使用python处理实验数据-yechen_pro_20171231
Posted 痴道三
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用python处理实验数据-yechen_pro_20171231相关的知识,希望对你有一定的参考价值。
整体思路
1.观察文档结构:
- 工况之一
- 流量一28
- 测点位置=0
-测点纵断面深度-1
-该点数据Speedxxxxxxxx.txt
-测点纵断面深度-2
-测点纵断面深度-3
-...
- 测点位置=0.625D
- 测点位置=1.75D
-...
- 流量一48
- 测点位置=0
-...
- 工况之二
- 流量一28
- 流量一48
- 工况之三
-...
- ....
2.观察数据结构:
有用的数据为合速度之前的数据,数据量大约为2000行。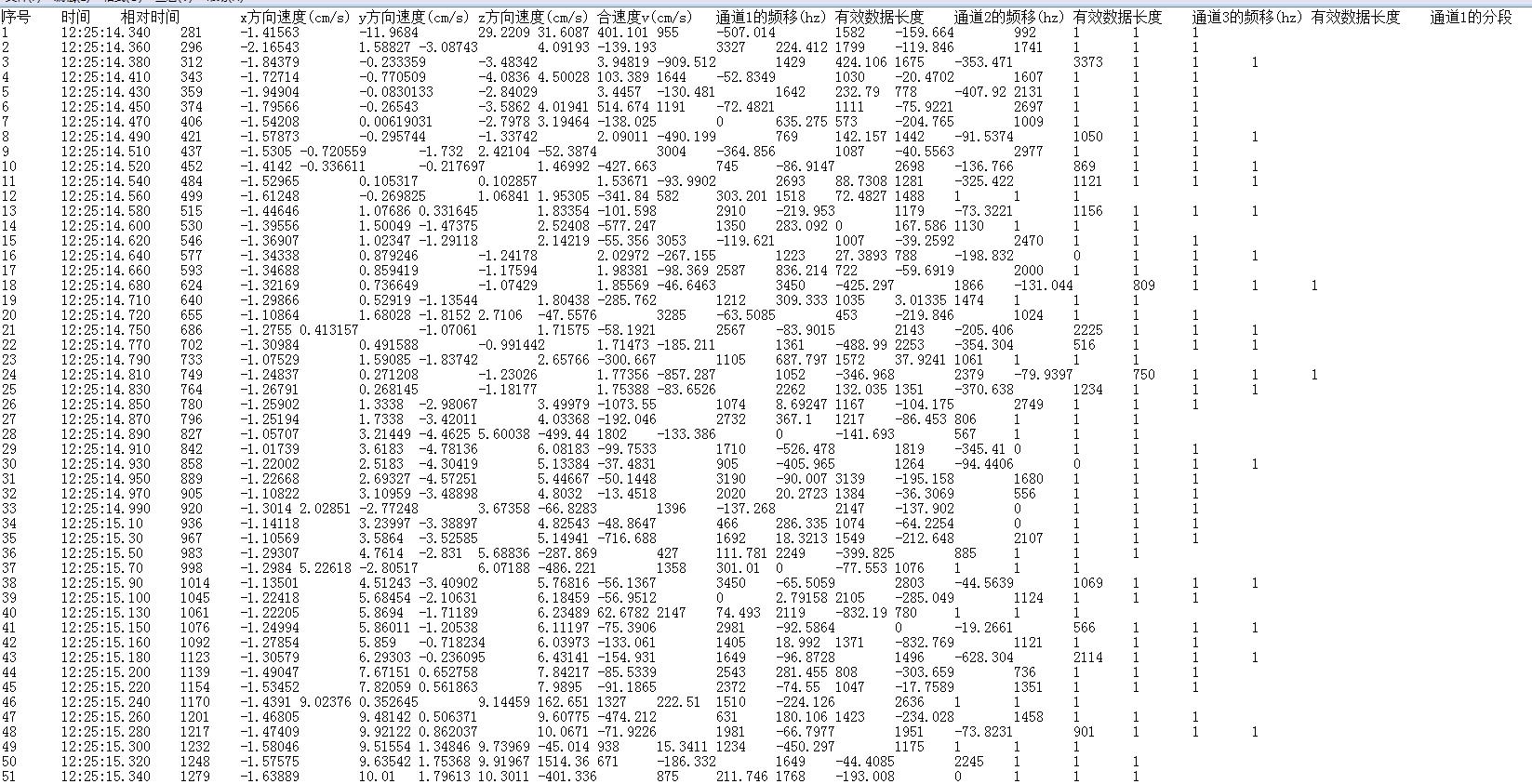
3.初步构思:
1.首先读取目录下的所有子目录
2.循环子目录,并遍历子目录下的子目录,循环反复,直到根目录。
3.数据处理可以直接txt读取,或导入至excel当中,只保留有效数据。
4.对数据进行公式计算,并将最终结果导出至新的excel中。
准备知识
1.目录及文档操作:
取得当前目录——os.getcwd()
#获取当前目录 path = os.getcwd() print(path)
判断一个路径是否存在,获取目录下的文件及目录
#判断一个路径(目录或文件)是否存在
print(os.path.exists(path))
#获取目录中的文件及子目录的列表——os.listdir("路径")
path = os.listdir(\'d:\\\\\')
print(path)
只获取目录下的子目录实例
def getDirList( path ):
path = str( path )
#是否为空
if path == "" :
return [ ]
#换成标准斜杠
path = path.replace( "/","\\\\")
if path[-1] != "\\\\":
path = path + "\\\\"
dir_result = os.listdir( path )
dir = [ x for x in dir_result if os.path.isdir( path + x )]
return dir
以上是关于使用python处理实验数据-yechen_pro_20171231的主要内容,如果未能解决你的问题,请参考以下文章