四十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
Posted 快乐糖果屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页相关的知识,希望对你有一定的参考价值。
逻辑处理函数
计算搜索耗时
在开始搜索前:start_time = datetime.now()获取当前时间
在搜索结束后:end_time = datetime.now()获取当前时间
last_time = (end_time-start_time).total_seconds()结束时间减去开始时间等于用时,转换成秒

from django.shortcuts import render
# Create your views here.
from django.shortcuts import render,HttpResponse
from django.views.generic.base import View
from app1.models import lagouType # 导入操作elasticsearch(搜索引擎)类
import json
from elasticsearch import Elasticsearch # 导入原生的elasticsearch(搜索引擎)接口
client = Elasticsearch(hosts=["127.0.0.1"]) # 连接原生的elasticsearch
from datetime import datetime
def indexluoji(request):
print(request.method) # 获取用户请求的路径
return render(request, \'index.html\')
def suggestluoji(request): # 搜索自动补全逻辑处理
key_words = request.GET.get(\'s\', \'\') # 获取到请求词
re_datas = []
if key_words:
s = lagouType.search() # 实例化elasticsearch(搜索引擎)类的search查询
s = s.suggest(\'my_suggest\', key_words, completion={
"field": "suggest", "fuzzy": {
"fuzziness": 1
},
"size": 5
})
suggestions = s.execute_suggest()
for match in suggestions.my_suggest[0].options:
source = match._source
re_datas.append(source["title"])
return HttpResponse(json.dumps(re_datas), content_type="application/json")
def searchluoji(request): # 搜索逻辑处理
key_words = request.GET.get(\'q\', \'\') # 获取到请求词
page = request.GET.get(\'p\', \'1\') # 获取访问页码
try:
page = int(page)
except:
page = 1
start_time = datetime.now() # 获取当前时间
response = client.search( # 原生的elasticsearch接口的search()方法,就是搜索,可以支持原生elasticsearch语句查询
index="lagou", # 设置索引名称
doc_type="biao", # 设置表名称
body={ # 书写elasticsearch语句
"query": {
"multi_match": { # multi_match查询
"query": key_words, # 查询关键词
"fields": ["title", "description"] # 查询字段
}
},
"from": (page-1)*10, # 从第几条开始获取
"size": 10, # 获取多少条数据
"highlight": { # 查询关键词高亮处理
"pre_tags": [\'<span class="keyWord">\'], # 高亮开始标签
"post_tags": [\'</span>\'], # 高亮结束标签
"fields": { # 高亮设置
"title": {}, # 高亮字段
"description": {} # 高亮字段
}
}
}
)
end_time = datetime.now() # 获取当前时间
last_time = (end_time-start_time).total_seconds() # 结束时间减去开始时间等于用时,转换成秒
total_nums = response["hits"]["total"] # 获取查询结果的总条数
if (page % 10) > 0: # 计算页数
paga_nums = int(total_nums/10)+1
else:
paga_nums = int(total_nums/10)
hit_list = [] # 设置一个列表来储存搜索到的信息,返回给html页面
for hit in response["hits"]["hits"]: # 循环查询到的结果
hit_dict = {} # 设置一个字典来储存循环结果
if "title" in hit["highlight"]: # 判断title字段,如果高亮字段有类容
hit_dict["title"] = "".join(hit["highlight"]["title"]) # 获取高亮里的title
else:
hit_dict["title"] = hit["_source"]["title"] # 否则获取不是高亮里的title
if "description" in hit["highlight"]: # 判断description字段,如果高亮字段有类容
hit_dict["description"] = "".join(hit["highlight"]["description"])[:500] # 获取高亮里的description
else:
hit_dict["description"] = hit["_source"]["description"] # 否则获取不是高亮里的description
hit_dict["url"] = hit["_source"]["url"] # 获取返回url
hit_list.append(hit_dict) # 将获取到内容的字典,添加到列表
return render(request, \'result.html\', {"page": page, # 当前页码
"total_nums": total_nums, # 数据总条数
"all_hits": hit_list, # 数据列表
"key_words": key_words, # 搜索词
"paga_nums": paga_nums, # 页数
"last_time": last_time # 搜索时间
}) # 显示页面和将列表和搜索词返回到html
HTML
<!DOCTYPE html >
<html xmlns="http://www.w3.org/1999/xhtml">
{#引入静态文件路径#}
