[重读经典论文]ResNext
Posted 大师兄的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[重读经典论文]ResNext相关的知识,希望对你有一定的参考价值。
1. 前言
ResNeXt是由何凯明团队在论文《Aggregated Residual Transformations for Deep Neural Networks》提出来的新型图像分类网络。
ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的概念,其实本质上就是将Res模块中的卷积分支换成分组卷积,然后探索分组卷积的最佳组数(C)和每个分组的卷积核个数(d),通过改进resnet网络,通过各种消融实验,得出了最佳的模型结构。
在ILSVRC 2016分类竞赛中Top5错误率达到3.03%,获得亚军。
2. 解决什么问题
作者首先提出现在随着深度学习的发展,CV已经由原来的“特征工程”转为“网络工程”了,架构越来越复杂,超参数也越来越多。然后提到Inception网络,虽然迭代了很多次,但是终究可以归纳为一个模式:split-transform-merge。
然后踩了一下Inception,就是它太复杂了,人工设计的成分太大了,有太多超参要调,也不见得能适应新的数据和任务。
然后,分析了神经网络的标准范式就符合这样的split-transform-merge模式。以一个最简单的普通神经元为例(比如FC中的每个神经元):

将输入X拆分(splitting)到个一个低维的嵌入,也就是一维的子空间xi,然后对这些低维的表示进行转换(transforing),也就是乘以wi,最后再将结果进行聚合求和(aggregating),这个过程可以用以下公式表示:

由此归纳出神经网络的一个通用的单元可以用如下公式表示:

结合ResNet的identity映射,带residual的结构可以用如下公式表示:

上面的变换T可以是任意形式,在这篇文章中每个分支的拓扑结构T都是一样的, 一共有C个独立的变换,作者将C称之为基数,并且指出,基数C对于结果的影响比宽度和深度更加重要,而且这样的结构易于拓展。
3. 什么是分组卷积
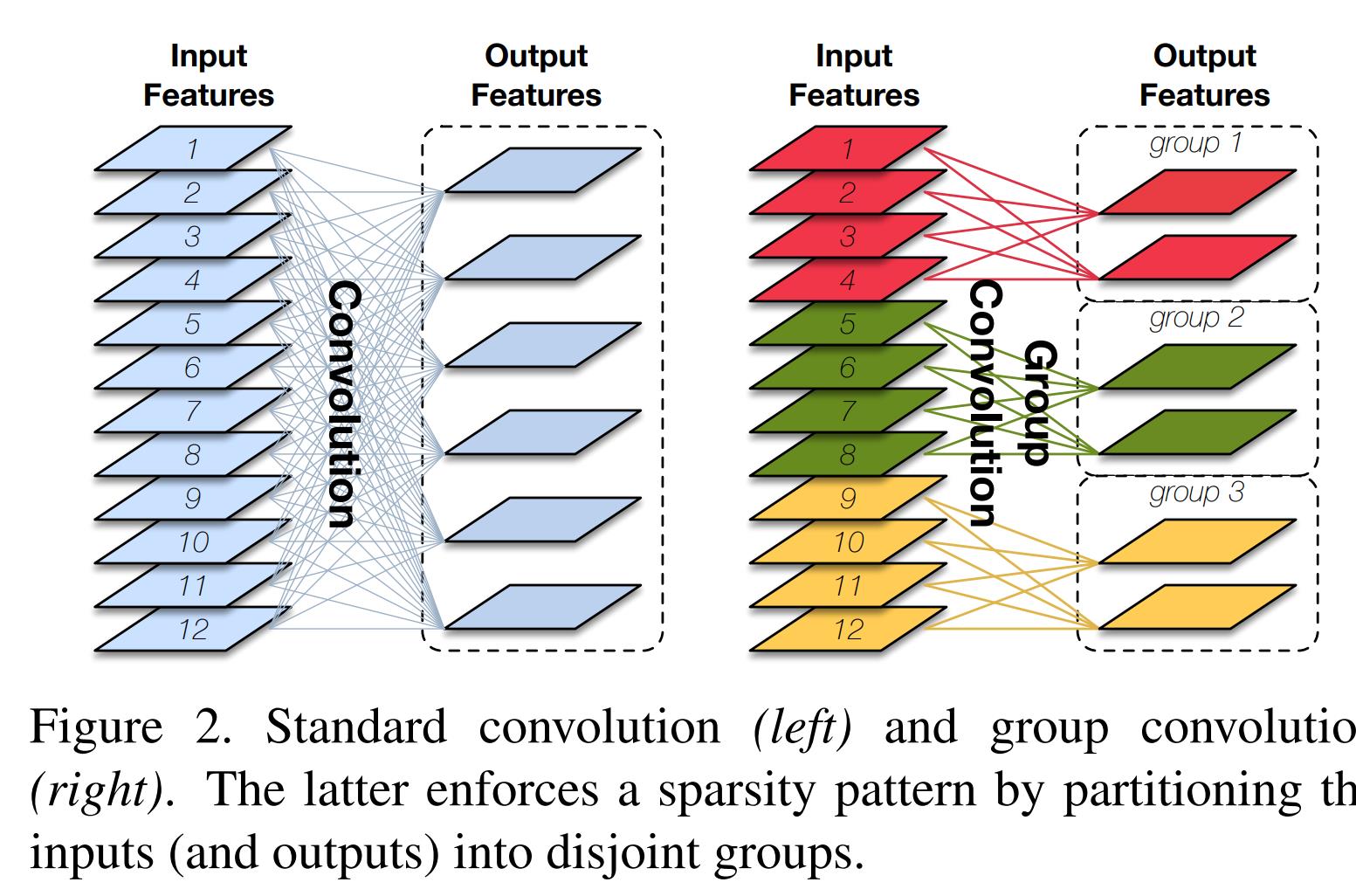
如上图所示,左边是普通的卷积,一个卷积核需要处理输入的所有通道,输入为12通道,则卷积核的形状为k*k*12;右边则为分组卷积,如图右所示,将输入分为三组,每组有4个通道,每组的卷积核只需要处理当组的输入即可,则卷积核的形状为k*k*4。
归纳来说,假如输入的通道为Cin,卷积后的输出通道为n,则
普通卷积,卷积核的形状为k*k*Cin,需要输出n个通道,则需要n个卷积核,因此参数量为k*k*Cin*n;
分组卷积:分组数为g,则卷积核的形状为k*k*Cin/g,输出n个通道,则每个分组输出n/g个通道,每组需要n/g个卷积核,则参数量为(k*k*Cin/g*n/g)*g,化简为k*k*Cin*n*1/g,为普通卷积的1/g倍。

