mit6.s081 lab1:Unix Utilities
Posted dreamer-q
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mit6.s081 lab1:Unix Utilities相关的知识,希望对你有一定的参考价值。
1 sleep(easy)
要求:为 xv6实现 UNIX 程序睡眠; 睡眠需要暂停一段用户指定的时间。刻度是由 xv6内核定义的时间概念,即定时器芯片两次中断之间的时间。解决的程序应该在 user/sleep. c 文件中。
一些小提示:
- 查看user/中的其它程序,如echo.c,grep.c或rm.c,明白如何获取传递给程序的命令行参数。
- 如果用户忘记传入参数,程序应打印一条错误信息
- 命令行参数作为字符串传递,可以用atoi转换为整数(可参考ulib.c)
- 需要使用系统调用sleep
- user/user.h头文件中包含了sleep的C定义
- 确保调用exit来退出程序
- 完成解答后应将你的 sleep 程序添加到 Makefile 的 uPROGS 中,这样使用make qemu 才会编译你的程序,以后就可以在 xv6 shell 中运行它了。
- 运行
./grade-lab-util sleep来测试你的程序
解决:
#include "kernel/types.h"
#include "user/user.h"
int
main(int argc, char *argv[])
if(argc <= 1)
fprintf(2, "sleep required the arguements\\n");
exit(1);
sleep(atoi(argv[1]));
exit(0);
对以上程序的说明:
- main的参数列表中,argc表示命令行中传入的参数个数,argv数组则是以字符串形式保存传入的参数,默认传入的第一个参数为文件本身
- fprintf指定输出到一个流文件中,函数原型为int fprintf( FILE *stream, const char *format, [ argument ]...),fprintf()函数根据指定的格式(format),向输出流(stream)写入数据(argument)。这里将错误通过fd2写入屏幕中的stderr。或者也可以使用write函数来打印错误信息,毕竟fprintf函数最终也是要通过系统调用write的。形式为write(int fd, char *buf, int n),参数 fd 是文件描述符,0 表示标准输入,1 表示标准输出,2 表示标准错误。参数 buf 是程序中存放写的数据的字符数组。参数 n 是要传输的字节数,调用 user/ulib.c 的 strlen() 函数就可以获取字符串长度字节数。
2 pingpong(easy)
要求:编写一个程序,使用 UNIX 系统调用通过一对管道在两个进程之间“ ping-pong”一个字节,每个管道对应一个方向。父级应该向子级发送一个字节; 子级应该打印“pid: received ping”,其中 < pid > 是它的进程 ID,将管道上的字节写入父级,然后退出; 父级应该从子级读取字节,打印“ pid: received pong”,然后退出。将解决方案写在 user/pingpong.c 文件中。
一些提示:
- 使用pipe来创建管道
- 使用fork创建子进程
- 使用read和write实现对管道的读和写
- 对于当前进程使用getpid来获得子进程的PID
- 在xv6中可使用的库函数有限,用户可以在user/user.h中看到这个列表;源代码(除系统调用外),位于ulib.c、printf.c和umalloc.c中。
解决:
#include "kernel/types.h"
#include "user/user.h"
#define READFD 0
#define WRITEFD 1
int
main(int argc,char *argv[])
int p1[2];//parent->child
int p2[2];//child->parent
char buf[1];
pipe(p1);
pipe(p2);
int pid;
pid=fork();
if(pid<0)
exit(1);
else if(pid==0)
close(p1[WRITEFD]);//完成使用文件的操作后应该关上以便后续使用
close(p2[READFD]);
read(p1[READFD],buf,1);
printf("%d: received ping\\n",getpid());
write(p2[WRITEFD],"6",1);
close(p1[READFD]);
close(p2[WRITEFD]);
exit(0);
else
close(p1[READFD]);
close(p2[WRITEFD]);
write(p1[WRITEFD],"6",1);
read(p2[READFD],buf,1);
printf("%d: received pong\\n",getpid());
close(p2[READFD]);
close(p1[WRITEFD]);
exit(0);
exit(0);
对以上程序的说明:
- 父进程中写-读-打印,子进程中读-打印-写
- 每次使用完文件后应及时关闭
- 管道是单向的,需要两个管道实现ping-pong,一个父->子,一个子->父
3 primes(moderate)
要求:使用管道编写一个基本筛选器的并发版本,将2-35的素数筛出来。程序应该使用pipe和fork来设置管道。第一个进程将数字2到35输入到管道中。对于每个素数,需要创建一个进程,该进程通过一个管道从左边的邻居读取数据,并通过另一个管道向右边的邻居写入数据。由于 xv6的文件描述符和进程数量有限,因此第一个进程的输入到35即可。相关提示文档在这里