{% load staticfiles %}
<head>
<meta http-equiv="X-UA-Compatible" content="IE=emulateIE7" />
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>python-lcv-search搜索引擎</title>
<link href="{% static \'css/style.css\'%}" rel="stylesheet" type="text/css" />
<link href="{% static \'css/result.css\'%}" rel="stylesheet" type="text/css" />
</head>
<body>
<div id="container">
<div id="hd" class="ue-clear">
<a href="/"><div class="logo"></div></a>
<div class="inputArea">
<input type="text" class="searchInput" value="{{ key_words }}"/>
<input type="button" class="searchButton" onclick="add_search()"/>
</div>
</div>
<div class="nav">
<ul class="searchList">
<li class="searchItem current" data-type="article">文章</li>
<li class="searchItem" data-type="question">问答</li>
<li class="searchItem" data-type="job">职位</li>
</ul>
</div>
<div id="bd" class="ue-clear">
<div id="main">
<div class="sideBar">
<div class="subfield">网站</div>
<ul class="subfieldContext">
<li>
<span class="name">伯乐在线</span>
<span class="unit">(None)</span>
</li>
<li>
<span class="name">知乎</span>
<span class="unit">(9862)</span>
</li>
<li>
<span class="name">拉勾网</span>
<span class="unit">(9862)</span>
</li>
<li class="more">
<a href="javascript:;">
<span class="text">更多</span>
<i class="moreIcon"></i>
</a>
</li>
</ul>
<div class="sideBarShowHide">
<a href="javascript:;" class="icon"></a>
</div>
</div>
<div class="resultArea">
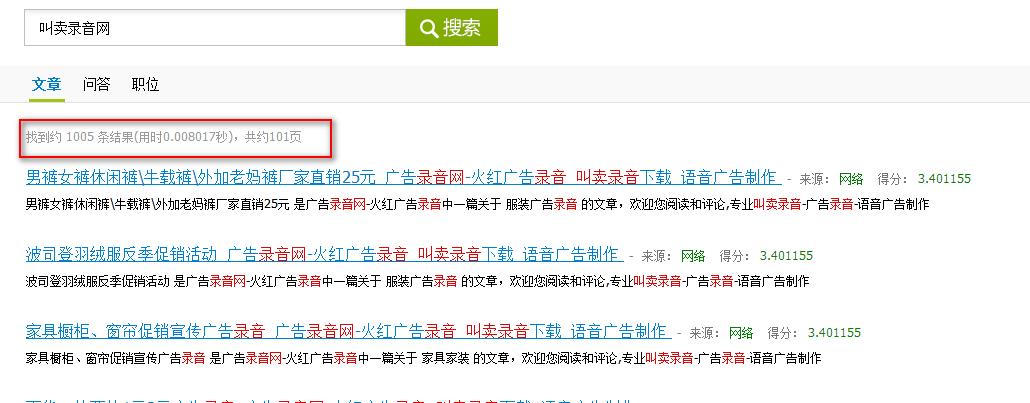
<p class="resultTotal">
<span class="info">找到约 <span class="totalResult">{{ total_nums }}</span> 条结果(用时<span class="time">{{ last_time }}</span>秒),共约<span class="totalPage">{{ paga_nums }}</span>页</span>
</p>
<div class="resultList">
{% for hit in all_hits %}
<div class="resultItem">
<div class="itemHead">
<a href="{% autoescape off %} {{ hit.url }} {% endautoescape %}" target="_blank" class="title">{% autoescape off %} {{ hit.title }} {% endautoescape %}</a>
<span class="divsion">-</span>
<span class="fileType">
<span class="label">来源:</span>
<span class="value">网络</span>
</span>
<span class="dependValue">
<span class="label">得分:</span>
<span class="value">3.401155</span>
</span>
</div>
<div class="itemBody">
{% autoescape off %} {{ hit.description }} {% endautoescape %}
</div>
</div>
{% endfor %}
</div>
<!-- 分页 -->
<div class="pagination ue-clear"></div>
<!-- 相关搜索 -->
</div>
<div class="historyArea">
<div class="hotSearch">
<h6>热门搜索</h6>
<ul class="historyList">
<li><a href="/search?q=linux">linux</a></li>
</ul>
</div>
<div class="mySearch">
<h6>我的搜索</h6>
<ul class="historyList">
</ul>
</div>
</div>
</div><!-- End of main -->
</div><!--End of bd-->
</div>
<div id="foot">Copyright ©projectsedu.com 版权所有 E-mail:admin@projectsedu.com</div>
</body>
<script type="text/javascript" src="{% static \'js/jquery.js\'%}"></script>
<script type="text/javascript" src="{% static \'js/global.js\'%}"></script>
<script type="text/javascript" src="{% static \'js/pagination.js\'%}"></script>
<script type="text/javascript">
var search_url = "/search/"
$(\'.searchList\').on(\'click\', \'.searchItem\', function(){
$(\'.searchList .searchItem\').removeClass(\'current\');
$(this).addClass(\'current\');
});
$.each($(\'.subfieldContext\'), function(i, item){
$(this).find(\'li:gt(2)\').hide().end().find(\'li:last\').show();
