生产事故-记一次特殊的OOM排查
Posted 程语有云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生产事故-记一次特殊的OOM排查相关的知识,希望对你有一定的参考价值。
入职多年,面对生产环境,尽管都是小心翼翼,慎之又慎,还是难免捅出篓子。轻则满头大汗,面红耳赤。重则系统停摆,损失资金。每一个生产事故的背后,都是宝贵的经验和教训,都是项目成员的血泪史。为了更好地防范和遏制今后的各类事故,特开此专题,长期更新和记录大大小小的各类事故。有些是亲身经历,有些是经人耳传口授,但无一例外都是真实案例。
注意:为了避免不必要的麻烦和商密问题,文中提到的特定名称都将是化名、代称。
0x00 大纲
0x01 事故背景
2023年3月10日14时19分,C公司开发人员向A公司开发人员反映某开放接口从2023年3月10日14时许开始无法访问和使用。该系统为某基础数据接口服务,基于 HTTP 协议进行通信。按照惯例,首先排查网络是否异常,经运维人员检查,证明网络连通性没有问题。A公司开发组于2023年3月10日14时30分通知运维人员重启应用服务,期间短暂恢复正常。但是,很快,十分钟后,电话再次响起,告知服务又出现异常,无法访问。为了避免影响进一步扩大,A公司决定将程序紧急回滚至上一稳定版本。回滚后,系统业务功能恢复正常。短暂松一口气后,开始排查问题。
0x02 事故分析
让运维拷贝和固定了更新前后的系统日志和应用包。根据前面的故障现象,初步猜测是内存问题,好在应用启停脚本中增加了参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/app/logs/app.dump(对于无法在生产环境上使用jstack、jmap等命令直接查错的——事实上大多数时候都不能,dump文件显得尤为重要),果不其然,日志目录下出现了app.dump文件,在日志中搜索,找到了若干处内存溢出错误java.lang.OutOfMemoryError: Java heap space,但是令人费解的是每次出现OOM错误的位置居然都不一样,事情逐渐变得复杂起来。
用MAT(Memory Analyzer Tool)工具打开转储文件,原以为会发现某个类型对象占用大量的内存,结果出乎意料,Histogram(直方图)中显示活跃对象居然只有100多M!尝试 Calculate Precise Retained Size(计算精确大小),计算结果与前面相差不大。检查 Outgoing References (追踪引用对象)和 Incoming References(追踪被引用对象)也未见明显异常,令人头大。
擦擦汗,日志已经明确提示我们java.lang.OutOfMemoryError: Java heap space,首先肯定这是一个堆内存空间引起的问题,可能的原因有:
-
内存加载数据量过大
例如不受行数限制的数据库查询语句,或者不限制字节数的文件读取等,事故系统显然没有这些情况;
-
内存泄漏(资源未关闭/无法回收)
当系统存在大量未关闭的 IO 资源,或者错误使用
ThreadLocal等场景时也会发生OOM,经排查,也不存在这种情况; -
系统内存不足
系统内存不足以支撑当前业务场景所需要的内存,过小的机器内存或者不合理的JVM内存参数。
如果排除所有合理选项,最不合理那个会不会就是答案呢?遂开始检查机器的内存,根据运维的说法,机器内存为16GB,top命令查看java进程占用内存约为7.8GB,看起来似乎没毛病。
但是随后另一个同事注意到了一个事情,最后一次系统升级的时候,改动过应用启停脚本,对比旧版本的脚本,发现差异部分就是内存参数:
旧版本原为:
-Xms8g -Xmx8g -Xmn3g