一些提示:
- 注意关闭进程不需要的文件描述符,否则程序将在第一个进程达到35之前耗尽资源来运行xv6。
- 最开始的父进程要在所有子孙进程都退出之后才能退出。
- 当管道的写端关闭时,read返回0
- 最简单的方法是将32位int直接写入管道,而不是使用格式化的 ASCII I/O。
对帮助文档的说明:
里面大部分是讲历史和一些实验无关的东西,对于本实验的提示主要就是:首先将数字全部输入到最左边的管道,然后第一个进程打印出输入管道的第一个数 2 ,并将管道中所有 2 的倍数的数剔除。接着把剔除后的所有数字输入到右边的管道,然后第二个进程打印出从第一个进程中传入管道的第一个数 3 ,并将管道中所有 3 的倍数的数剔除。接着重复以上过程,最终打印出来的数都为素数。这个过程如下图所示:

实现:
#include "kernel/types.h"
#include "user/user.h"
#include "stddef.h"
#define READFD 0
#define WRITEFD 1
void
primes(int pp[])
int pr[2];
close(pp[WRITEFD]);
int first_prime;
if(read(pp[READFD],&first_prime,sizeof (int)))
printf("prime %d\\n",first_prime);
pipe(pr);//能从左边的管道读到再创建右边的
int pid=fork();
if(pid<0)
exit(1);
else if(pid>0)
int digit;
close(pr[READFD]);
while(read(pp[READFD],&digit,sizeof (int)))
if(digit%first_prime!=0)
write(pr[WRITEFD],&digit,sizeof (int));
close(pr[WRITEFD]);//所有数写完后就关掉这个文件
wait(NULL);
exit(0);
else
primes(pr);
else
exit(0);
int
main(int argc,char *argv[])
int p[2];
pipe(p);
int pid=fork();
if(pid<0)
exit(1);
else if(pid>0)
close(p[READFD]);
for(int i=2;i<=35;i++)
write(p[WRITEFD],&i,sizeof (int));
close(p[WRITEFD]);
wait(NULL);
else
primes(p);
exit(0);
对以上程序的说明:
- 设计思想不是很难,在main中首先创建一个管道,然后从父进程中把2-35传给子进程,从第一个子进程开始用函数primes递归去看每一个子进程。如果从左边的管道读到了值,第一个值就是我们要输出的素数,然后创建新的管道和子进程,并且把满足条件的数送入管道中,否则就直接退出子进程。
- 对于每一个父进程,都要用wait等待子孙进程全部退出后才能exit
- 注意每一次对文件描述符操作后都要记得用close关上
4 find(moderate)
要求:编写一个简单版本的 UNIX 查找程序: 查找指定目录下指定名称的文件。解决方案放在 user/find.c 文件中。
一些提示:
- 查看 user/ls.c 以了解如何读取目录。
- 使用递归的方式以实现find访问到子目录
- 不要循环递归“.”(当前目录)和“..”(父目录)
- 对文件系统的更改在 qemu 运行期间保持不变; 要获得一个干净的文件系统,先运行 make clean,然后使用 make qemu
- 关于C字符串的部分可以参考 《C程序设计语言》 例如第5.5节
- 注意不能像 Python 那样用 == 比较字符串,而是使用 strcmp ()
实现:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void
find(char *path,char *target)
char buf[512], *p;//buf放路径名,p就是个中间指针,用来各种操作
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0)
fprintf(2, "find: cannot open %s\\n", path);
return;
if(fstat(fd, &st) < 0)
fprintf(2, "find: cannot stat %s\\n", path);
close(fd);
return;
if(st.type!=T_DIR)
fprintf(2,"find: path is not a directory\\n");
close(fd);
exit(1);
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf)
//路径过长超出了缓冲区的长度
fprintf(2,"path is too long\\n");
close(fd);
exit(1);
strcpy(buf,path);//把path放到buf里
p=buf+ strlen(buf);
*(p++)=\'/\';//加上\'/\'变为绝对路径,从命令行读进来的时候只有路径名称
while(read(fd, &de, sizeof(de)) == sizeof(de))
if(de.inum==0) continue;
if(!strcmp(de.name,".")||!strcmp(de.name,".."))