});
function removeByValue(arr, val) {
for(var i=0; i<arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
$(\'.subfieldContext .more\').click(function(e){
var $more = $(this).parent(\'.subfieldContext\').find(\'.more\');
if($more.hasClass(\'show\')){
if($(this).hasClass(\'define\')){
$(this).parent(\'.subfieldContext\').find(\'.more\').removeClass(\'show\').find(\'.text\').text(\'自定义\');
}else{
$(this).parent(\'.subfieldContext\').find(\'.more\').removeClass(\'show\').find(\'.text\').text(\'更多\');
}
$(this).parent(\'.subfieldContext\').find(\'li:gt(2)\').hide().end().find(\'li:last\').show();
}else{
$(this).parent(\'.subfieldContext\').find(\'.more\').addClass(\'show\').find(\'.text\').text(\'收起\');
$(this).parent(\'.subfieldContext\').find(\'li:gt(2)\').show();
}
});
$(\'.sideBarShowHide a\').click(function(e) {
if($(\'#main\').hasClass(\'sideBarHide\')){
$(\'#main\').removeClass(\'sideBarHide\');
$(\'#container\').removeClass(\'sideBarHide\');
}else{
$(\'#main\').addClass(\'sideBarHide\');
$(\'#container\').addClass(\'sideBarHide\');
}
});
var key_words = "{{ key_words }}"
//分页
$(".pagination").pagination({{ total_nums }}, {
current_page :{{ page|add:\'-1\' }}, //当前页码
items_per_page :10,
display_msg :true,
callback :pageselectCallback
});
function pageselectCallback(page_id, jq) {
window.location.href=search_url+\'?q=\'+key_words+\'&p=\'+page_id
}
setHeight();
$(window).resize(function(){
setHeight();
});
function setHeight(){
if($(\'#container\').outerHeight() < $(window).height()){
$(\'#container\').height($(window).height()-33);
}
}
</script>
<script type="text/javascript">
$(\'.searchList\').on(\'click\', \'.searchItem\', function(){
$(\'.searchList .searchItem\').removeClass(\'current\');
$(this).addClass(\'current\');
});
// 联想下拉显示隐藏
$(\'.searchInput\').on(\'focus\', function(){
$(\'.dataList\').show()
});
// 联想下拉点击
$(\'.dataList\').on(\'click\', \'li\', function(){
var text = $(this).text();
$(\'.searchInput\').val(text);
$(\'.dataList\').hide()
});
hideElement($(\'.dataList\'), $(\'.searchInput\'));
</script>
<script>
var searchArr;
//定义一个search的,判断浏览器有无数据存储(搜索历史)
if(localStorage.search){
//如果有,转换成 数组的形式存放到searchArr的数组里(localStorage以字符串的形式存储,所以要把它转换成数组的形式)
searchArr= localStorage.search.split(",")
}else{
//如果没有,则定义searchArr为一个空的数组
searchArr = [];
}
//把存储的数据显示出来作为搜索历史
MapSearchArr();
function add_search(){
var val = $(".searchInput").val();
if (val.length>=2){
//点击搜索按钮时,去重
KillRepeat(val);
//去重后把数组存储到浏览器localStorage
localStorage.search = searchArr;
//然后再把搜索内容显示出来
MapSearchArr();
}
window.location.href=search_url+\'?q=\'+val+"&s_type="+$(".searchItem.current").attr(\'data-type\')
}
function MapSearchArr(){
var tmpHtml = "";
var arrLen = 0
if (searchArr.length > 6){
arrLen = 6
}else {
arrLen = searchArr.length
}
for (var i=0;i<arrLen;i++){
tmpHtml += \'<li><a href="/search?q=\'+searchArr[i]+\'">\'+searchArr[i]+\'</a></li>\'
}
$(".mySearch .historyList").append(tmpHtml);
}
//去重
function KillRepeat(val){
var kill = 0;
for (var i=0;i<searchArr.length;i++){
if(val===searchArr[i]){
kill ++;
}
}
if(kill<1){
searchArr.unshift(val);
}else {
removeByValue(searchArr, val)
searchArr.unshift(val)
}
}
</script>
</html>
结果:

以上是关于四十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页的主要内容,如果未能解决你的问题,请参考以下文章