新版本改为:
-Xms8g -Xmx8g -Xmn8g
看到这里,屏幕前的一众同事都无语啊……
0x03 事故原因
为什么-Xmn参数设置成与-Xmx参数一样的大小会导致OOM呢?该项目使用的JDK版本为1.8,看看JDK 8的内存模型:

不难发现,Heap Space Size = Young Space Size + Old Space Size,而-Xmn参数控制的正是 Young 区的大小,当堆区被 Young Gen 完全挤占,又有对象想要升代到 Old Gen 时,发现 Old 区空间不足,于是触发 Full GC,触发 Full GC 以后呢,通常又会面临两种情况:
- Young 区又刚好腾出来一点空间,对象又不用放到 Old 区里面了,皆大欢喜
- Young 区空间还是不够,对象还是得放到 Old 区,Old 区空间不够,卒,喜提
OOM - 诶,就是奔着 Old 区去的,管你 Young 不 Young,Old 区空间不够,卒,喜提
OOM
这个就解释了为什么系统刚刚启动时,会有一个短时间正常工作的现象,随后,当某段程序触发 Old Gen 升代时,就会发生随机的OOM错误。那么什么时候对象会进入老年代呢?这里也很有意思,不妨结合日志里面出现OOM的地方,对号入座:
- 经历足够多次数 GC 依然存活的对象
- 申请一个大对象(比如超过 Eden 区一半大小)
- GC 后 Eden 区对象大小超过 S 区之和
- Eden 区 + S0 区 GC 后,S1 区放不下
换言之,正常情况下,-Xmn参数总是应当小于-Xmx参数,否则就会触发OOM错误。我们可以构造一个简单的例子来验证这个场景。首先是一个简单的SpringBoot程序:
package com.example.oom;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Random;
@SpringBootApplication
public class OomApplication
static final byte[] ARRAY = new byte[128 * 1024 * 1024];
public static void main(String[] args)
SpringApplication.run(OomApplication.class, args);
@RestController
public static class OomExampleController
@GetMapping("/oom")
public int oom()
byte[] temp = new byte[128 * 1024 * 1024];
temp[0] = (byte) 0xff;
temp[temp.length - 1] = (byte) 0xef;
int noise = new Random().nextInt();
ARRAY[0] = (byte) (temp[0] + temp[temp.length - 1] + noise);
return ARRAY[0];
使用mvn clean package命令打包后,我们用下面的命令启动它:
java -Xms512m -Xmx512m -Xmn512m -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar oom-1.0.0-RELEASE.jar
然后借助Apache的ab.exe,完成我们的验证测试。先是以1个并发访问100次上面的SpringBoot接口:
ab -c 1 -n 100 http://localhost:8080/oom