continue;
memmove(p,de.name,DIRSIZ);//文件名复制给p
p[DIRSIZ]=0;//设置文件名结束符
if(stat(buf, &st) < 0)
printf("find: cannot stat %s\\n", buf);
continue;
if(st.type==T_DIR)
find(buf,target);
else if(st.type==T_FILE && !strcmp(de.name,target))
printf("%s\\n",buf);
close(fd);
int
main(int argc, char *argv[])
if(argc==3)
find(argv[1],argv[2]);
else
fprintf(2,"you need three arguments\\n");
exit(1);
exit(0);
对以上程序的补充:
- 整体设计思想参照ls的实现,在main函数中判断输入的参数是否满足条件,当输入参数不是三个的时候,报错并退出,否则调用find函数去找;
- 在find函数中,首先写退出条件:
如果open当前路径失败,直接退出;
open成功后进入给定的路径,调用stat读取文件描述符的状态信息复制给结构体st,复制失败,直接退出;
如果当前路径读到的(st.type)是文件属性,直接退出,因为我们的参数是在某个目录下找一个文件;
路径大小超过设置的文件名缓冲区大小,直接退出(ls中就对这一点进行了判断);
接着把绝对路径进行拷贝,循环获取路径下的文件名,与要查找的文件名进行比较,如果类型为文件且名称与要查找的文件名相同则输出路径,如果是目录类型则递归调用 find() 函数继续在这个目录下查找。 - strcmp(const char* str1, const char* str2)函数,比较str1和str2,str1>str2返回大于0的数,=返回0,<返回小于0的数
- fstat和stat都是用来获取相关文件状态信息的:
int fstat(int fd, struct stat *st),将文件描述符fd所指文件的状态信息复制给第二个参数,成功就返回0,否则返回-1;
int stat(const char *path, struct stat *st);与fstat的区别在于第一个参数的要求是文件全路径,而fstat需要的是open后得到的文件描述符fd,返回值的情况和fstat是一样的。
5 xargs(moderate)
要求:编写一个简单版本的 UNIX xargs 程序: 从标准输入中读取行,并为每一行运行一个命令,将该行作为参数提供给命令。解决方案应该在 user/xargs.c 文件中。
一些提示:
- 使用 fork 和 exec 在每行输入中调用命令。在父进程中使用 wait 等待子级完成命令
- 若要读取单个输入行,请一次读取一个字符,直到出现换行符(‘\\n’),标准输入最后是有一个回车的
- 如果你需要声明一个argv数组,kernel/param.h头文件中声明的MAXARG或许会有用