因此,分组的卷积的明显优点是降低了参数量与计算,减少内存占用,加快推断速度。
缺点也很明显,分组卷积的组和组之间是没有信息交流的,会导致类型近亲繁殖的现象,无法更好提取特征,导致性能下降。
4. ResNext模块结构

如上图所示,图左为原始的Resnet结构基本结构,右边是ResNext的基本机构,作者在设计模块的时候遵循了两点原则:
- 如果输入输出的尺寸是一样的,则这些模块的超参都是一样的(宽度和filter尺寸)。
- 如果输出尺寸减半的时候,通道翻倍。
其实也就是Vgg和ResNet的规则。
可以看到,旁边的residual connection就是公式中的x直接连过来,然后剩下的是32组独立的同样结构的变换,最后再进行融合,符合split-transform-merge的模式。
作者进一步指出,split-transform-merge是通用的神经网络的标准范式,前面已经提到,基本的神经元符合这个范式,而如下图所示:

上面这三个模块其实是等价的,最后出于实现的简易性选择了上图中的c模块,即分组卷积,可以知道中间的模块,分了32组,由于输出的通道数为128,因此每组的卷积核个数为4。
5. 网络结构
作者在ResNet的基础上进行修改,将每个stage替换成分组卷积,其中32代表ResNext模块中的第二个卷积的分组数为32组,每一组的卷积核的个数为4个,如下表所示:

可以看到两个网络的参数和计算量都差不多,但是在后面的测试中,ResNext性能更好:

上表也是作者对C和分组数量d进行的消融实验,可以发现随着C提高,性能也逐渐提高,权衡参数量和计算复杂度,最后选择了32x4d的组合。
后面还试着把block的残差连接去掉,发现性能严重下降,为了说明残差能够真正帮助网络进行学习,不是没有的(diss 了InceptionV4那篇论文)。
6. 总结
总的来说,本文总结了Inception和ANN的结构,从很高的逼格上提出了split-transform-merge这么一种范式,并基于这种范式提出一种相同拓扑多分支的结构,并归纳为分组卷积的模式,简洁、高效,易于调试。
7. 参考
[1] 6.1.2 ResNeXt网络结构
[2] 深度学习——分类之ResNeXt
(完)
CIFAR和SVHN在各CNN论文中的结果
CIFAR和SVHN结果
- 加粗表示原论文中该网络的最优结果。
- 可以看出DenseNet-BC优于ResNeXt优于DenseNet优于WRN优于FractalNet优于ResNetv2优于ResNet。
- ResNeXt-29,8x64d表示29层,ResNeXt分支数为8,每个分支的bottleneck宽度为64。
- 这里记录的结果是使用了标准数据增强的test error。
- 因为有些论文会拿前人工作的次优结果对比,所以这些结果可能会和一些论文的实验数据有所出入。
| 网络 | 网络参数 | CIFAR10 | CIFAR100 | SVHN | 备注 |
|---|---|---|---|---|---|
| ResNet-110 | 1.7M | 6.61 | |||
| ResNet-110 | 1.7M | 6.41 | 27.22 | 2.01 | 黄高复现 |
| ResNet-164 | 1.7M | 25.16 | resNetv2提中提到的 | ||
| ResNetv2-164 | 1.7M | 5.46 | 24.33 | ||
| ResNetv2-1001 | 10.2M | 4.69 | 22.68 | ||
| FractalNet-20 with drop | 38.6M | 4.60 | 1.87 | ||
| FractalNet-40 | 22.9M | 22.49 | |||
| WRN-40-4 | 8.9M | 4.53 | 21.18 | ||
| WRN-16-8 | 11.0M | 4.27 | 20.43 | ||
| WRN-28-10 | 36.5M | 4.00 | 19.25 | ||
| WRN-28-10 dropout | 36.5M | 3.89 | 18.85 | ||
| WRN-16-4 dropout | 1.64 | ||||
| ResNeXt-29,8x64d | 34.4M | 3.65 | 17.77 | ||
| ResNeXt-29,16x64d | 68.1M | 3.58 | 17.31 | ||
| DenseNet-40(k=12) | 1.0M | 5.24 | 24.42 | 1.79 | |
| DenseNet-100(k=12) | 7.0M | 4.10 | 20.20 | 1.67 | |
| DenseNet-100(k=24) | 27.2M | 3.74 | 19.25 | 1.59 | |
| DenseNet-BC-100(k=12) | 0.8M | 4.51 | 22.27 | 1.76 | |
| DenseNet-BC-250(k=24) | 15.3M | 3.62 | 17.60 | 1.74 | |
| DenseNet-BC-190(k=40) | 25.6M | 3.46 | 17.18 |
以上是关于[重读经典论文]ResNext的主要内容,如果未能解决你的问题,请参考以下文章