python爬虫时,bs4无法读取网页标签中的文本?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫时,bs4无法读取网页标签中的文本?相关的知识,希望对你有一定的参考价值。
我在爬取虎扑的帖子作为作业,但是在爬取阅读量时出了问题。想爬的是下图的位置用beautifulsoup中的select爬取了下来并去除无用标签```browse=beautifulsoup.select('span.liulan')article = "browse":browse[0].text```得到的输出结果是空白然后尝试不去除标签直接输出beautifulsoup处理后的值,输出结果如下```[<span class="liulan"></span>]```为什么整个标签爬下来中间是空白的,是我爬取时定位错误了吗?还是我没有正确处理爬取下来的数据?求助!!!十分感谢!
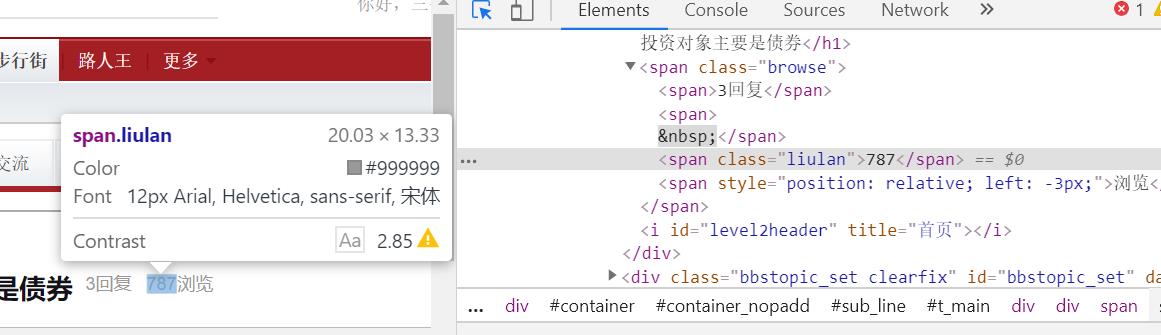
刚看了下虎扑的帖子。帖子的浏览量是动态加载的。并不是静态页面。所以常规的爬虫爬取的内容是空的。目前我了解的有两种方法可以去获取浏览量。一种是使用selenium + chrome。模拟浏览器加载。这种对于动态加载的页面比较有效。缺点就是效率太低。虎扑的帖子不建议使用(用不上)。另外一种就是找到虎扑获取浏览量的请求链接。看截图:
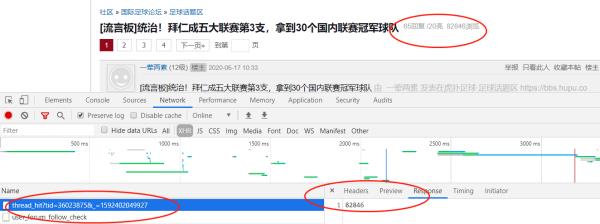
通过截图不难发现是通过图中的链接去获取的浏览量。该链接有两个参数。其中tid就是帖子的ID也就是每个帖子后面的ID。对比一下就发现了。最后的那个参数看起来很像是毫秒级的时间戳。在线验证一下如下图。

验证结果显示果然是时间戳(其实这个参数有没有都无所谓)。参数弄明白了就好办了直接将参数组合到该接口中去然后调用组合好的接口就可以了。是不是很简单~~~

希望可以帮到你,如有问题可以继续追问。谢谢
追问好详细!太感谢你了!