对几个概念的区分: - 命令:我们在命令行里输入的那一整行东西整体叫做命令
- 命令行参数:
mkdir a b c命令中的a b c是mkdir所接收的参数,cd a命令中a是cd所接收的参数。 - 标准化输入:我们输入一个命令后,等待我们继续输入的就是标准化输入,如
grep a就是当我们的输入和a有匹配的时候,打印该输入。 - 标准化输出:shell执行一个命令输出的东西
- 管道符
|:将符号前面命令的输入作为后面命令的命令行参数,如:
$ echo hello too | xargs echo bye
bye hello too
在这个命令中前一条命令打印出"hello too"来传给后一条命令,xargs在这里的作用是让它成为echo这条指令的命令行参数,于是最终的打印结果就是"bye hello too"如果不加xargs,那么"hello to"是要作为echo的标准化输入的。
实现:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h"
#include "stddef.h"
#define MAXSIZE 32
int
main(int argc,char *argv[])
sleep(10);
char buf[MAXSIZE];
read(0,buf,MAXSIZE);
char *argvs[MAXARG];
int ct=0;
for(int i=1;i<argc;i++)
argvs[ct++]=argv[i];
char *p=buf;
for(int i=0;i<MAXSIZE;i++)
if(buf[i]==\'\\n\')
int pid=fork();
if(pid==0)
//首先拼接参数列表
buf[i]=0;
argvs[ct++]=p;
exec(argvs[0],argvs);
exit(0);
else if(pid>0)
wait(NULL);
p=&buf[i+1];//子进程完成了第一行的输出,开始执行下一行了
exit(0);
对以上程序的补充:
- 根据实验目的,可以将xargs的实现分成三步:
1.用read把前一条命令的结果读出来并保存
2.把第二条命令的参数列表和前一条命令的结果合并
3.用exec加载第二条命令 - 加sleep(10)的原因是在测试
find . b | xargs grep hello的时候,find操作比较慢,以致于xargs在执行的时候还没有得到find的标准输出,加上sleep后就可以通过了。
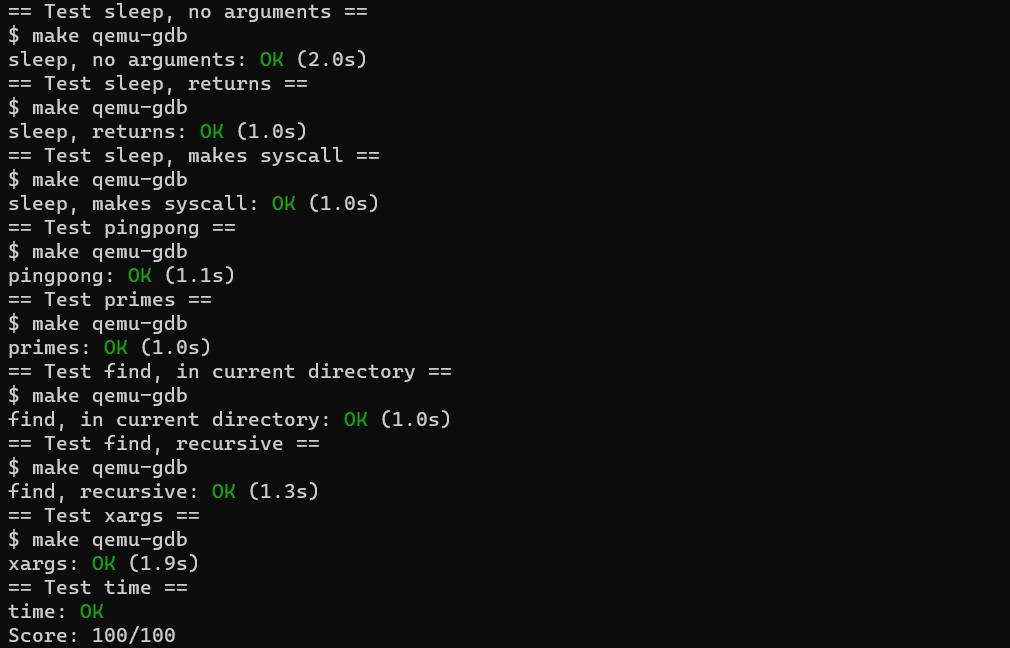
6 实验测试
注意要自己添加一个time.txt文件,记录你所花费的时间,不然最终的测评会在Cannot find time.txt那里扣一分
7 参考
text Espressioni Regolari Utili
以上是关于mit6.s081 lab1:Unix Utilities的主要内容,如果未能解决你的问题,请参考以下文章