你会发现,它居然是可以正常运行的,然后我们模拟用户负载上来之后的情况,使用2个并发访问100次:
ab -c 2 -n 100 http://localhost:8080/oom
如果前面的步骤都没错,此时应该在SpringBoot应用控制台看到大量的OOM错误,如下图所示:
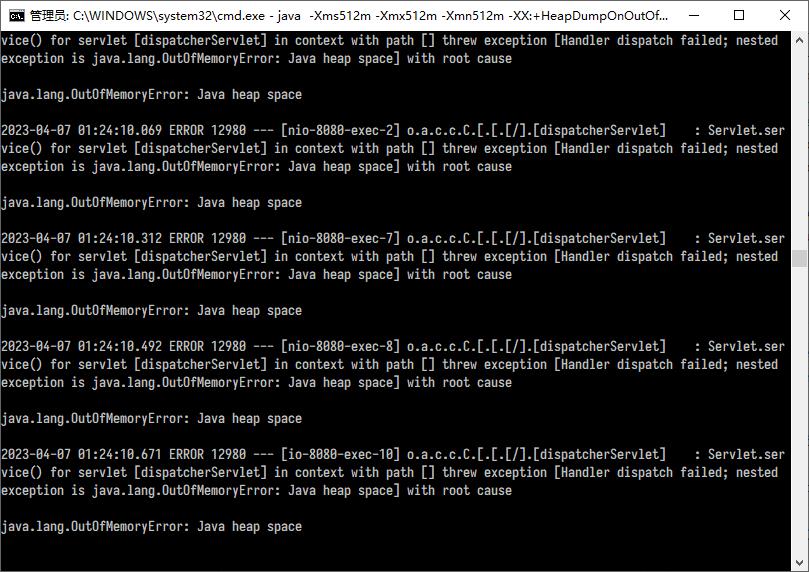
然后在 GC 日志里面会看到,触发 GC 的前后,Old 区几乎都没有空间,仅有的一点点还是JDK强行分配的(在启动JVM时强制覆写了我们的-Xmn参数):
Heap before GC invocations=279 (full 139):
PSYoungGen total 458752K, used 273877K [0x00000000e0080000, 0x0000000100000000, 0x0000000100000000)
eden space 393728K, 69% used [0x00000000e0080000,0x00000000f0bf5798,0x00000000f8100000)
from space 65024K, 0% used [0x00000000fc080000,0x00000000fc080000,0x0000000100000000)
to space 65024K, 0% used [0x00000000f8100000,0x00000000f8100000,0x00000000fc080000)
ParOldGen total 512K, used 506K [0x00000000e0000000, 0x00000000e0080000, 0x00000000e0080000)
object space 512K, 98% used [0x00000000e0000000,0x00000000e007e910,0x00000000e0080000)
Metaspace used 35959K, capacity 38240K, committed 38872K, reserved 1083392K
class space used 4533K, capacity 4953K, committed 5080K, reserved 1048576K
2023-04-07T01:44:25.348+0800: 57.446: [GC (Allocation Failure) --[PSYoungGen: 273877K->273877K(458752K)] 274384K->274384K(459264K), 0.0441401 secs] [Times: user=0.06 sys=0.30, real=0.04 secs]
Heap after GC invocations=279 (full 139):
PSYoungGen total 458752K, used 273877K [0x00000000e0080000, 0x0000000100000000, 0x0000000100000000)
eden space 393728K, 69% used [0x00000000e0080000,0x00000000f0bf5798,0x00000000f8100000)
from space 65024K, 0% used [0x00000000fc080000,0x00000000fc080000,0x0000000100000000)
to space 65024K, 9% used [0x00000000f8100000,0x00000000f86e2070,0x00000000fc080000)