参考技术A 稍微说一下背景,当时我想研究蛋白质与小分子的复合物在空间三维结构上的一些规律,首先得有数据啊,数据从哪里来?就是从一个涵盖所有已经解析三维结构的蛋白质-小分子复合物的数据库里面下载。这时候,手动一个个去下显然是不可取的,我们需要写个脚本,能从特定的网站选择性得批量下载需要的信息。python是不错的选择。import urllib #python中用于获取网站的模块
import urllib2, cookielib
有些网站访问时需要cookie的,python处理cookie代码如下:
cj = ***.cookiejar ( )
opener = ***.build_opener( ***.httpcookieprocessor(cj) )
***.install_opener (opener)
通常我们需要在网站中搜索得到我们需要的信息,这里分为二种情况:
1. 第一种,直接改变网址就可以得到你想要搜索的页面:
def GetWebPage( x ): #我们定义一个获取页面的函数,x 是用于呈递你在页面中搜索的内容的参数
url = 'http://xxxxx/***.cgi?&' + ‘你想要搜索的参数’ # 结合自己页面情况适当修改
page = ***.urlopen(url)
pageContent = ***.read( )
return pageContent #返回的是HTML格式的页面信息
2.第二种,你需要用到post方法,将你搜索的内容放在postdata里面,然后返回你需要的页面
def GetWebPage( x ): #我们定义一个获取页面的函数,x 是用于呈递你在页面中搜索的内容的参数
url = 'http://xxxxx/xxx' #这个网址是你进入搜索界面的网址
postData = ***.urlencode( 各种‘post’参数输入 ) #这里面的post参数输入需要自己去查
req= ***.request (url, postData)
pageContent = ***.urlopen (req). read( )
return pageContent #返回的是HTML格式的页面信息
在获取了我们需要的网页信息之后,我们需要从获得的网页中进一步获取我们需要的信息,这里我推荐使用 BeautifulSoup 这个模块, python自带的没有,可以自行百度谷歌下载安装。 BeautifulSoup 翻译就是‘美味的汤’,你需要做的是从一锅汤里面找到你喜欢吃的东西。
import re # 正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent就是上面我们搜索得到的页面
soup就是 HTML 中所有的标签(tag)BeautifulSoup处理格式化后的字符串,一个标准的tag形式为:
hwkobe24
通过一些过滤方法,我们可以从soup中获取我们需要的信息:
(1) find_all ( name , attrs , recursive , text , **kwargs)
这里面,我们通过添加对标签的约束来获取需要的标签列表, 比如 ***.find_all ('p') 就是寻找名字为‘p’的 标签,而***.find_all (class = "tittle") 就是找到所有class属性为"tittle" 的标签,以及***.find_all ( class = ***.compile('lass')) 表示 class属性中包含‘lass’的所有标签,这里用到了正则表达式(可以自己学习一下,非常有用滴)
当我们获取了所有想要标签的列表之后,遍历这个列表,再获取标签中你需要的内容,通常我们需要标签中的文字部分,也就是网页中显示出来的文字,代码如下:
tagList = ***.find_all (class="tittle") #如果标签比较复杂,可以用多个过滤条件使过滤更加严格
for tag in tagList:
print ***.text
***.write ( str(***.text) ) #将这些信息写入本地文件中以后使用
(2)find( name , attrs , recursive , text , **kwargs )
它与 find_all( ) 方法唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果
(3)find_parents( ) find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点,孙子节点等. find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容
(4)find_next_siblings() find_next_sibling()
这2个方法通过 .next_siblings 属性对当 tag 的所有后面解析的兄弟 tag 节点进代, find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点
(5)find_previous_siblings() find_previous_sibling()
这2个方法通过 .previous_siblings 属性对当前 tag 的前面解析的兄弟 tag 节点进行迭代, find_previous_siblings()方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点
(6)find_all_next() find_next()
这2个方法通过 .next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这2个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous()方法返回第一个符合条件的节点
具体的使用方法还有很多,用到这里你应该可以解决大部分问题了,如果要更深入了解可以参考官方的使用说明哈!
