statementSet.execute(); -->
tableEnvironment.executeInternal(operations); -->
Pipeline pipeline = execEnv.createPipeline(transformations, tableConfig, jobName); -->
StreamGraph streamGraph = ExecutorUtils.generateStreamGraph(getExecutionEnvironment(), transformations); -->
// 抛出异常的方法
public static StreamGraph generateStreamGraph(StreamExecutionEnvironment execEnv, List<Transformation<?>> transformations)
if (transformations.size() <= 0)
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot generate StreamGraph.");
...
return generator.generate();
// 如果没有 insert 语句的时候,无法生成 JobGraph,但是 DDL 是执行成功的。
// 因此捕获 FlinkX 抛出的特殊异常,此语句的异常 Message 是 FlinkX 里面处理的。
try
PackagedProgramUtils.createJobGraph(program, flinkConfig, 1, false);
catch (ProgramInvocationException e)
// 仅执行 DDL FlinkX 抛出的异常
if (!e.getMessage().contains("OnlyExecuteDDL"))
throw e;

● DDL + DML,包含 create + insert 语句
1)初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
2.1)创建数据库
create database if not exists database1
2.2)创建源表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
3.1)创建数据库
create database if not exists catalog1.database2;
3.2)创建结果表
CREATE TABLE if not exists catalog1.database2.table2
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'print\'
);
4)执行任务
insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 不可以执行,可以提交;
· 支持语法校验。
● DML,只有 Insert 语句
-- 初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
-- 执行任务
insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 如果 Catalog 的 数据库和表都已经创建好了,那么直接写 insert 就可以提交任务;
· 不可以执行,可以提交;
· 支持语法校验。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStackRocketMQ Flink Catalog 设计与实践
摘要:本文为 RocketMQ Flink Catalog 使用指南。主要内容包括:
- Flink 和 Flink Catalog
- RocketMQ Flink Connector
- RocketMQ Flink Catalog
作者:李晓双 ,Apache RocketMQ Contributor
Mentor:蒋晓峰,Apache RocketMQ Committer
一、Flink 和 Flink Catalog
Flink 是一个分布式计算引擎,目前已经实现批流一体,可以实现对有界数据和无界数据的处理。需要有效分配和管理计算资源才能执行流式应用程序。
目前 Flink API 共抽象为四个部分:
- 最顶层的抽象为 SQL。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
- 第二层抽象为 Table API。Table API是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。
- 第三层抽象是Core APIs 。许多程序可能使用不到最底层的 API,而是可以使用Core APIs进行编程:其中包含DataStream API(应用于有界/无界数据流场景)和DataSet API(应用于有界数据集场景)两部分。
- 第四层抽象为有状态的实时流处理。

Flink Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。Flink 对于元数据的管理分为临时的、持久化的两种。内置的 GenericInMemoryCatalog 是基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。JdbcCatalog 和 HiveCatalog 就是可以持久化元数据的 Catalog。
Flink Catalog 是扩展的,支持用户自定义。为了在 Flink SQL 中使用自定义 Catalog,用户需要通过实现CatalogFactory接口来实现对应的 Catalog 工厂。该工厂是使用 Java 的服务提供者接口 (SPI) 发现的。可以将实现此接口的类添加到 META_INF/services/org.apache.flink.table.factories.FactoryJAR 文件中。
二、RocketMQ Flink Connector
RocketMQ 连接器为 Flink 提供从 RocketMQ Topic 中消费和写入数据的能力。Flink 的 Table API & SQL 程序可以连接到其他外部系统,用于读取和写入批处理和流式表。Source 提供对存储在外部系统(例如数据库、键值存储、消息队列或文件系统)中的数据的访问。Sink 将数据发送到外部存储系统。
该项目的 Github 仓库是: https://github.com/apache/rocketmq-flink

三、RocketMQ Flink Catalog
3.1 设计与实现
3.1.1 RocketMQ Flink Catalog 的设计主要分为两步
- 实现一个 RocketMqCatalogFactory 基于字符串属性创建已配置 Catalog 实例的工厂。将此实现类添加到
META_INF/services/org.apache.flink.table.factories.Factory 中。 - 继承 AbstractCatalog 实现 RocketMqCatalog,通过实现 Catalog 接口中的方法,完成对数据库、表、分区等信息的查询操作。
类图如下:

3.1.2 RocketMQ Flink Catalog 的存储
RocketMQ Flink Catalog 的底层存储使用的是 RocketMQ Schema Registry。Flink 调用 Catalog 的时候,在 AbstractCatalog 的实现类中通过 RocketMQ Schema Registry 的客户端和 RocketMQ Schema Registry 服务端进行交互。
- Database : 返回默认的 default 。
- Table : 从 RocketMQ Schema Registry 获取对应的 Schema,然后解析 IDL 转换成 DataType。
- Partition : 通过
DefaultMQAdminExt 从 RocketMQ 中获取到 Partition 相关信息。
RocketMQ Schema Registry 是一个 Topic Schema 的管理中心。它为 Topic(RocketMQ Topic)的注册、删除、更新、获取和引用模式提供了一个 RESTful 接口。New RocketMQ 客户端通过将 Schema 与 Subject 关联起来,可以直接发送结构化数据。用户不再需要关心序列化和反序列化的细节。