ParOldGen total 512K, used 506K [0x00000000e0000000, 0x00000000e0080000, 0x00000000e0080000)
object space 512K, 98% used [0x00000000e0000000,0x00000000e007e910,0x00000000e0080000)
Metaspace used 35959K, capacity 38240K, committed 38872K, reserved 1083392K
class space used 4533K, capacity 4953K, committed 5080K, reserved 1048576K
Heap before GC invocations=280 (full 140):
PSYoungGen total 458752K, used 273877K [0x00000000e0080000, 0x0000000100000000, 0x0000000100000000)
eden space 393728K, 69% used [0x00000000e0080000,0x00000000f0bf5798,0x00000000f8100000)
from space 65024K, 0% used [0x00000000fc080000,0x00000000fc080000,0x0000000100000000)
to space 65024K, 9% used [0x00000000f8100000,0x00000000f86e2070,0x00000000fc080000)
ParOldGen total 512K, used 506K [0x00000000e0000000, 0x00000000e0080000, 0x00000000e0080000)
object space 512K, 98% used [0x00000000e0000000,0x00000000e007e910,0x00000000e0080000)
Metaspace used 35959K, capacity 38240K, committed 38872K, reserved 1083392K
class space used 4533K, capacity 4953K, committed 5080K, reserved 1048576K
2023-04-07T01:44:25.392+0800: 57.490: [Full GC (Ergonomics) [PSYoungGen: 273877K->142631K(458752K)] [ParOldGen: 506K->506K(512K)] 274384K->143137K(459264K), [Metaspace: 35959K->35959K(1083392K)], 0.0248171 secs] [Times: user=0.14 sys=0.00, real=0.03 secs]
接着无需改动任何代码,我们调整下启动参数,像这样:
java -Xms512m -Xmx512m -Xmn64m -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar oom-1.0.0-RELEASE.jar
你会发现它又可以了。这是一个为了验证而打造的极端例子,实际上生产的应用情况会比这个复杂得多,但这并不妨碍我们理解它的意图。
0x04 事故复盘
这是一场典型的”人祸“,来源于某个同事的”调优“,比起追究责任,更重要的是带给我们的启发:
- 即使是应用启停脚本,也应该作为程序的一部分,纳入测试验证流程和上线检查清单,禁止随意变更;
- 很多时候,默认的就是最好的,矫枉则常常过正。
0x05 事故影响
