GaussDB(DWS)集群中寻找节点CPU占用高的语句
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GaussDB(DWS)集群中寻找节点CPU占用高的语句相关的知识,希望对你有一定的参考价值。
摘要:本文主要通过实例讲解如何通过gs_cpuwatcher.sh 脚本寻找CPU占用高语句。
本文分享自华为云社区《GaussDB(DWS) gs_cpuwatcher.sh 脚本如何寻找CPU占用高语句》,作者:fighttingman。
【工具名称】
gs_cpuwatcher
【功能描述】
1.寻找集群内节点占用CPU高的语句
【使用场景】
- CPU sys使用率高
- 业务整体慢
【参数说明】
无
【使用方法】
- 直接后台执行命令
nohup sh gs_cpuwatcher.sh > cpuwatcher.log 2>&1 &
执行之前注意事项:
- 使用omm用户(线下)或者Ruby用户(线上)执行
- 将脚本放到一个磁盘空间充足的目录执行,防止把磁盘空间占满,脚本监控会产生日志,占用磁盘空间,磁盘空间最好大于20G
- 监控完之后kill这个监控进程,防止忘记这个脚本造成监控日志一直上涨,脚本默认保留3天的日志
- 脚本只有在进程的cpu使用率大于100(多核累加和)的时候才会进行查询cpu高的语句

【最佳实践&结果分析】
执行监控命令之后,检查当前目录生成的监控日志
查看日志cpu_watch_xxx.log日志,里边有记录占用CPU高的语句
日志里边记录了cpu占用高的语句,例如上图中select * from pg_class a, pg_class,脚本默认截取sql的前50个字符,可以对截取字符串进行修改,需要修改脚本
字段解释:
- dur :执行时长
- start:sql的起始时间
- state_change:sql状态改变时间
- usename:用户名称
- datname:连的数据库名称
- query_id:sql的唯一标识id
- pid:线程id
- client_addr:客户端连的ip
- state:sql的执行状态
- lwtid:线程小号
- wait_status:等待视图中的等待状态字段
- substr:sql字段
教你一招:让集群慢节点无处可藏
摘要:GaussDB在大规模集群上运行的过程中,随着时间推移,部分节点可能会出现性能严重下降的情况。此时这些节点仍然能对外提供服务,但响应明显变慢,处理同样的请求所需时间较其他正常节点大很多,从而影响了整个集群的性能。这样的节点称为“亚健康节点”,或“慢节点”。
本文分享自华为云社区《GaussDB(DWS)新技术 集群慢节点竟然无处可藏》,原文作者:菜花 。
背景
慢实例简介
GaussDB在大规模集群上运行的过程中,随着时间推移,部分节点可能会出现性能严重下降的情况。此时这些节点仍然能对外提供服务,但响应明显变慢,处理同样的请求所需时间较其他正常节点大很多,从而影响了整个集群的性能。这样的节点称为“亚健康节点”,或“慢节点”。
大规模集群中亚健康节点的准确识别本身是一个难题。经过深入观察和分析,我们发现节点响应慢还可能是业务倾斜导致的,例如对某些数据的集中访问,或是某些业务需要较多的运算,导致某些节点的工作量剧增。此外,这样的节点不属于性能低下的慢节点。如果单纯通过响应时间判断慢节点容易导致误判,而频繁的误报警则会降低用户的体验,增加工程人员的排查负担。本特性实现需要在充分考虑业务倾斜等因素的前提下,迅速、准确地识别出慢节点。
慢实例的获取机制
Gauss DB中的等待状态视图pg_thread_wait_status可以显示每个实例上各线程的瞬时状态。通过深入分析其监控原理,结合现网的时间,我们发现通过该视图有效地发现响应慢的节点。平均低来讲,节点响应越慢,上面的等待事件就越多,二者存在正相关,因此可以通过查询该视图中各节点的等待事件数量来衡量节点响应的快慢。根据现网的经验,如果等待状态视图中等待的DN大多数是同一个节点上的DN,则这个节点大概率是慢节点。
以图1所示的工行集群上的等待状态视图查询结果为例,890这个节点上的事件等待数量在连续多次查询中均为全网之冠,且占全网等待数量的比例在50%以上。最终硬件检测表明890节点确实存在硬件故障,导致运行缓慢。
GaussDB的数据节点(Datanode)采用主备模式。如果一个物理机器上的Datanode全是备机,该物理机器并不会直接对外提供服务,也无法通过pg_thread_wait_status视图查询等待事件的数量。但是主DN需要向备DN同步日志。如果这样的“全备机”物理机器恰好是一个慢节点,由于同步日志缓慢,会影响主DN的性能。虽然主机上的pg_thread_wait_status视图等待数量会有所增加,但因为该物理机器对应的主DN被分散到多个物理节点上,单个物理节点上等待数量可能并不能达到阈值。针对这种情况,还需要对等待视图中主DN对应的备DN做进一步计算,间接得到“全备机”物理机器的等待数量。

图1.1 通过等待视图识别慢节点
由于主备切换,数据倾斜等原因,集群中各节点的负载并不均衡,负载高可能也会造成节点响应缓慢。为了避免误报,需要消除负载倾斜对于亚健康节点识别的干扰。为了简化判断,我们进一步假定负载倾斜和故障不会同时出现在同一节点上。也就是说,如果一个节点的负载水平较高,响应慢被认为是正常的,不会被当成慢节点而告警。
节点的负载水平可以通过数据的访问量和运算量来衡量,而后者可以通过IO的数量、消耗CPU时间以及网络数据流量来进行量化计算。GaussDB内部对IO的数量(block数)、CPU时间和网络数据流量进行了打点统计,并通过多种视图呈现出来。通过定期访问这些视图,可以获得节点在单位时间内的工作量,进而获得每个节点在各个时段的负载水平。