3.1.3 RocketMQ Flink Catalog 支持的 API
目前 RocketMQ Flink Catalog 支持对 Database、Table、Partition 的查询和判断是否存在的操作,不支持创建、修改、删除。所以在使用之前需要通过 RocketMQ Schema Registry 来创建好对应的 Schema。

3.2 使用指南
表环境(TableEnvironment)是 Flink 中集成 Table API & SQL 的核心概念。它负责:
- 在内部的 Catalog 中注册 Table。
- 注册外部的 Catalog。
- 加载可插拔模块。
- 执行 SQL 查询。
- 注册自定义函数 (scalar、table 或 aggregation)。
- 将 DataStream 或 DataSet 转换成 Table。
- 持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用。
3.2.1 创建并注册 Catalog
Table API :
RocketMQCatalog rocketMqCatalog = new RocketMQCatalog("rocketmq_catalog", "default", "http://localhost:9876", "http://localhost:8080");
tableEnvironment.registerCatalog("rocketmq_catalog", rocketMqCatalog);SQL:
TableResult tableResult = tableEnvironment.executeSql(
"CREATE CATALOG rocketmq_catalog WITH (" +
"type=rocketmq_catalog," +
"nameserver.address=http://localhost:9876," +
"schema.registry.base.url=http://localhost:8088);");
3.2.2 修改当前的 Catalog
Table API :
tableEnvironment.useCatalog("rocketmq_catalog");SQL:
tableEnvironment.executeSql("USE CATALOG rocketmq_catalog");3.2.3 列出可用的 Catalog
Table API :
String[] catalogs = tableEnvironment.listCatalogs();
SQL:
TableResult tableResult = tableEnvironment.executeSql("show catalogs");3.2.4 列出可用的 Database
Table API :
String[] databases = tableEnvironment.listDatabases();
SQL:
TableResult tableResult = tableEnvironment.executeSql("show databases");3.2.5 列出可用的 Table
Table API:
String[] tables = tableEnvironment.listTables();
SQL:
TableResult tableResult = tableEnvironment.executeSql("show tables");3.3 Quick Start
需要提前准备可用的 RocketMQ 、RocketMQ Schema Registry:
- RocketMQ 部署:https://rocketmq.apache.org/docs/介绍/02quickstart
- RocketMQ Schema Registry 部署:https://github.com/apache/rocketmq-schema-registry
3.3.1 创建 Topic
创建两个 Topic,rocketmq_source 和 rocketmq_sink。

3.3.2 注册 Source Schema
curl -X POST -H "Content-Type: application/json" \\
-d "schemaIdl":"\\"type\\":\\"record\\",\\"name\\":\\"rocketmq_source_schema\\",\\"namespace\\":\\"namespace\\",\\"fields\\":[\\"name\\":\\"name\\",\\"type\\":\\"string\\"]" \\
http://localhost:8088/schema-registry/v1/subject/rocketmq_source/schema/rocketmq_source_schema
3.3.3 注册 Sink Schema
curl -X POST -H "Content-Type: application/json" \\
-d "schemaIdl":"\\"type\\":\\"record\\",\\"name\\":\\"rocketmq_sink_schema\\",\\"namespace\\":\\"namespace\\",\\"fields\\":[\\"name\\":\\"name\\",\\"type\\":\\"string\\"]" \\
http://localhost:8088/schema-registry/v1/subject/rocketmq_sink/schema/rocketmq_sink_schema
3.3.4 添加依赖
创建一个任务项目 ,添加 rocketmq-flink 的依赖 :
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-flink</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
目前 RocketMQ Schema Registry 还没有发布正式的版本,只有快照版,如果发现 jar 找不到,可以尝试以下方法:
<repositories>
<repository>
<id>snapshot-repos</id>
<name>Apache Snapshot Repository</name>
<url>https://repository.apache.org/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
<layout>default</layout>
</repository>
</repositories>
3.3.5 创建任务
/**
* @author lixiaoshuang
*/
public class RocketMqCatalog
public static void main(String[] args)
// 初始化表环境参数
EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().inStreamingMode().build();
// 创建 table 环境
TableEnvironment tableEnvironment = TableEnvironment.create(environmentSettings);
// 注册 rocketmq catalog
tableEnvironment.executeSql(
"CREATE CATALOG rocketmq_catalog WITH (" +
"type=rocketmq_catalog," +
"nameserver.address=http://localhost:9876," +
"schema.registry.base.url=http://localhost:8088);");
tableEnvironment.executeSql("USE CATALOG rocketmq_catalog");
// 从 rocketmq_source 中获取数据写入到 rocketmq_sink 中
TableResult tableResult = tableEnvironment.executeSql("INSERT INTO rocketmq_sink /*+ OPTIONS" +
"(producerGroup=topic_producer_group) */ select * from rocketmq_source /*+ OPTIONS" +
"(consumerGroup=topic_consumer_group) */");
启动任务并运行以后,打开 RocketMQ 控制台,往 rocketmq_source 这个 Topic 发送一条消息。

然后再查看 rocketmq_sink 的状态,就会发现消息已经通过写入到 rocketmq_sink 中了。

以上是关于详解 Flink Catalog 在 ChunJun 中的实践之路的主要内容,如果未能解决你的问题,请参考以下文章