造成C公司关键业务停摆半小时,生产系统紧急回滚一次。A公司相关负责人连夜编写事故报告一份。
记一次生产kafka消息消费的事故
事故背景:
我们公司与合作方公司有个消息同步的需求,合作方是消息生产者,我们是消息消费者,他们通过kafka给我们推送消息,我们实时接收,然后进行后续业务处理。昨天上午,发现他们推送过来的广场门店信息我们都没有消费,导致我们系统和他们系统数据不一致,从而导致无法提单,无法出报表(报表有误)等各种问题
排查过程:
(1)因为coco身体不适,上午请假去医院了,所以这个问题就转给我们team的专门运维的同事了,电话大概给他说明了代码路径,可惜,半天下来仍然无果,看着微信群里他发的消息,我有点抓狂,根本没有找到点上,半天了没查出原因,我们业务端也顶着压力,一个劲儿地给我打电话。
(2)中午12:30点,coco回到公司,立马开电脑开始排查,让他们重新推送消息,查看日志,发现我们根本没有消费到。初步判断,应该不是我们客户端的问题,初步定位原因:a.网络问题;b.网络丢包;c.生产者生产机制有问题,实际没有推送过来。
(3)因为之前一直是好好的,近期这个需求也没有做过任何改动,网络也是通的,感觉可能不是网络的问题,但是也要排查,因为这个已经是去年年初的需求了,原熟悉这块业务的人早已离职,所以排查起来有点慢。我们公司在合作公司面前又没多大话语权,每次有问题都是直接甩锅给我们,每次排查出来都是他们的问题。这次,我让他们先排查自身问题,他们依然说,不是他们的原因等等。
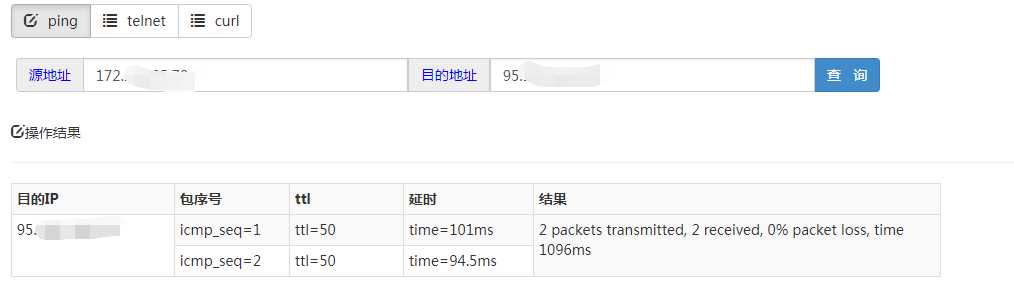
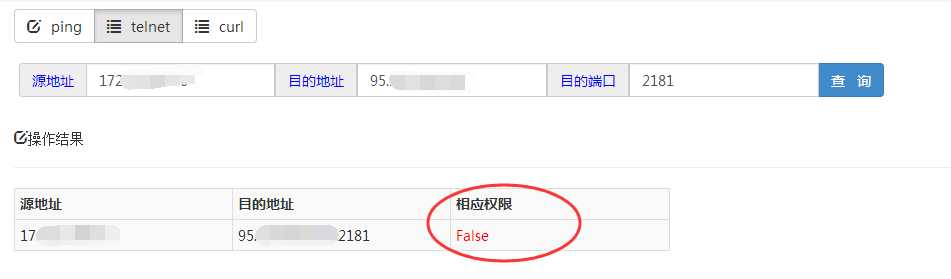
(4)网络排查:根据代码,查出我们连接生产者zookeeper的集群地址。然后我找到我们应用所在主机IP。ping了下是通的。但是telnet端口的时候明显就不通了,很明显的网络问题啊。截图给对方,他们依然不认,说自己测试都是ok的,coco此时心里真的是一万个mmp啊,然而,脸上还要笑嘻嘻……为啥之前一直通的,突然就有问题了呢,让对方研发问他们那边最近有没有做过网络调整,那哥们直接说没有……涉及公司与公司间的网络权限,肯定要走流程去申请啦。我就去找我们这边网络组的老大,把事故简要地说明了下,他说,合作方公司前几天有下线过一批主机呀,我联系他们,包不包含这几台,此刻,我的心里大石头终于放下了,找对人了。
ping的结果:
telnet的结果:
(5)后来,在这个leader、我们项目经理的协调下,找了对方公司的网管,确认是他们近期做了网络调整导致的。然后,对方公司对接人去提了网络申请,该问题算是初步得到了解决,下午2:40左右,网络给打开了,把这几天的存量数据又重新推送了一次。
结论:
对于生产正在用的接口,一直好好的,突然出问题,如果是全量问题,首先要排查网络问题,如果是部分数据有问题,则要考虑是否是网络丢包,是否是消息丢失。
复盘:
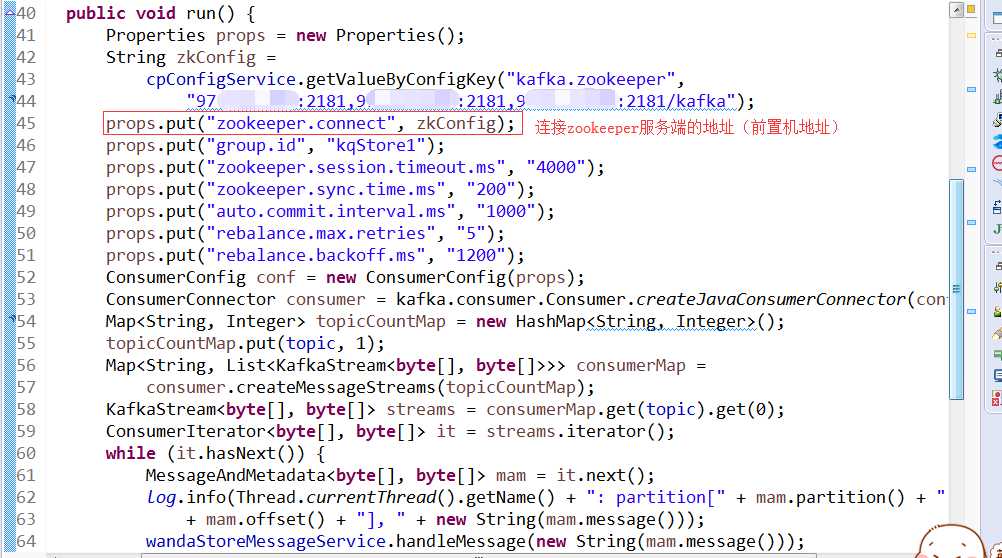
其实,这个问题真的从根源上解决了吗?并没有,根据生产日志,查询得知,自6.5日开始,就没有消费过消息了,说明6.5号就有问题了啊。我们系统也没有报异常,没有通知到负责人,为什么消费者连不上生产者zookeeper主机的时候,仍不报异常呢,这个coco还在排查。
ConsumerConfig conf = new ConsumerConfig(props);
//连不通但是没有报异常
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(conf);
代码:
以上是关于生产事故-记一次特殊的OOM排查的主要内容,如果未能解决你的问题,请参考以下文章