与等待事件的数量一样,“全备机”的物理机器的负载水平,也需要通过其对应的主DN的负载水平间接推算。由于备机很少参与运算,主要工作是接收日志,因此主要通过主DN的IO数量和网络流量来衡量备机的繁忙程度。并且由于间接推算的准确性相对较差,只有“全备机”节点才会采用这种方式。只要某台物理机器上有主DN的存在,就直接采用主DN的数据。
对慢实例进行监控
场景分析
根据客户需求分析,可以将客户需求定义为集群中慢节点发生次数与频率的时间序列及详情展示。包含以下主要功能:
- 开启关闭慢实例检测功能
- 配置慢实例检测参数
- 采集慢实例信息上报DMS数据库
- 将慢实例触发次数及慢实例名称等信息以时间序列展示在页面上
方案整体架构设计
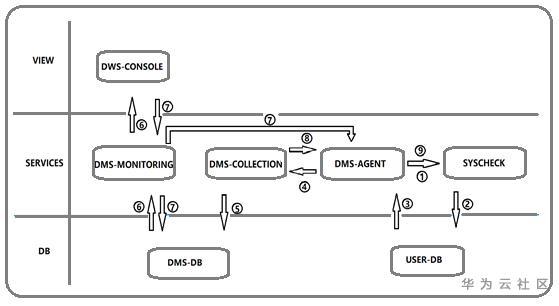
图 2.1 慢实例监控整体架构图
整体方案属于慢实例检测端到端的新增项,并调用健康检查相关模块进行慢实例数据生产。
① dms-agent调用健康检查脚本并传入collection下发的配置参数,主要操作包括初始启动调用,以及进程中断重启调用;
② 健康检查脚本采集慢节点数据到用户数据库中
③ dms-agent通过查库获取相关数据
④ dms-agent根据dms-collection下发的上报频率进行数据上报
⑤ dms-collection接收dms-agent上报的数据进行dms数据库入库等。
⑥ dms-monitoring查询dms数据库获取慢节点数据展示到dws-console前端页面
⑦ dws-console通过dms-monitoring下发启停配置到dms-agent,并通过dms-monitoring将启停信息持久化到dms数据库中; dws-console通过dms-monitor持久化监控参数配置到dms数据库中。
⑧ dms-monitoring将修改后的配置通过grpc下发到dms-agent,dms-agent按照新的上报频率以及配置进行数据采集上报
⑨ dms-agent在配置更新后,按照新配置进行健康检查脚本的重启操作。
慢实例数据详解及数据处理
慢实例表结构设计
drop table if exists dms_mtc_cluster_slow_inst cascade; create table dms_mtc_cluster_slow_inst( ctime bigint not null, -- 采集时间 virtual_cluster_id int not null, -- 虚拟集群id check_time bigint, -- 检测时间 host_id int, -- 主机id host_name varchar(128), -- 主机名 inst_id varchar(64), -- 集群分配的实例id inst_name varchar(128), -- 实例名称 primary key(virtual_cluster_id, inst_id, check_time) );
慢实例数据处理
数据入库Dms-collection接收agent上报的数据进行入库
insert into
dms_mtc_cluster_slow_inst (ctime, virtual_cluster_id, check_time, host_id,host_name, host_id, inst_name)
values
(#{sinst.ctime}, #{ sinst.virtual_cluster_id}, #{sinst.check_time},#{sinst.host_id}, #{sinst.host_name}, #{sinst.inst_id}, #{sinst.inst_name});
数据查询
Dms-monitoring查询慢实例时间序列以及数量
select check_time, count(*) as slow_inst_num from dms_mtc_cluster_slow_inst where virtual_cluster_id = (select virtual_cluster_id from dms_meta_cluster where cluster_id = #{clusterId}) and check_time >= #{from} and check_time <= #{to} group by check_time; Dms-monitoring查询慢实例数据详情 select t1.check_time, t1.host_name, t1.inst_name, t2.trigger_times from (select check_time, host_name, inst_name from dms_mtc_cluster_slow_inst where virtual_cluster_id = ( select virtual_cluster_id from dms_meta_cluster where cluster_id = #{clusterId}) and check_time = #{checkTime}) as t1 inner join (select inst_name, count(*) as trigger_times from dms_mtc_cluster_slow_inst where virtual_cluster_id = (select virtual_cluster_id from dms_meta_cluster where cluster_id = #{clusterId}) and check_time >= (#{checkTime} - 86400000) and check_time <= #{checkTime} group by inst_name) as t2 on t1.inst_name = t2.inst_name;
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料~
以上是关于GaussDB(DWS)集群中寻找节点CPU占用高的语句的主要内容,如果未能解决你的问题,请参考以下文章