GaussDB(DWS)云原生数仓技术解析
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GaussDB(DWS)云原生数仓技术解析相关的知识,希望对你有一定的参考价值。
摘要:本文主要介绍GaussDB(DWS)云原生数仓架构、产品能力,帮助开发者快速了解GaussDB(DWS)云原生数仓相关信息与能力。
本文分享自华为云社区《直播回顾 | GaussDB(DWS)云原生数仓技术解析》,作者:胡辣汤。
在本期《GaussDB(DWS)云原生数仓技术解析》的主题直播中,我们邀请到华为云EI DTSE技术布道师/华为云数仓GaussDB(DWS)云原生首席SE 王传廷,针对GaussDB(DWS)云原生数仓架构、产品能力,与开发者和伙伴朋友们展开交流互动,帮助开发者快速了解GaussDB(DWS)云原生数仓相关信息与能力。
数仓需求变化及技术架构演进
云计算时代,数据仓库的需求和技术架构也在不断地发生变化。数仓需求主要分为两类场景:
- 公有云场景,主要是指用户直接购买的公有云厂商的云服务。公有云用户的需求更多关注在产品成本、扩容灵活弹性、数据共享。
- 线下部署场景,这类场景可能是用户购买的硬件部署了一个软件,也可能是用户在机房搭建了内部私有云环境。线下部署场景主要需求是:系统稳定、负载之间有较好的隔离能力、数据共享、弹性。
数仓技术架构演进由最初Shared Storage共享存储到Shared Nothing分布式计算架构再到现在的存算分离架构。
- 存算分离架构特点:存储类似shared storage,计算类似shared nothing,每个节点只处理自己分片的数据。
- 存算分离架构优点:计算存储分层扩展,计算节点扩容无需数据重分布,速度快,灵活;存储节点按需扩容,无限容量;计算节点之间无需协调机制,只需保证计算节点只处理自己分片的数据。

GaussDB(DWS)云原生数仓架构解析
华为云GaussDB(DWS)历经12年技术演进,2011年开始技术预研,2014年首次上市,通过不停地迭代和演进,从2017年开始大规模商用,当前全球已累积1700+大客户。针对数仓发展趋势,GaussDB(DWS)也在不断地演进,2022年推出实时数仓、IoT数仓,应对实时数据的接入,满足实时计算场景需求。2023年即将发布的云原生数仓,支持存算管三层分离、湖仓一体、数智融合,具备优异性能和极致弹性能力。
GaussDB(DWS)云原生数仓产品能力
一、极致弹性
GaussDB(DWS)云原生数仓极致弹性,具备管理层、计算层、存储层三层分离独立灵活伸缩,一数多用、按需配置优势。
存算管三层分离:存储层,支持私有格式和开放格式,开放格式主要支持ORC/Parquet/Hudi等大数据生态的主流格式。私有格式是GaussDB(DWS)的存储格式,数据存储在OBS上,在私有格式上具备更好的性能。计算层,我们抽象了Virtual Warehouse概念(简称VW),也叫逻辑集群。VW是一组计算单元,可以灵活地添加或者释放,数据不属于任何一个VW,仅仅只是绑定关系。管理层是指将集群管理查询优化与GaussDB(DWS)数据节点和GTM层体现出来。
一数多用:数据存储在OBS上,任意逻辑集群均可承载读写负载,多逻辑集群间共享数据,无需拷贝,提供跨逻辑集群建的实时和近实时两种数据共享方式。
按需配置:通过逻辑集群隔离不同业务,性能稳定,业务承载量或并发量线性扩展,可以进行读写分离或多读多写。
二、湖仓一体
之前使用大数据写数据,需要创建外表,指定外表字段,并与大数据字段对应,需要访问多少张表,就创建多少张表,当外表数量只有一两张时维护也比较容易,外表越来越多时,维护成本也随之增加,如果数据湖中字段发生了变化,外表也需要更改。GaussDB(DWS)云原生数仓在湖仓一体方面做了能力增强,降低维护成本。在这里我们引入新的概念External Schema。我们通过创建一个 External Schema的形式,自动对接Hive Metastore元数据管理,直接访问数据湖的数据表定义,不再需要创建外表,提升体验,降低维护代价。
同时我们支持外表和内表进行融合查询,混合查询数据湖和数仓内任意数据,查询一步到位输出到数仓内/数据湖,无需额外数据中转拷贝,数据湖享受数仓的极致查询性能。
三、数智融合
打通数据仓库与AI生产线,通过OBS共享开放格式数据,为AI生产线提供强劲的数据处理能力和灵活的供数方式。提供SQL语法,在数据分析过程中提供驱动AI训练、应用AI推理的能力。直接调用部署的推理服务端点,灵活性好;将模型二进制部署为UDF,性能好。
四、优异性能
存算分离后,我们通过三个方面保证数仓性能,分别是:缓存、近数据计算(计算下推)、IO调度。
- 缓存:将热数据优先缓存到本地,本地磁盘缓存空间够用的情况下,可以体验到和本地表一样的性能。GaussDB(DWS)在每个计算节点自带磁盘缓存,可以将OBS的数据缓存到本地,提升性能。
- 近数据计算:将冷数据优先计算下推到存储层,降低读取数据量。
- IO调度:充分利用云存储带宽优势,弥补其相较传统MPP的高延迟劣势;单查询充分利用资源,为并发查询提供稳定、可预测的性能保证;多级资源池灵活配置。
欢迎感兴趣的开发者观看直播回放,了解详细信息。更多关于GaussDB(DWS)产品技术解析、云原生数仓产品新特性的介绍,请关注GaussDB(DWS)论坛,直播安排将第一时间发布在GaussDB(DWS)论坛热门活动版块。
论坛链接:https://bbs.huaweicloud.com/forum/forum-598-1.html
解析数仓lazyagg查询重写优化
摘要:本文对Lazy Agg查询重写优化和GaussDB(DWS)提供的Lazy Agg重写规则进行介绍。
本文分享自华为云社区《GaussDB(DWS) lazyagg查询重写优化解析【这次高斯不是数学家】》,作者: OreoreO 。
聚集操作将查询结果按某一列或多列的值分组,值相等的为一组。聚集操作是一种常见的操作并在金融客户中有广泛的使用。例如如下语句:
SELECT a, count(a) FROM t1 GROUP BY a; -- 按a分组并计算分组内重复值的个数一、Lazy Agg重写规则
数据量大的场景下,聚集运算由于数据量大导致下盘,聚集操作执行时间成为性能瓶颈,从而导致整个查询执行效率非常差。例如:
SELECT t2.b, sum(cc) FROM (SELECT b, sum(c) AS cc FROM t1 GROUP BY b) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;子查询对t1.b列进行聚集,对t1.c列求和,在外部查询中,同样也存在聚集运算,对子查询的聚集求和列cc列求和。对于这类语句,当子查询的聚集运算较耗时的情况下,可以利用查询重写规则消除子查询的聚集运算,由外部查询的聚集函数统一完成聚集运算。消除子查询后可能导致子查询行数增多,但对于子查询聚集运算时t1.b列的distinct值较多的场景,子查询聚集运算后的行数较原表不会有明显缩减,不会导致外层JOIN运算量的大量增加。即语句可被重写为:
SELECT t2.b, sum(cc) FROM (SELECT b, c AS cc FROM t1) AS s, t2 WHERE s.b=t2.b GROUP BY t2.b;这个改写规则称为Lazy Agg,适用于基表数据量大且distinct值较多的场景。如果重复值较少,那么消除了聚集操作会导致Join后的行数激增,Join性能较差,因此需要将Agg下推到Join之前进行,通过提前的Agg操作减少Join结果的行数,这个改写规则称为Eager Agg。
二、GaussDB(DWS) lazyagg优化
为了降低调优难度,提升产品易用性,GaussDB(DWS)提供了lazyagg查询重写优化规则,可以通过设置guc参数rewrite_rule包含’lazyagg’使用Lazy Agg查询重写优化。开启lazyagg查询重写优化后,对满足条件的场景会优化并消除子查询中的聚集操作。原计划如下所示:

lazyagg重写优化后计划如下所示:
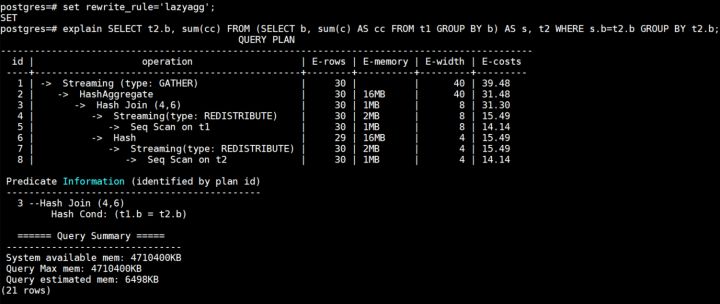
可以看到相比于原计划,lazyagg重写优化后消除掉了原计划中的聚集操作,即7号Subquery Scan算子和8号HashAggregate算子。
三、lazyagg优化规格
- 支持子查询为单一聚集查询或包含聚集子集合操作的查询。集合操作仅支持UNION ALL,可对部分分支子查询进行聚集运算消除。子查询需为JOIN表之一(不在TargetList、Where子句等其他位置)。
- 支持若外部查询的所有Agg参数列包含于其某个子查询的Agg函数列,则可对该子查询的聚集运算进行消除。
- 支持所有消除子查询聚集运算后结果正确的聚集函数种类。聚集函数种类结果正确性见下表:

4. 场景约束
在上述场景扩展的基础上,对于可能导致结果错误的场景,不进行查询重写,包括但不限于:
- 不支持消除的Agg函数类型。
- 子查询中包含其它条件或算子,会导致重写后结果错误,例如HAVING、window agg、LIMIT、OFFSET、AP function、distinct、recursive等。
- 外层Agg参数列、GROUP BY列或JOIN列中包含volatile函数,如random、timeofday等。
- 子查询Agg函数外、外部查询Agg函数内有其他表达式或函数操作,如子查询Agg函数列为sum©+1、max©+max(d),外部查询Agg函数列为sum(cc+1)等。
- 外部查询的JOIN列、GROUP BY列或其它条件中包含子查询Agg函数列。
- 子查询在LEFT JOIN、RIGHT JOIN的inner边或FULL JOIN中,且子查询Agg函数为count,外部查询Agg函数为sum的。
四、结语
通过本文的分析,相信用户朋友已经充分了解了Lazy Agg重写优化的使用场景,以及GaussDB(DWS)的lazyagg实现方式。希望广大用户能够通过深入的了解,对GaussDB(DWS)的性能调优产生浓厚的兴趣并深度参与进来。
参考文档:
GaussDB(DWS)性能调优系列实战篇四:十八般武艺之SQL改写
理论不如实践,那如何快速体验DWS呢?DWS现推出了一项Demo体验活动。进入DWS首页,点击“Demo体验”,快速便捷体验一把!(体验过程中有任何建议和意见,可以去DWS社区论坛反馈哦)
以上是关于GaussDB(DWS)云原生数仓技术解析的主要内容,如果未能解决你的问题,请参考以下文章