python爬虫时,bs4无法读取网页标签中的文本
参考技术A 稍微说一下背景,当时我想研究蛋白质与小分子的复合物在空间三维结构上的一些规律,首先得有数据啊,数据从哪里来?就是从一个涵盖所有已经解析三维结构的蛋白质-小分子复合物的数据库里面下载。这时候,手动一个个去下显然是不可取的,我们需要写个脚本,能从特定的网站选择性得批量下载需要的信息。python是不错的选择。import urllib #python中用于获取网站的模块
import urllib2, cookielib
有些网站访问时需要cookie的,python处理cookie代码如下:
cj = ***.cookiejar ( )
opener = ***.build_opener( ***.httpcookieprocessor(cj) )
***.install_opener (opener)
通常我们需要在网站中搜索得到我们需要的信息,这里分为二种情况:
1. 第一种,直接改变网址就可以得到你想要搜索的页面:
def GetWebPage( x ): #我们定义一个获取页面的函数,x 是用于呈递你在页面中搜索的内容的参数
url = 'http://xxxxx/***.cgi?&' + ‘你想要搜索的参数’ # 结合自己页面情况适当修改
page = ***.urlopen(url)
pageContent = ***.read( )
return pageContent #返回的是HTML格式的页面信息
2.第二种,你需要用到post方法,将你搜索的内容放在postdata里面,然后返回你需要的页面
def GetWebPage( x ): #我们定义一个获取页面的函数,x 是用于呈递你在页面中搜索的内容的参数
url = 'http://xxxxx/xxx' #这个网址是你进入搜索界面的网址
postData = ***.urlencode( 各种‘post’参数输入 ) #这里面的post参数输入需要自己去查
req= ***.request (url, postData)
pageContent = ***.urlopen (req). read( )
return pageContent #返回的是HTML格式的页面信息
在获取了我们需要的网页信息之后,我们需要从获得的网页中进一步获取我们需要的信息,这里我推荐使用 BeautifulSoup 这个模块, python自带的没有,可以自行百度谷歌下载安装。 BeautifulSoup 翻译就是‘美味的汤’,你需要做的是从一锅汤里面找到你喜欢吃的东西。
import re # 正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent就是上面我们搜索得到的页面
soup就是 HTML 中所有的标签(tag)BeautifulSoup处理格式化后的字符串,一个标准的tag形式为:
hwkobe24
通过一些过滤方法,我们可以从soup中获取我们需要的信息:
(1) find_all ( name , attrs , recursive , text , **kwargs)
这里面,我们通过添加对标签的约束来获取需要的标签列表, 比如 ***.find_all ('p') 就是寻找名字为‘p’的 标签,而***.find_all (class = "tittle") 就是找到所有class属性为"tittle" 的标签,以及***.find_all ( class = ***.compile('lass')) 表示 class属性中包含‘lass’的所有标签,这里用到了正则表达式(可以自己学习一下,非常有用滴)
当我们获取了所有想要标签的列表之后,遍历这个列表,再获取标签中你需要的内容,通常我们需要标签中的文字部分,也就是网页中显示出来的文字,代码如下:
tagList = ***.find_all (class="tittle") #如果标签比较复杂,可以用多个过滤条件使过滤更加严格
for tag in tagList:
print ***.text
***.write ( str(***.text) ) #将这些信息写入本地文件中以后使用
(2)find( name , attrs , recursive , text , **kwargs )
它与 find_all( ) 方法唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果
(3)find_parents( ) find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点,孙子节点等. find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容
(4)find_next_siblings() find_next_sibling()
这2个方法通过 .next_siblings 属性对当 tag 的所有后面解析的兄弟 tag 节点进代, find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点
(5)find_previous_siblings() find_previous_sibling()
这2个方法通过 .previous_siblings 属性对当前 tag 的前面解析的兄弟 tag 节点进行迭代, find_previous_siblings()方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点
(6)find_all_next() find_next()
这2个方法通过 .next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这2个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous()方法返回第一个符合条件的节点
具体的使用方法还有很多,用到这里你应该可以解决大部分问题了,如果要更深入了解可以参考官方的使用说明哈!
以上是关于python爬虫时,bs4无法读取网页标签中的文本?的主要内容,如果未能解决你的问题,请参考以下文章